
Faster RCNN(2)程式碼分析
目錄
執行程式碼
程式碼分析
執行程式碼
原作者的程式碼實現py-faster-rcnn,用的框架是caffe,由於對caffe不熟悉,所以在github上找了一個tensorflow版本的程式碼實現,地址是tf-faster-rcnn
在github上閱讀程式碼之前,肯定是要先讀一遍readme,根據作者寫的說明將程式碼執行起來,這樣也便於後面在程式碼中新增log來分析程式碼。
1.安裝環境
下載程式碼
git clone https://github.com/endernewton/tf-faster-rcnn.git保證除了tensorflow外還需要cython, opencv-python
easydict這三個包。
sudo pip install Cython
sudo pip install opencv-python
sudo pip install easydict根據自己的電腦配置來修改setup.py
cd tf-faster-rcnn/lib
vim setup.py比如根據我的電腦是GTX 1080 (Ti),所以修改了-arch為sm_61,具體的型號可以在README中檢視。
extra_compile_args={'gcc': ["-Wno-unused-function"], 'nvcc': ['-arch=sm_61', '--ptxas-options=-v', '-c', '--compiler-options', "'-fPIC'"]}, include_dirs = [numpy_include, CUDA['include']]
如果我們的訓練電腦只有CPU,那麼可以把./lib/model/config.py中的__C.USE_GPU_NMS = True改為False。
然後執行make編譯出gpu_nms.so和cpu_nms.so,這部分是原作者為nms做GPU加速而設計出來的程式碼。
2.準備資料
下載VOCdevkit
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar tar xvf VOCtrainval_06-Nov-2007.tar tar xvf VOCtest_06-Nov-2007.tar tar xvf VOCdevkit_08-Jun-2007.tar
建立軟連結
cd $FRCN_ROOT/data
ln -s $VOCdevkit VOCdevkit20073.下載Pre-trained Weights
./data/scripts/fetch_faster_rcnn_models.sh下載使用Resnet101網路對VOC07+12資料集訓練出來的weights。如果無法下載可以試試作者提供的google drive下載。
下載的檔案解壓後放在data目錄下,然後建立軟連結
NET=res101
TRAIN_IMDB=voc_2007_trainval+voc_2012_trainval
mkdir -p output/${NET}/${TRAIN_IMDB}
cd output/${NET}/${TRAIN_IMDB}
ln -s ../../../data/voc_2007_trainval+voc_2012_trainval ./default
cd ../../..我們準備的資料是VOC2007,而下載的weights是根據2007和2012進行訓練的,不過我們只是需要將流程跑通,不下載VOC2012關係不大。
4.執行demo和test
執行demo
GPU_ID=0
CUDA_VISIBLE_DEVICES=${GPU_ID} ./tools/demo.py可以看到對data/demo中的圖片都進行了預測。
執行test
GPU_ID=0
./experiments/scripts/test_faster_rcnn.sh $GPU_ID pascal_voc_0712 res101可以得到對每個類別預測的準確率
Saving cached annotations to /local/share/DeepLearning/stesha/tf-faster-rcnn-master/data/VOCdevkit2007/VOC2007/ImageSets/Main/test.txt_annots.pkl
AP for aeroplane = 0.8300
AP for bicycle = 0.8684
AP for bird = 0.8129
AP for boat = 0.7411
AP for bottle = 0.6853
AP for bus = 0.8764
AP for car = 0.8805
AP for cat = 0.8830
AP for chair = 0.6231
AP for cow = 0.8683
AP for diningtable = 0.7080
AP for dog = 0.8852
AP for horse = 0.8727
AP for motorbike = 0.8297
AP for person = 0.8272
AP for pottedplant = 0.5319
AP for sheep = 0.8115
AP for sofa = 0.7767
AP for train = 0.8461
AP for tvmonitor = 0.7938
Mean AP = 0.7976
~~~~~~~~
Results:
0.830
0.868
0.813
0.741
0.685
0.876
0.880
0.883
0.623
0.868
0.708
0.885
0.873
0.830
0.827
0.532
0.811
0.777
0.846
0.794
0.798
~~~~~~~~
5.訓練資料集
基於ImageNet的分類訓練的權重來訓練Faster RCNN,所以我們需要先下載ImageNet訓練權重
mkdir -p data/imagenet_weights
cd data/imagenet_weights
wget -v http://download.tensorflow.org/models/vgg_16_2016_08_28.tar.gz
tar -xzvf vgg_16_2016_08_28.tar.gz
mv vgg_16.ckpt vgg16.ckpt
