
Linux效能優化大師-系統原理漫談
目錄
整個系統是由多個不同部分組成的,每個部分都有可能出現問題,效能會受到不同部分的影響


程序管理
所有程序都通過task_struct結構體來管理的,一個程序描述符包含了單個程序在執行期間所有必要的資訊
如程序標識,程序屬性,構建程序的資源等


程序的生命週期
父程序fork出子程序,子程序呼叫exec將新的程式複製到子程序的地址空間,因為父子兩個程序共享相同的地址空間,所以新程式寫資料時會導致頁錯誤,核心會給子程序分配新的物理頁
這種延遲操作被稱為Copy On Write
子程序結束後呼叫exit結束程序,會釋放大部分資料併發送終止訊號給父程序,此時程序是殭屍程序zombie process,直到父程序通過waitpid呼叫得知子程序已經結束,並移除所有子程序的資料結構,釋放程序描述符

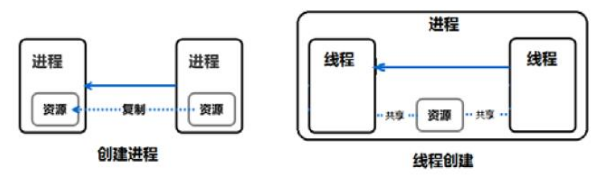
執行緒也被稱為輕量級程序Light Weight Process LWP
在Linux作業系統中有如下幾個執行緒實現
1.linuxThread,目前是預設的執行緒實現,但也有一些不富豪POSIX標準
2.Native POSIX Thread Library(NPTL),這個藉口更符合POSIX標準,增加了新的clone()系統呼叫,訊號處理
3.Next Generation POSIX Thread,由IBM開發的POSIX執行緒庫版本,目前處於維護狀態沒有下一步計劃
程序優先順序和nice
Linux支援的nice級別從最低的19,到最高的-20

上下文切換和中斷
執行的程序被載入到暫存器的資料集被稱為上下文context,在切換過程中,先儲存執行程序的上下文,然後將下一個要執行的程序的上下文恢復到暫存器。這個過程是上下文切換context switching,過多的上下文切換會頻繁的重新整理暫存器和快取記憶體cache,會導致效能問題
硬體/軟體中斷會將當期程序切換到一個新的程序處理這個中斷,也會導致上下文切換,過多的中斷會導致效能問題
/proc/interrupts 中可以看到硬體相關的中斷資訊

程序狀態,通過 man ps可以檢視到程序有如下一些狀態
PROCESS STATE CODES
Here are the different values that the s, stat and state output specifiers (header "STAT" or "S") will display to describe the state of a
process.
D Uninterruptible sleep (usually IO)
R Running or runnable (on run queue)
S Interruptible sleep (waiting for an event to complete)
T Stopped, either by a job control signal or because it is being traced.
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z Defunct ("zombie") process, terminated but not reaped by its parent.
For BSD formats and when the stat keyword is used, additional characters may be displayed:
< high-priority (not nice to other users)
N low-priority (nice to other users)
L has pages locked into memory (for real-time and custom IO)
s is a session leader
l is multi-threaded (using CLONE_THREAD, like NPTL pthreads do)
+ is in the foreground process group
殭屍程序,已經被認為是死亡的程序了,即使用kill -9也不能殺掉
父程序可以忽略SIGCHLD訊號,子程序退出後init程序會回收相關的資源
父程序忽略SIGCHLD訊號後,瞬間fork出1W個子程序,子程序都退出瞭然後父程序繼續sleep,再ps觀察發現子程序都沒了,說明都被init程序給回收了

