
《STL原始碼剖析》筆記-hashtable
前面介紹了rb-tree是一種平衡二叉搜尋樹,它的操作具有"對數平均時間"的表現(O(log n)),並且需要在元素隨機的前提下。而hashtable(散列表)結構,在插入、刪除、搜尋等操作具有”常數平均時間”的表現(O(n)),但是需要以空間消耗為代價,相當於以空間換時間。
hashtable概述
hashtable支援對任何有名項的存取和刪除操作,所以也被視為字典結構。並且他的相關操作具有O(n)的時間複雜度,就像queue一樣。一般來說字典結構元素越多,查詢必定更加耗時,例如map。那麼,hashtable是怎麼實現常數時間的操作?下面是一個解釋的例子:
假設所有元素都是16bits且不帶正負號的整數,範圍0~65535,那麼簡單的使用一個array即可以滿足。 首先,配置一個array A,擁有65536個元素,索引號碼0~65535,初始值全部為0,每一個元素的值代表相應元素出現的次數。當插入元素i就執行A[i]++,刪除元素就執行A[i]–,如果搜尋元素i,就檢查A[i]是否為0。可以看到,以上每一個操作都是常數時間,不過需要負擔array的空間和初始化。
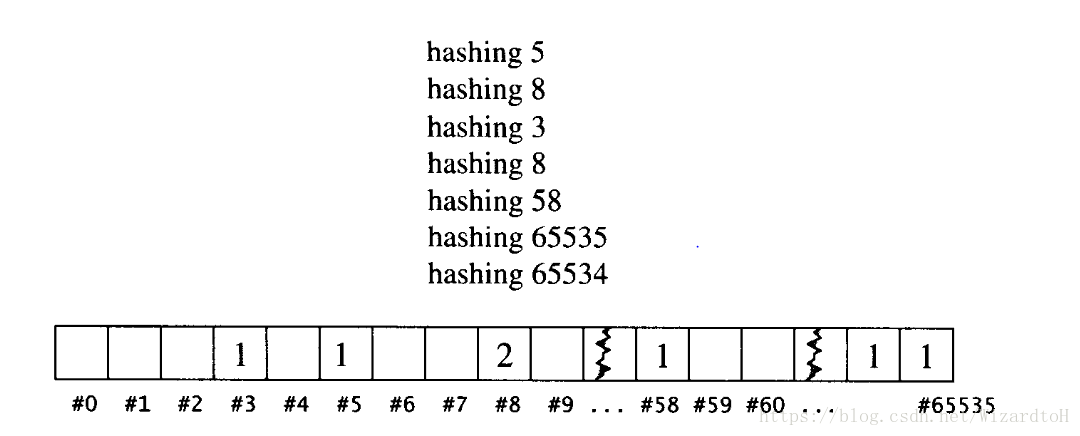
上述方法的確實現了O(n)的時間複雜度,但是存在兩個問題。一是元素大小如果是32bits或者更大,那麼需要的空間將非常非常大;二是隻對整數元素有效,無法滿足字串形式元素的需求。對於第二個問題,可以將字元編碼,轉換成數值例如ASCII碼,但是這樣產生的索引值同樣會非常大。這樣,最終的問題都歸結到了需要巨大的空間。
避免使用空間過大的解決方法是通過一個對映函式將大的數字對映為小的數值,這種函式被稱為hash function(雜湊函式)。不過,雜湊函式會有一個無法避免的問題,可能會有不同的元素被對映到了相同的位置,這就是碰撞問題。下面將介紹碰撞問題的幾種解決方法:
一、線性探測
線性探測方法,就是插入時用hash function計算出位置,如果位置上已經有元素,那麼就循序向後尋找空的位置,遇到結尾就跳到頭部開始尋找;查詢也是一樣,用hash function計算,如果目標不符就向後查詢;刪除需要使用軟刪除,就是隻刪除記號,因為hash table中的所有元素都關係到其他元素的排列,在hash table進行重新整理的時候再真正刪除。
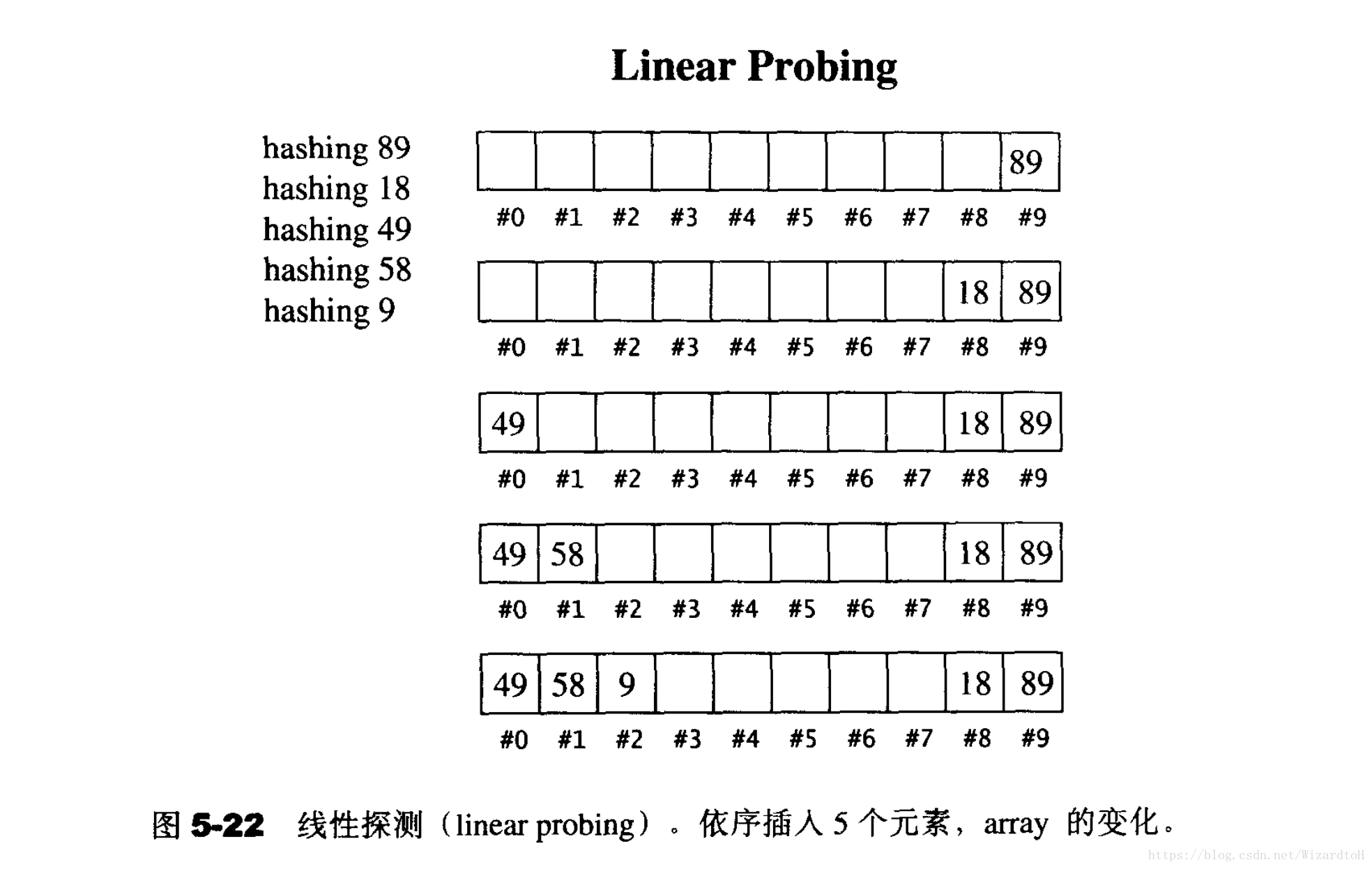
如上圖的例子,hash function是對10取餘,可以看到這種方法存在一些問題。在插入一系列元素後,散列表中的元素都擠在了一起,這種現象叫做主集團,如果後續插入的元素落在主集團中,插入效率就會越來越低,引起惡性迴圈。
二、二次探測
二次探測和線性探測的區別是,線性探測在發現計算位置被使用時是按照X+1、X+2…的方式進行嘗試,而二次探測則是X+12、X+22…。二次探測能解決線性探測的主集團的問題,但是也有一定可能會導致次集團,次集團的問題可以用double hashing(雙重雜湊)來避免,詳細內容可以參考https://www.cnblogs.com/wt869054461/p/5731577.html。