cd ../..然後就可以訓練了,也可以將資料集替換成自己的資料進行訓練。
./experiments/scripts/train_faster_rcnn.sh 0 pascal_voc vgg16程式碼分析
模型訓練
1.配置和資料準備
當我們執行train_faster_rcnn.sh進行訓練時實際上是執行python ./tools/trainval_net.py並且傳入了一些引數。在trainval_net.py一開始會打印出所有引數
if __name__ == '__main__':
args = parse_args()
print('Called with args:')
print(args)
output:
Called with args:
Namespace(cfg_file='experiments/cfgs/vgg16.yml', imdb_name='voc_2007_trainval', imdbval_name='voc_2007_test', max_iters=70000, net='vgg16', set_cfgs=['ANCHOR_SCALES', '[8,16,32]', 'ANCHOR_RATIOS', '[0.5,1,2]', 'TRAIN.STEPSIZE', '[50000]'], tag=None, weight='data/imagenet_weights/vgg16.ckpt')
然後讀取cfg_file中的配置資訊放入config.py,整理set_cfgs中的資訊後也放入config.py。常用的配置資訊一開始已經放入config.py中了,這步操作相當於是增加了一些網路特有的配置資訊。程式碼如下
if args.cfg_file is not None:
cfg_from_file(args.cfg_file)
if args.set_cfgs is not None:
cfg_from_list(args.set_cfgs)接著準備imdb和roidb
imdb, roidb = combined_roidb(args.imdb_name)
print('{:d} roidb entries'.format(len(roidb)))imdb是imdb.py的類物件,便於後面使用imdb提供的方法。
roidb是通過_load_pascal_annotation解析xml檔案,獲取其中ground truth的boxes,gt_classes,gt_overlaps,flipped,seg_areas資訊。
boxes的shape是(len(objs), 4),表示圖片中每個元素有一組box資訊:xmin,xmax,ymin,ymax
gt_classes的shape是len(objs),圖片中每個元素有一個數字表示的類別資訊cls
gt_overlaps的shape是(len(objs), num_classes),圖片中每個類別有一個對應cls位置為1.0,其他位置都為0的矩陣。
flipped表示是原圖還是翻轉圖True或者False。
seg_areas的shape是len(objs),每個類別有一個矩陣面積。
然後在prepare_roidb函式的呼叫過程中還會增加一些資訊到roidb中:
image表示對應的image的路徑
width表示圖片的寬
height表示圖片的長
max_overlaps表示gt_overlaps每一行最大的值。因為是ground truth的最大值,所以都是1.0,比如一張圖片4個物體那麼max_overlaps的值為[1. 1. 1. 1.]
max_classes表示gt_overlaps每一行最大值的位置。其實就是一張圖片上每個物體的類別,比如一張圖片上4個物體,max_classes的值為[15 15 18 9]
下面設定output_dir
output_dir = get_output_dir(imdb, args.tag)
print('Output will be saved to `{:s}`'.format(output_dir))
#./tensorboard/vgg16/voc_2007_trainval/default再設定tensorboard路徑
#tensorboard/vgg16/voc_2007_trainval/default
tb_dir = get_output_tb_dir(imdb, args.tag)
print('TensorFlow summaries will be saved to `{:s}`'.format(tb_dir))用同樣的方式取出validation set的valroidb,但是不進行圖片的翻轉
orgflip = cfg.TRAIN.USE_FLIPPED
cfg.TRAIN.USE_FLIPPED = False
_, valroidb = combined_roidb(args.imdbval_name)
print('{:d} validation roidb entries'.format(len(valroidb)))
cfg.TRAIN.USE_FLIPPED = orgflip準備網路例項,以vgg16網路結構為例
net = vgg16()最後一步就是訓練網路,將前面準備的所有資料都傳入了train_net函式。
train_net(net, imdb, roidb, valroidb, output_dir, tb_dir,
pretrained_model=args.weight,
max_iters=args.max_iters)2.訓練網路train_net
對roidb和valroidb進行過濾,就是隻保留max_overlaps大於等於0.5(前景),或者小於0.5大於等於0.1(背景)的值。我想對於ground truth的roidb而言,應該只能去掉一些圖片中沒有任何標記的例子。
roidb = filter_roidb(roidb)
valroidb = filter_roidb(valroidb)建立SolverWrapper物件,將函式的引數都儲存在SolverWrapper內部,便於後面呼叫train_model的時候直接使用。
sw = SolverWrapper(sess, network, imdb, roidb, valroidb, output_dir, tb_dir,