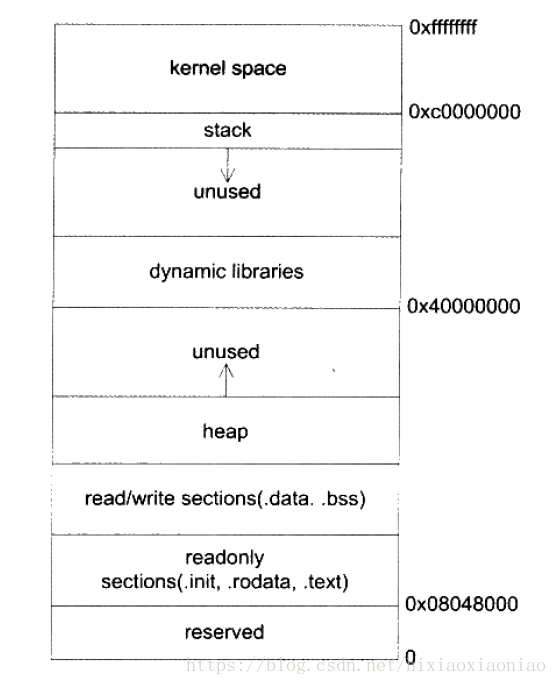
程序的記憶體段
作業系統核心對每個程序採用的是動態記憶體分配機制
文字段,用來儲存可執行程式碼的區域
資料段,這個段由三個區域組成
資料,儲存初始化資料,如靜態變數
BSS,儲存零初始化資料
堆,由malloc分配的記憶體,向高地址增長
棧段,在區域是區域性變數,函式引數,返回的儲存函式的存放區域,向低地址增長
中間一部分是動態連結庫
用 pmap 命令可以檢視程序的記憶體對映分佈
CPU排程程式
O(1)排程模型中,每個CPU使用2個佇列,一個執行佇列和一個過期佇列
排程程式根據他們的優先順序將他們放到執行佇列的程序列表中,需要排程時取出執行佇列彙總最高優先順序列表中的第一個程序並執行
排程程式基於程序的優先順序和以前的阻塞率給程序分配一個時間片,當程序時間片用完後,程序排程程式將其移動到過期佇列相應的優先順序列表中,然後再取下一個具有最高優先順序的程序,重複以上過程
一旦執行佇列中不再有程序等待,排程程式就將過期佇列轉變為新的執行佇列,之前的執行佇列成為新的過期佇列開始再次迴圈
新的排程程式支援非統一記憶體架構Non-Uniform Memory Architecture NUMA,和對稱多處理器SMP
2.6核心還支援完全公平排程Completely Fair Scheduler CFS,它基於虛擬時間的紅黑樹
虛擬時間是基於程序等待執行的時間,競爭CPU的程序數量以及程序的優先順序來計算的,一些病態的程序想傷害系統就很難了

記憶體體系結構
頁幀分配
核心以記憶體頁為單位處理記憶體,一個記憶體頁通常是4KB大小,當一個程序請求一定數量記憶體頁的時候,如果有有效的記憶體頁則核心分配給該程序
否則需要從其他程序或分頁快取中得到
程序不能直接訪問武力記憶體,只能訪問虛擬記憶體,一個程序分配記憶體時,頁幀的實體地址被對映到程序的虛擬地址
32位架構和64位架構的虛擬記憶體定址佈局