三、開鏈
前面的兩種方法都屬於開放定址法,因為都是在一個數組中存放資料,能夠直接定址。開鏈法的思路是將同一個hash值的元素都存放到一個list中,hash table中存放的是list的開始地址,每當元素計算的hash值重複時,就在list中加入一個元素。SGI STL採用的就是這種方法,此時SGI STL稱hash table中的元素為bucket,意思是它們不是單純的元素,而是儲存了一堆的元素。
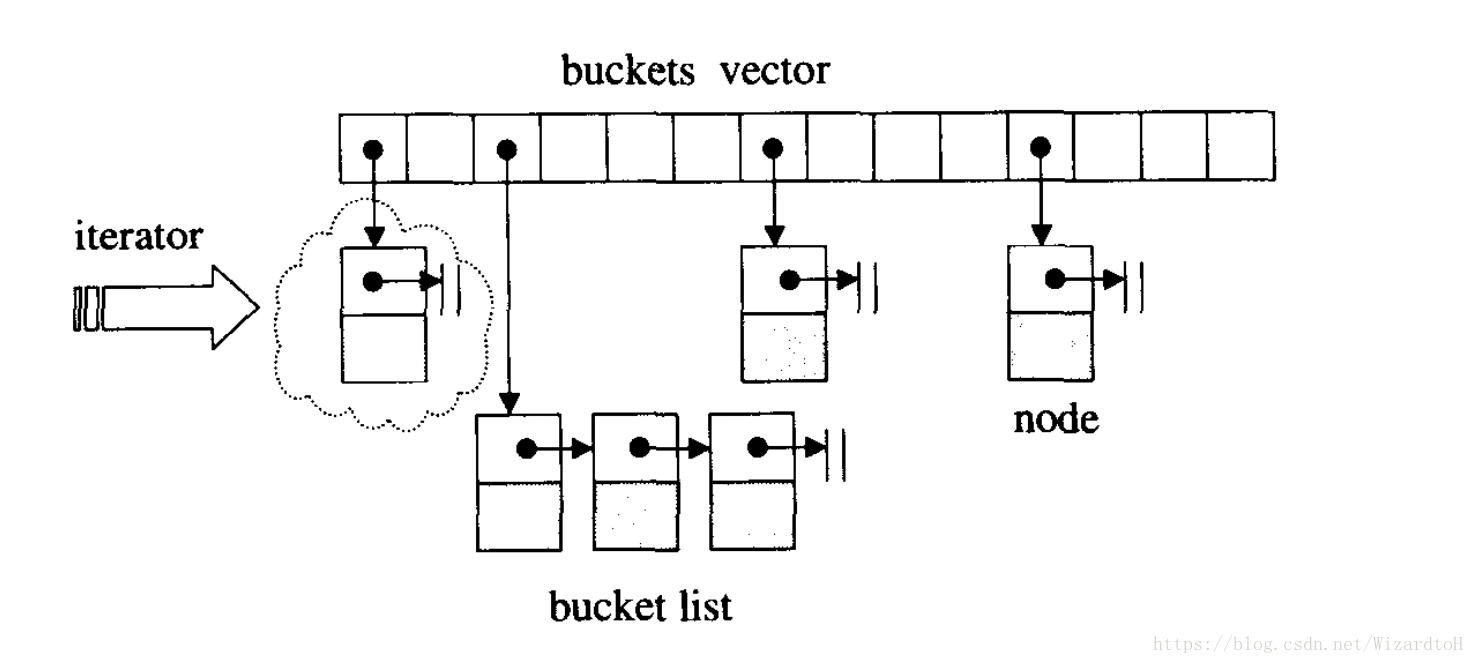
hashtable的節點定義
bucket中存放的節點定義如下:
template <class Value>
struct __hashtable_node
{
__hashtable_node* next;
Value val;
};
而bucket存放在hashtable定義的vector中,以便於擴充hashtable的容量。
hashtable的迭代器
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
struct __hashtable_iterator {
typedef hashtable<Value, Key, HashFcn, ExtractKey, EqualKey, Alloc>
hashtable;
typedef __hashtable_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
iterator;
typedef __hashtable_const_iterator<Value, Key, HashFcn,
ExtractKey, EqualKey, Alloc>
const_iterator;
typedef __hashtable_node<Value> node;
typedef forward_iterator_tag iterator_category;
typedef Value value_type;
typedef ptrdiff_t difference_type;
typedef size_t size_type;
typedef Value& reference;
typedef Value* pointer;
node* cur; // 當前節點
hashtable* ht; // 指向真個hashtable,用於在bucket之間跳轉
__hashtable_iterator(node* n, hashtable* tab) : cur(n), ht(tab) {}
__hashtable_iterator() {}
reference operator*() const { return cur->val; }
pointer operator->() const { return &(operator*()); }
iterator& operator++();
iterator operator++(int);
bool operator==(const iterator& it) const { return cur == it.cur; }