pretrained_model=pretrained_model)然後進行訓練,max_iters是傳入的值為70000
sw.train_model(sess, max_iters)3.train_model
首先對roidb和valroidb初始化RoIDataLayer物件,並且呼叫_shuffle_roidb_inds打亂db index順序,比如roidb的長度是10022,所以RoIDataLayer內部儲存的self._perm是打亂[0, 1, 2, ......, 10019, 10020, 10021]這個陣列的順序的向量。另外因為cfg.TRAIN.ASPECT_GROUPING為False,所以呼叫的是np.random.permutation,這個方法和shuffle的區別是會返回一個打亂順序的陣列,但是不會改變原來的陣列。
self.data_layer = RoIDataLayer(self.roidb, self.imdb.num_classes)
self.data_layer_val = RoIDataLayer(self.valroidb, self.imdb.num_classes, random=True)接著呼叫construct_graph函式
lr, train_op = self.construct_graph(sess)在這個函式中呼叫了一個很重要的函式create_architecture,這個函式是搭建網路的核心,現在先跳過,後面重點分析這個函式。另外在construct_graph中取出了'total_loss',設定了learning_rate,指定了optimizer。
再回到train_model函式,接著判斷是否有可以restore的snapshot,如果有就恢復最後一個snapshot
# Find previous snapshots if there is any to restore from
lsf, nfiles, sfiles = self.find_previous()
# Initialize the variables or restore them from the last snapshot
if lsf == 0:
rate, last_snapshot_iter, stepsizes, np_paths, ss_paths = self.initialize(sess)
else:
rate, last_snapshot_iter, stepsizes, np_paths, ss_paths = self.restore(sess,
str(sfiles[-1]),
str(nfiles[-1]))如果呼叫initialize,其實會將ImageNet中訓練的vgg16的checkpoint恢復。恢復引數的程式碼在vgg16.py中的fix_variables函式中實現。
接著進入訓練的迴圈中,blobs是每次取出來的一個minibatch,因為data_layer中的self._perm是已經打亂過順序了,所以第一次取minibatch順序就是亂的。另外因為TRAIN.IMS_PER_BATCH為1,所以我們每次只取一個roidb的資料,對應一張圖片。
blobs = self.data_layer.forward() def forward(self):
"""Get blobs and copy them into this layer's top blob vector."""
blobs = self._get_next_minibatch()
return blobs具體準備blobs的程式碼在get_minibatch函式中實現,blobs的內容有三部分:
blobs['data']:是預處理後的圖片資料。1.圖片減去均值,2.短邊壓縮到600,如果壓縮後長邊大於1000,那麼長邊壓縮到1000
blobs['im_info']:三個數字,前兩個是壓縮後的圖片寬高,第三個是圖片的壓縮比例
blobs['gt_boxes']:shape是(len(objs), 5),5個數字中前4個是boxes資訊,第5個是對應obj的cls資訊,過濾掉了background這個類別的資料。
然後呼叫train_step進行訓練
# Compute the graph without summary
rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, total_loss = \
self.net.train_step(sess, blobs, train_op) def train_step(self, sess, blobs, train_op):
feed_dict = {self._image: blobs['data'], self._im_info: blobs['im_info'],
self._gt_boxes: blobs['gt_boxes']}
rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, loss, _ = sess.run([self._losses["rpn_cross_entropy"],
self._losses['rpn_loss_box'],
self._losses['cross_entropy'],
self._losses['loss_box'],
self._losses['total_loss'],
train_op],
feed_dict=feed_dict)
return rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, loss訓練是將rpn的loss和fast rcnn的loss相加作為total loss來進行優化的,跟論文中提到的交替訓練方式不太一樣。不過這樣會讓訓練更加的方便。
4.搭建網路create_architecture
前面跳過了create_architecture,現在再來分析這個函式。
首先建立了三個placeholder,對應我們從minibatch中取出來的blobs的三個資訊。因為傳入圖片的尺寸並不固定,所以self._image的長寬shape設定為None。