虛擬記憶體管理
應用程式向系統申請記憶體時,系統不會給應用程式分配實體記憶體,但會向核心請求一定大小的虛擬記憶體,並在虛擬記憶體中交換得到對映

夥伴系統
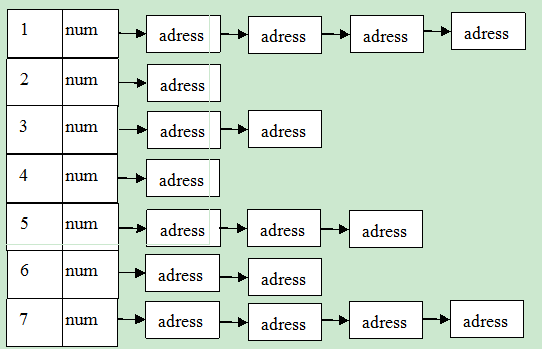
Linux中的記憶體管理的“頁”大小為4KB。把所有的空閒頁分組為11個塊連結串列,每個塊連結串列分別包含大小為1,2,4,8,16,32,64,128,256,512和1024個連續頁框的頁塊。最大可以申請1024個連續頁,對應4MB大小的連續記憶體。每個頁塊的第一個頁的實體地址是該塊大小的整數倍。
結構如圖所示:第i個塊連結串列中,num表示大小為(2^i)頁塊的數目,address表示大小為(2^i)頁塊的首地址。
從另一個視角看夥伴系統
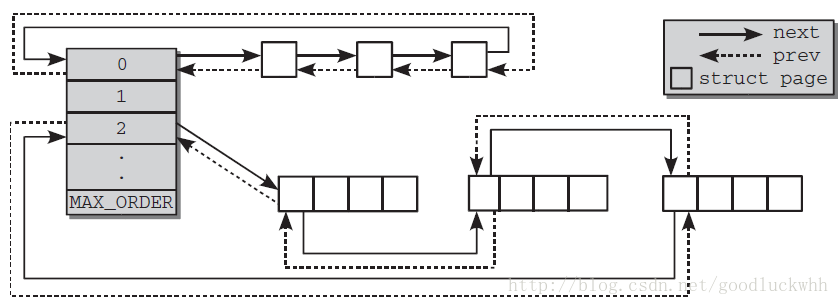
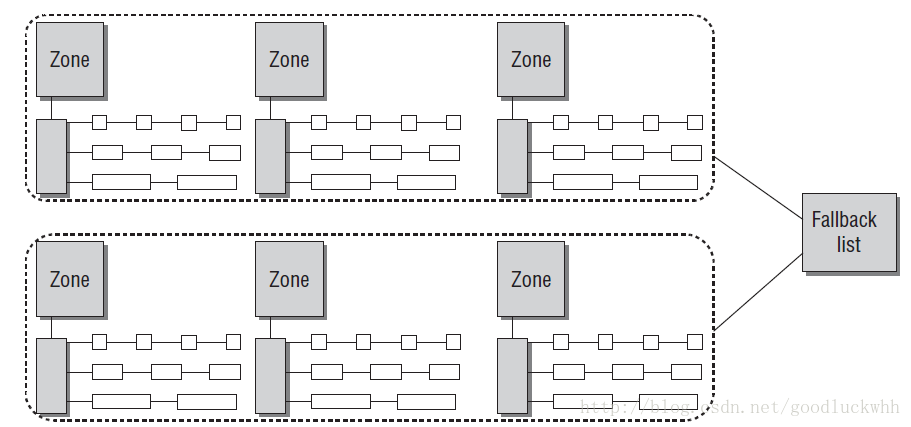
基於夥伴系統的記憶體管理方式專注於記憶體節點的某個記憶體域的管理,但是系統中的所有zone都會通過備用列表連線起來
系統中夥伴系統的當前資訊可以通過 /proc/buddyinfo 檢視
分頁回收
核心根據頁的可移動性將其劃分為3種不同的型別:
不可移動的頁:在記憶體中有固定位置,不能移動。分配給核心核心的頁大多是此種類型
可回收的頁:不能移動,但是可以刪除,其內容可以從某些源重新生成。
可移動的頁:可以隨意移動。屬於使用者程序的頁屬於這種型別,因為它們是通過頁表對映的,因而在移動後只需要更新使用者程序頁表即可
kswapd在任務中通常處於可中斷睡眠狀態,當區域中的空閒分頁低於一個閾值後使用LRU將這個頁釋放掉
kswapd掃描活躍頁列表,並堅持最近使用的分頁,將最近沒有使用的分頁放入非活躍頁列表中
通過 vmstat -a 命令檢視活躍和非活躍的記憶體多少
一些不常用的守護程序如 getty,可能會被放到swap,如果swap使用了50%頁不一定表明記憶體瓶頸,反而正面是核心在有效的利用系統資源
檔案系統
虛擬檔案系統VFS
虛擬檔案系統是駐留在使用者程序與各種型別的Linux檔案系統之間的一個抽象介面層
VFS提供了訪問檔案系統物件的通用物件模型,如索引節點,檔案物件,分頁快取,目錄條目等
它對使用者程序隱藏了實現每個檔案系統的差異,有了VFS使用者程序不需要知道系統使用的是哪一個檔案系統,為每個檔案系統執行哪一個系統呼叫

檔案系統日誌
對一個檔案執行執行寫操作時,核心首先改變檔案系統的元資料(metadata),然後再寫實際的使用者資料,這個操作有時候會損害數的完整性
在對元資料寫過程中如果系統崩潰了,則檔案系統的一致性會被破壞,fsck可以修復不一致並在下次重啟時恢復,但檔案系統太大就需要很長時間恢復
日誌檔案可以解決這個問題,先寫入日誌檔案再寫入系統檔案,這也會損失效能