bool operator!=(const iterator& it) const { return cur != it.cur; }
};
// 字首自增
template <class V, class K, class HF, class ExK, class EqK, class A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>&
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++()
{
const node* old = cur;
cur = cur->next;
// bucket中的下一個節點為空,也就是說已經是尾部,需要跳轉到下一個有節點的bucket,如果接下來的bucket都為空,那麼就放回空
if (!cur) {
size_type bucket = ht->bkt_num(old->val);
while (!cur && ++bucket < ht->buckets.size())
cur = ht->buckets[bucket];
}
return *this;
}
// 字尾自增
template <class V, class K, class HF, class ExK, class EqK, class A>
inline __hashtable_iterator<V, K, HF, ExK, EqK, A>
__hashtable_iterator<V, K, HF, ExK, EqK, A>::operator++(int)
{
iterator tmp = *this;
++*this;
return tmp;
}
hashtable的資料結構
以下例舉了hashtable一部分定義。
template <class Value, class Key, class HashFcn,
class ExtractKey, class EqualKey, class Alloc>
class hashtable {
public:
// 為模板引數定義別名
typedef Key key_type;
typedef Value value_type;
typedef HashFcn hasher;
typedef EqualKey key_equal;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
typedef value_type* pointer;
typedef const value_type* const_pointer;
typedef value_type& reference;
typedef const value_type& const_reference;
hasher hash_funct() const { return hash; }
key_equal key_eq() const { return equals; }
private:
hasher hash;
key_equal equals;
ExtractKey get_key;