self._image = tf.placeholder(tf.float32, shape=[1, None, None, 3])
self._im_info = tf.placeholder(tf.float32, shape=[3])
self._gt_boxes = tf.placeholder(tf.float32, shape=[None, 5])然後初始化了一些引數,self._num_anchors表示每個中心點anchor的個數,是9個。
self._num_anchors = self._num_scales * self._num_ratios然後兩個關鍵的函式就是self._build_network和self._add_losses,將搭建網路的中間引數和建立的loss最後都放入layers_to_output中做為create_architecture函式的返回值。
先看_build_network,在這個函式的實現中也有兩個主要的部分,
1.呼叫_image_to_head,搭建了vgg網路,如果傳入的圖片尺寸是(1, 600, 800, 3),經過計算後成為(1, 38, 50, 512)
def _image_to_head(self, is_training, reuse=None):
with tf.variable_scope(self._scope, self._scope, reuse=reuse):
net = slim.repeat(self._image, 2, slim.conv2d, 64, [3, 3],
trainable=False, scope='conv1')
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3],
trainable=False, scope='conv2')
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool2')
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3],
trainable=is_training, scope='conv3')
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool3')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3],
trainable=is_training, scope='conv4')
net = slim.max_pool2d(net, [2, 2], padding='SAME', scope='pool4')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3],
trainable=is_training, scope='conv5')
self._act_summaries.append(net)
self._layers['head'] = net
return net2.呼叫self._anchor_component()
def _anchor_component(self):
with tf.variable_scope('ANCHOR_' + self._tag) as scope:
# just to get the shape right
# 用圖片原本的長寬除以16,得到的就是經過vgg運算後的feature map的尺寸
height = tf.to_int32(tf.ceil(self._im_info[0] / np.float32(self._feat_stride[0])))
width = tf.to_int32(tf.ceil(self._im_info[1] / np.float32(self._feat_stride[0])))
if cfg.USE_E2E_TF:
# 生成了相對原圖的所有anchors
anchors, anchor_length = generate_anchors_pre_tf(
height,
width,
self._feat_stride,
self._anchor_scales,
self._anchor_ratios
)
......關鍵函式是generate_anchors_pre_tf,這個函式的目的是生成相對原圖座標而言的所有anchors。以feature map的座標還原到原圖上的位置,然後以這些位置為中心點與相對尺寸的9個anchors相加,為每個中心點生成9個anchors。所以anchors的個數為38*50*9=17100,就是論文中說的,feature map的每個畫素點對應9個anchors。
def generate_anchors_pre_tf(height, width, feat_stride=16, anchor_scales=(8, 16, 32), anchor_ratios=(0.5, 1, 2)):
# 將feature map的橫向還原到原圖,並且間隔16設定一個點
shift_x = tf.range(width) * feat_stride # width
# 將feature map的縱向還原到原圖,並且間隔16設定一個點
shift_y = tf.range(height) * feat_stride # height
# 將x與y的座標對應起來,生成原圖上橫縱都間隔16的網格點座標sw和sy。
shift_x, shift_y = tf.meshgrid(shift_x, shift_y)
sx = tf.reshape(shift_x, shape=(-1,))
sy = tf.reshape(shift_y, shape=(-1,))
# sx和sy作為原圖框的起始座標和結束座標,因為起始座標和結束座標相同,所以其實[sx,sy,sx,sy]框是一個面積為0的點
shifts = tf.transpose(tf.stack([sx, sy, sx, sy]))
K = tf.multiply(width, height)
# shifts尺寸為(width*height, 1, 4)
shifts = tf.transpose(tf.reshape(shifts, shape=[1, K, 4]), perm=(1, 0, 2))