Ext2
Ext2檔案系統以引導扇區開始,接下來是塊組,將整個檔案系統分成若干個小的塊組有助於提高效能,因為他可以將使用者資料的索引節點 i-node 表和資料塊更緊密的儲存在磁碟碟片上,因此可以減少尋道時間,一個塊組包含以下專案
1.超級快Super Block,檔案系統的資訊儲存在這裡,超級快的精確部分被防止在每個塊組的頂部
2.塊描述符Block group descriptor,塊組上的資訊被儲存在這裡
3.資料塊點陣圖Data block bitmaps,使用者空閒資料塊管理
4.索引節點點陣圖I-node bitmaps,用於空閒節點的管理
5.索引節點表I-node tables,索引節點表儲存在這裡,每個檔案有一個相應的索引節點表,其中儲存
了檔案的元資料,比如檔案模式,uid,gid,atime,ctime,mtime和到資料塊的指標
6.資料塊Data Block

要查詢/var/log/message過程
先查詢根目錄/,kernel會解析檔案路徑,搜尋/ 的目錄條目,該目錄條目中有他下面檔案和目錄的新興,接著找/var,然後是/var/log,最後找到message檔案
核心使用一個檔案物件快取,比如目錄條目快取或者索引節點快取來加速查詢符合條目的索引節點

Ext3
支援日誌功能,用 mount命令生命日誌的模式
通過tune2fs命令和編輯/etc/fstab檔案,可以將Ext2系統更新到Ext3檔案系統
日誌模式包含
1.全日誌journal,元資料和實際資料都被寫入日誌區,然後再寫入主檔案系統,但效率不高
2.順序ordered,元資料寫入到日誌區,再將元資料和實際資料寫入檔案系統
3.回寫writeback,將元資料寫入日誌區,實際資料寫入到主檔案系統中
Ext4相容Ext3,增加伸縮性,支援最大檔案系統為1024PB
使用區段提高了分配效能,線上磁碟碎片整理
其他檔案系統
XFS,Btrfs,JFS,ReiserFS
磁碟I/O子系統
磁碟執行寫入操作時的基本操作
1.一個程序通過write()系統呼叫請求寫一個檔案
2.核心更新已對映的分頁快取
3.核心執行緒pdfulsh/per-BDI flush將分頁快取重新整理到磁碟
4.檔案系統層同時在一個bio(block input outpu)結構中防止每個塊緩衝,並向塊裝置層提交寫請求
5.塊裝置層從上層得到請求,並執行一個I/O電梯操作,將請求放置到I/O請求佇列
6.裝置驅動器(如SCSI或其他裝置特定的驅動器)將執行寫操作
7.磁碟裝置韌體執行硬體操作,如在碟片扇區上定位磁頭,旋轉,資料傳輸

儲存器的層次結構

區域性性locality of reference
大多數最近使用過的資料,在不久將來有較高的機率被再次使用(時間區域性性)
駐留在資料附近的資料有較高的機率被再次使用(空間區域性性)

重新整理髒頁
程序首先在記憶體中改變資料,這時磁碟和記憶體中的資料是不相同的,並且記憶體中的資料被稱為髒頁dirty page,如果系統突然崩潰,則記憶體中的資料會丟失
同步髒資料緩衝的過程被稱為重新整理,2.6核心中Per-BDI flush執行緒檢查到當髒頁到達某個閾值時就會發生重新整理flush

塊層
塊層處理所有與塊裝置操作相關的活動
塊層中的關鍵資料結構是bio(block input outpu)結構,bio結構是在檔案系統層和塊層之間的一個介面
當執行寫的時候,檔案系統層試圖寫入由塊緩衝區構成的頁快取,它通過防止連續的塊在一起構成bio結構,然後將其傳送到塊層
塊層處理bio請求,並連結這些請求進入一個被稱為I/O請求的佇列,這個連結的操作被稱為I/O電梯排程器I/O elevator,有4種不同的排程演算法
1.CFQ complete Fair Queueing完全公平佇列,預設的I/O排程器
2.Deadline,迴圈電梯排程器round robin
3.NOOP
4.Anticipatory
I/O裝置驅動程式
核心使用裝置驅動程式得到裝置的控制權,裝置驅動程式通常是一個獨立的核心模組,他們通常針對每個裝置(或者裝置組)而提供,以便這些裝置在系統上可用,一旦載入了裝置驅動程式,它將被當做核心的一部分執行,並能控制裝置的執行
SCSI small Computer System Interface,小型計算機系統介面是最常使用的I/O裝置技術,尤其在企業級伺服器環境中,SCSI包含以下模組型別
1.Upeer level drivers上層驅動程式,sd_mod,sr_mod,st(SCSI Tape)和sq(SCSI通用裝置)
2.Middle level drivers中層驅動程式,如scsi_mod。其實現了SCSI協議和通用SCSI功能
3.Low level drivers底層驅動程式,其提供對每個裝置的較低級別訪問,底層驅動程式基本上是特定
於某一個硬體裝置的,可提供給某個裝置,如IBM ServerRAID controller的ips等
4.Pseudo drive偽驅動程式,如ide-scsi