# 利用anchor_ratios和anchor_scales生成固定比例的框
# array([[ -83., -39., 100., 56.],
# [-175., -87., 192., 104.],
# [-359., -183., 376., 200.],
# [ -55., -55., 72., 72.],
# [-119., -119., 136., 136.],
# [-247., -247., 264., 264.],
# [ -35., -79., 52., 96.],
# [ -79., -167., 96., 184.],
# [-167., -343., 184., 360.]])
anchors = generate_anchors(ratios=np.array(anchor_ratios), scales=np.array(anchor_scales))
A = anchors.shape[0]
# anchor_constant尺寸為(1, 9, 4)
anchor_constant = tf.constant(anchors.reshape((1, A, 4)), dtype=tf.int32)
length = K * A
# (1, 9, 4) + (width*height, 1, 4),按照廣播原則相加得到的尺寸為(width*height, 9, 4),然後reshape成(width*height*9, 4),這就是相對原圖上的所有anchors
anchors_tf = tf.reshape(tf.add(anchor_constant, shifts), shape=(length, 4))
return tf.cast(anchors_tf, dtype=tf.float32), length3.呼叫self._region_proposal搭建rpn網路
def _region_proposal(self, net_conv, is_training, initializer):
rpn = slim.conv2d(net_conv, cfg.RPN_CHANNELS, [3, 3], trainable=is_training, weights_initializer=initializer,
scope="rpn_conv/3x3")
self._act_summaries.append(rpn)
rpn_cls_score = slim.conv2d(rpn, self._num_anchors * 2, [1, 1], trainable=is_training,
weights_initializer=initializer,
padding='VALID', activation_fn=None, scope='rpn_cls_score')
# change it so that the score has 2 as its channel size
rpn_cls_score_reshape = self._reshape_layer(rpn_cls_score, 2, 'rpn_cls_score_reshape')
rpn_cls_prob_reshape = self._softmax_layer(rpn_cls_score_reshape, "rpn_cls_prob_reshape")
rpn_cls_pred = tf.argmax(tf.reshape(rpn_cls_score_reshape, [-1, 2]), axis=1, name="rpn_cls_pred")
rpn_cls_prob = self._reshape_layer(rpn_cls_prob_reshape, self._num_anchors * 2, "rpn_cls_prob")
rpn_bbox_pred = slim.conv2d(rpn, self._num_anchors * 4, [1, 1], trainable=is_training,
weights_initializer=initializer,
padding='VALID', activation_fn=None, scope='rpn_bbox_pred')
if is_training:
rois, roi_scores = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
rpn_labels = self._anchor_target_layer(rpn_cls_score, "anchor")
# Try to have a deterministic order for the computing graph, for reproducibility
with tf.control_dependencies([rpn_labels]):
rois, _ = self._proposal_target_layer(rois, roi_scores, "rpn_rois")
......
self._predictions["rpn_cls_score"] = rpn_cls_score
self._predictions["rpn_cls_score_reshape"] = rpn_cls_score_reshape
self._predictions["rpn_cls_prob"] = rpn_cls_prob
self._predictions["rpn_cls_pred"] = rpn_cls_pred
self._predictions["rpn_bbox_pred"] = rpn_bbox_pred
self._predictions["rois"] = rois
return rois以feature map尺寸為(38, 50, 512)為例,下圖是這些變數之間的生成關係與尺寸。

裡面呼叫的三個比較重要的函式需要解說一下
# 由於計算出來的rpn_bbox_pred中的dx,dy,dw,dh都是相對anchor的偏移
# 所以這個函式就是相對anchors計算出來pred_boxes的座標,將超出範圍的pred_box進行裁剪
# 然後先取出分數排行前12000的scores和boxes,再用nms取出2000個boxes和對應的scroes
# 剩下proposals的shape是(2000, 4),返回的rois是對proposals第一列增加了一個數字全為0的列
# 所以rois的shape是(2000, 5),roi_scores的shape是(2000,)
rois, roi_scores = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")# 這個函式實際上是呼叫了anchor_target_layer函式
# anchor_target_layer函式的實現比較複雜,是為了生成四個返回值
# rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights
# 1.所有anchors中超出圖片範圍的剔除,生成在圖片內部的anchor列表,假設是5944個
# 2.建立labels向量,長度為5944,裡面的值預設全部設定為-1
# 3.計算每一個anchor與每一個gt_box之間的IOU,假設有4個gt_box,那麼生成的overlaps尺寸為(5944, 4)
# 4.每個anchor與4個gt_box之間的IOU取出最大值,如果最大值小於0.3,那麼這個anchor對應的label標記為0(負樣本)
# 5.每個anchor與4個gt_box之間的IOU取出最大值,如果最大值小於0.7,那麼這個anchor對應的label標記為1(正樣本)
# 6.為了防止最大值沒有大於0.7的情況,取出overlaps中列最大值,如果有相同的最大值也一起取出,對應的label標記為1
# 7. 篩選正負樣本,使它們的個數都不超過128個,沒有被篩選上的anchor對應的label標記為-1(不關心的值)
# 8. gt_boxes[argmax_overlaps, :]表示取gt_boxes的哪一組值來進行計算,是根據anchor跟哪一個box的IOU最大決定的
# 9. bbox_targets的資料是anchor相對gt_box的dx,dy,dw,dh,是偏移壓縮比例。(5944, 4)
# 10. bbox_inside_weights是(5944, 4)的全0矩陣,將label為1的位置的資料改為[1.0,1.0,1.0,1.0]
# 11. bbox_outside_weights是(5944, 4)的全0矩陣,將label為1和為0的位置的資料改為[0.00390625 0.00390625 0.00390625 0.00390625](用1除以正負樣本總和算出來的)
# 12. 把長度5944的label還原長度為17100的label,用-1來補新增位置的值
# 13. 把尺寸為(5944, 4)的bbox_targets,還原到尺寸為(17100, 4),用0來補新增位置的值
# 14. bbox_inside_weights和bbox_outside_weights同樣操作,尺寸都成為(17100, 4)
# 15. rpn_labels是對labels進行reshape,尺寸為(1, 1, 9*38, 50)
# 16. rpn_bbox_targets是對bbox_targets進行reshape,尺寸為(1, 38, 50, 36)
# 17. rpn_bbox_inside_weights和rpn_bbox_outside_weights同上一樣,尺寸為(1, 38, 50, 36)
rpn_labels = self._anchor_target_layer(rpn_cls_score, "anchor")# 這個函式實際上是呼叫了proposal_target_layer,然後呼叫_sample_rois
# 因為anchors已經準備了256個正負樣本參與計算,而proposal還是2000個,所以要進一步過濾proposal的個數
# 1.overlaps是計算出來的大約2000個proposal與gt_boxes之間的IOU,(2000, 4)
# 2.gt_assignment表示這2000個proposal跟哪個obj的overlap最大,(2000,)
# 3.labels = gt_boxes[gt_assignment, 4],gt_boxes的尺寸是(len(objs), 5),所以labels是每一個proposal對應的object的cls,(2000,)
# 4.fg_inds是最大IOU大於等於0.5的index,bg_inds是最大IOU大於等於0.1小於0.5的index
# 5.調整fg_inds和bg_inds,使他們的個數相加為rois_per_image(256)
# 6.保留labels中的fg_inds和bg_inds,(256,)
# 7.從fg_rois_per_image到結束是背景位置,設定label的值為0,而此時前景的label仍然是cls id
# 8.計算出proposal與gt_box的相對位移dx,dy,dw,dh,放入bbox_target_data並將label列放入第一列的位置,尺寸是(256, 5)
# 9.建立尺寸為(256, 84)的bbox_targets和bbox_inside_weights,84是因為有21個類,每個類留4個位置
# 經過計算後返回的rois尺寸為(256, 5)
rois, _ = self._proposal_target_layer(rois, roi_scores, "rpn_rois")4.呼叫_crop_pool_layer實現RoI Pooling層,因為proposal的尺寸各不相同,如果要送入region calssification會計算出問題,所以這裡將他們統一尺寸。原理上是將每個proposal對應到feature map上的位置,然後劃分成同樣的尺寸比如7*7,這樣在49個區域裡面進行max pooling,就可以將所有proposal轉成7x7的尺寸。最後的返回值是(256, 7, 7, 512)
5.呼叫_head_to_tail繼續構建網路,最後的fc7尺寸為(256, 4096)
def _head_to_tail(self, pool5, is_training, reuse=None):
with tf.variable_scope(self._scope, self._scope, reuse=reuse):
pool5_flat = slim.flatten(pool5, scope='flatten')
fc6 = slim.fully_connected(pool5_flat, 4096, scope='fc6')
if is_training:
fc6 = slim.dropout(fc6, keep_prob=0.5, is_training=True,
scope='dropout6')
fc7 = slim.fully_connected(fc6, 4096, scope='fc7')
if is_training:
fc7 = slim.dropout(fc7, keep_prob=0.5, is_training=True,
scope='dropout7')
return fc76.呼叫_region_classification搭建proposal的分類網路,cls_score的尺寸為(256, 21),cls_prob的尺寸為(256, 21),cls_pred的尺寸為(256,),bbox_pred的尺寸為(256, 84)