磁碟條帶陣列RAID
需要考慮如下內容
1.檔案系統使用的塊大小,塊的大小指可以讀取/寫入到驅動器的最小資料量
2.計算檔案系統stride與stripe-width,如果檔案系統塊大小為4KB,則cheunk大小為64KB,則stride為64/4=16塊
建立檔案系統時可以使用mkfs給定數量
mke2fs -t ext4 -b 4096 -E stride=16,stripe-width=64 /dev/san/lun1
網路子系統
網路分層結構和網路操作
網路資料傳輸的基本操作
1.應用程式傳送資料到對等主機的時候,建立資料
2.呼叫socket函式,並寫入資料
3.socket緩衝區被用來處理傳輸資料,socket緩衝區引用資料,並向下穿過各層
4.在每一層中,執行適當的操作,比如解析報頭,新增和修改報頭,校驗和,路由操作,分片等,當
socket緩衝區向下穿過各層時,在各層之間的資料自身是不能夠複製的,因為在不同層之間複製實際
資料是無效的,核心僅通過改變在socket緩衝區中的引用來避免不必要的開銷並傳遞到下一層
5.網路介面卡向線纜傳送資料,當傳輸時增加一箇中斷
6.乙太網幀到大對等主機的網路介面卡
7.如果MAC地址匹配介面卡的MAC地址,將幀移動到網路介面卡的緩衝區
8.網路介面卡最終將資料包移動到一個socket緩衝區,併發出一個硬體中斷給CPU
9.CPU之後處理資料包,並使其向上穿過各層,直到它到達一個應用程式的TCP埠如Apache

socket buffer相關的引數調整
/proc/sys/net/core/rmem_max
/proc/sys/met/core/rmem/default
/proc/sys/net/core/wmem_max
/proc/sys/net/core/wmem_default
/proc/sys/net/ipv4/tcp_mem
/proc/sys/net/ipv4/tcp_rmem
/proc/sys/net/ipv4/tcp_wmemsocket緩衝區記憶體分配

傳統的方式每次一個匹配MAC地址的乙太網幀到達介面,都會產生一個硬體中斷,CPU每處理一個硬體中斷都要停止當前工作導致上下文切換,
引入NAPI後,對於第一個資料包還是跟傳統一樣觸發一次中斷,但之後介面就程序輪詢模式,只要有資料包放入網路介面的DMA環形緩衝區,不會引起中斷減少了上下文切換的開銷,等最後一個數據包處理完後緩衝區被清空,介面卡再次退回到中斷模式
Netfilter
核心的一個模組可以提供防火牆功能,包括
1.資料包過濾,滿足一定條件後就接受或拒絕該資料包
2.地址轉換,如果匹配則更改資料包
3.改變資料包,如果匹配則對資料包進行修改,如ttl,tos,mark等
可以通過以下屬性來匹配過濾器
網路介面,IP地址-IP地址範圍-子網,協議,ICMP協議,埠,TCP標誌,狀態
滿足條件後的目標行動有
1.ACCEPT
2.DROP
3.REJETC,通過傳送回一個錯誤資料包來響應匹配的資料包,如imcp-net-unreachable等
4.LOG,開啟核心日誌記錄匹配到資料
5.MASQUERADE,SNAT,DNAT,REDIRECT

TCP/IP的三次握手

TCP連線狀態圖

滑動視窗和延遲ACK

Offload
支援Offload的硬體,核心可以分出一部分給介面卡
checksum,IP/TCP/UDP執行校驗,通過比較協議頭部中的checksum欄位的值和計算資料包中的資料的
值,確保資料包被正確傳輸
TCP segmentation offload,TSO TCP分段offload,當大於支援的最大傳輸單元MTU資料傳送到網路
介面卡時,資料應該被分成MTU大小的資料包
Bonding模組
多個網絡卡使用同一個IP,提高叢集節點的資料傳輸
參考