def _region_classification(self, fc7, is_training, initializer, initializer_bbox):
cls_score = slim.fully_connected(fc7, self._num_classes,
weights_initializer=initializer,
trainable=is_training,
activation_fn=None, scope='cls_score')
cls_prob = self._softmax_layer(cls_score, "cls_prob")
cls_pred = tf.argmax(cls_score, axis=1, name="cls_pred")
bbox_pred = slim.fully_connected(fc7, self._num_classes * 4,
weights_initializer=initializer_bbox,
trainable=is_training,
activation_fn=None, scope='bbox_pred')
self._predictions["cls_score"] = cls_score
self._predictions["cls_pred"] = cls_pred
self._predictions["cls_prob"] = cls_prob
self._predictions["bbox_pred"] = bbox_pred
return cls_prob, bbox_pred至此,_build_network的所有工作就完成了,返回值是rois, cls_prob, bbox_pred,但是還儲存了很多中間變數放在了self._predictions中。
再看_add_losses,
首先是RPN class loss,RPN的loss都是相對anchors來計算的。
# 是RPN網路中由feature map通過卷積計算生成的(1, 38, 50, 18)reshape得到的,尺寸是(9*38*50, 2)
rpn_cls_score = tf.reshape(self._predictions['rpn_cls_score_reshape'], [-1, 2])
# (9*38*50,)
rpn_label = tf.reshape(self._anchor_targets['rpn_labels'], [-1])
# 找出rpn_label中不為-1的部分,-1表示not care的資料
rpn_select = tf.where(tf.not_equal(rpn_label, -1))
# 根據rpn_select找出rpn_cls_score的對應位置
rpn_cls_score = tf.reshape(tf.gather(rpn_cls_score, rpn_select), [-1, 2])
# 根據rpn_select找出rpn_label的對應位置
rpn_label = tf.reshape(tf.gather(rpn_label, rpn_select), [-1])
# 計算cross entropy loss
rpn_cross_entropy = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(logits=rpn_cls_score, labels=rpn_label))其次是RPN bbox loss
# (1, 38, 50, 36)
rpn_bbox_pred = self._predictions['rpn_bbox_pred']
# (1, 38, 50, 36)
rpn_bbox_targets = self._anchor_targets['rpn_bbox_targets']
# (1, 38, 50, 36)
rpn_bbox_inside_weights = self._anchor_targets['rpn_bbox_inside_weights']
# (1, 38, 50, 36)
rpn_bbox_outside_weights = self._anchor_targets['rpn_bbox_outside_weights']
# l1 loss
rpn_loss_box = self._smooth_l1_loss(rpn_bbox_pred, rpn_bbox_targets, rpn_bbox_inside_weights,
rpn_bbox_outside_weights, sigma=sigma_rpn, dim=[1, 2, 3])接著是RCNN class loss,RCNN的loss都是相對proposal
# (256, 21)
cls_score = self._predictions["cls_score"]
# (256,)
label = tf.reshape(self._proposal_targets["labels"], [-1])
# cross entropy loss
cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=cls_score, labels=label))最後是RCNN bbox loss
# (256, 84)
bbox_pred = self._predictions['bbox_pred']
# (256, 84)
bbox_targets = self._proposal_targets['bbox_targets']
# (256, 84)
bbox_inside_weights = self._proposal_targets['bbox_inside_weights']
# (256, 84)
bbox_outside_weights = self._proposal_targets['bbox_outside_weights']
# l1 loss
loss_box = self._smooth_l1_loss(bbox_pred, bbox_targets, bbox_inside_weights, bbox_outside_weights)total_loss就是將以上4個loss相加,我們要優化的就是total_loss的值。
總結一下RPN和RCNN的loss:
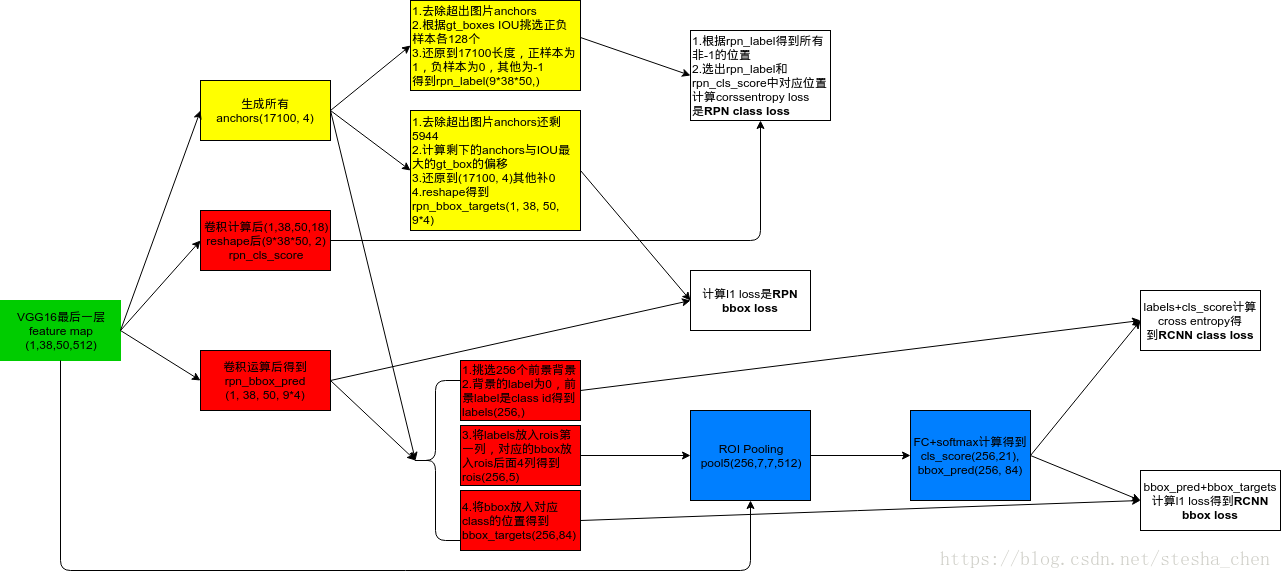
模型預測
1.demo.py
從demo.py入手看如何預測一張圖片。
當執行demo.py指令碼的時候,會執行main下面的程式碼。
主要是準備session,呼叫create_architecture構建網路,restore網路,呼叫demo預測
2.構建網路
函式create_architecture的實現主體和training時一樣,有以下幾個區別。
1.在構建網路的時候_region_proposal中只需要呼叫_proposal_layer,因為我們不需要構建loss,所以training中後面的步驟不需要。
if is_training:
rois, roi_scores = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
rpn_labels = self._anchor_target_layer(rpn_cls_score, "anchor")
# Try to have a deterministic order for the computing graph, for reproducibility
with tf.control_dependencies([rpn_labels]):
rois, _ = self._proposal_target_layer(rois, roi_scores, "rpn_rois")
else:
if cfg.TEST.MODE == 'nms':
rois, _ = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
elif cfg.TEST.MODE == 'top':
rois, _ = self._proposal_top_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
else:
raise NotImplementedError另外在_proposal_layer函式中,因為cfg_key為test,所以pre_nms_topN為6000,pos_nms_topN為300,因此我們的proposal有300個。
def proposal_layer(rpn_cls_prob, rpn_bbox_pred, im_info, cfg_key, _feat_stride, anchors, num_anchors):
......
pre_nms_topN = cfg[cfg_key].RPN_PRE_NMS_TOP_N
post_nms_topN = cfg[cfg_key].RPN_POST_NMS_TOP_N
nms_thresh = cfg[cfg_key].RPN_NMS_THRESH2.在create_architecture中需要對預測資料做處理
if testing:
stds = np.tile(np.array(cfg.TRAIN.BBOX_NORMALIZE_STDS), (self._num_classes))
means = np.tile(np.array(cfg.TRAIN.BBOX_NORMALIZE_MEANS), (self._num_classes))
self._predictions["bbox_pred"] *= stds
self._predictions["bbox_pred"] += means做這些處理是因為我們對target做過相反的處理
if cfg.TRAIN.BBOX_NORMALIZE_TARGETS_PRECOMPUTED:
# Optionally normalize targets by a precomputed mean and stdev
targets = ((targets - np.array(cfg.TRAIN.BBOX_NORMALIZE_MEANS))
/ np.array(cfg.TRAIN.BBOX_NORMALIZE_STDS))self._predictions["bbox_pred"]的尺寸是(300, 84),就是我們前面選出來的300個proposal。
3.demo函式
im_detect就是進行預測的主要程式碼,生成的scores shape是(300, 21),boxes的shape是(300, 84)
scores, boxes = im_detect(sess, net, im)然後對除了__background__以外的每個類別單獨分析
for cls_ind, cls in enumerate(CLASSES[1:]):
cls_ind += 1 # because we skipped background
#將對應class的box挑選出來,(300, 4)
cls_boxes = boxes[:, 4*cls_ind:4*(cls_ind + 1)]
#將對應class的分數挑選出來,(300, 1)
cls_scores = scores[:, cls_ind]
#合併成(300, 5)的資料score放在最後
dets = np.hstack((cls_boxes,
cls_scores[:, np.newaxis])).astype(np.float32)
#keep表示通過nms挑選出來的index,比如挑選出來30個
keep = nms(dets, NMS_THRESH)
#取出挑選出來的dets,(30, 5)
dets = dets[keep, :]
#將dets中score大於0.8的框保留下來畫在圖片上,這樣就拿到了bbox和score和class id
im = vis_detections(im, cls, dets, thresh=CONF_THRESH)4.im_detect預測
呼叫net.test_image進行預測
def test_image(self, sess, image, im_info):
feed_dict = {self._image: image,
self._im_info: im_info}
cls_score, cls_prob, bbox_pred, rois = sess.run([self._predictions["cls_score"],
self._predictions['cls_prob'],
self._predictions['bbox_pred'],
self._predictions['rois']],
feed_dict=feed_dict)
return cls_score, cls_prob, bbox_pred, rois然後再根據相對座標計算出真實座標
if cfg.TEST.BBOX_REG:
# Apply bounding-box regression deltas
box_deltas = bbox_pred
pred_boxes = bbox_transform_inv(boxes, box_deltas)
pred_boxes = _clip_boxes(pred_boxes, im.shape)預測完成。
以上為本文所有內容,感謝閱讀,歡迎留言。