typedef __hashtable_node<Value> node;
typedef simple_alloc<node, Alloc> node_allocator;
vector<node*,Alloc> buckets; // 存放bucket的vector
size_type num_elements; // 元素的總數
...
};
可以看到hashtable中以vector作為bucket的容器,另外hashtable需要很多的模板引數:
- Value,節點實值的型別。
- Key,節點鍵值的型別。
- HashFcn,雜湊函式的型別。
- ExtractKey,從節點中取出鍵值的方法。
- EqualKey,判斷鍵值是否相等的方法。
- Alloc,空間配置器。
開鏈法並不需要hashtable的大小為質數,不過SGI STL中還是使用質數來作為hashtable的大小。並且,提供了一個函式用來計算最接近並大於某數的質數。
// 預定義了28個質數,並大致為兩倍關係
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473ul, 4294967291ul
};
inline unsigned long __stl_next_prime(unsigned long n)
{
const unsigned long* first = __stl_prime_list;
const unsigned long* last = __stl_prime_list + __stl_num_primes;
const unsigned long* pos = lower_bound(first, last, n);
return pos == last ? *(last - 1) : *pos;
}
// 最大bucket數量
size_type max_bucket_count() const
{ return __stl_prime_list[__stl_num_primes - 1]; }
hashtable的構造與記憶體管理 hashtable的記憶體管理預設使用std::alloc空間管理器,每次申請一個node大小的空間。
typedef simple_alloc<node, Alloc> node_allocator;
node* new_node(const value_type& obj)
{
node* n = node_allocator::allocate();
n->next = 0;
__STL_TRY {
construct(&n->val, obj);
return n;
}
__STL_UNWIND(node_allocator::deallocate(n));
}
void delete_node(node* n)
{
destroy(&n->val);
node_allocator::deallocate(n);
}
hashtable的不提供預設建構函式,
hashtable(size_type n,
const HashFcn& hf,
const EqualKey& eql,
const ExtractKey& ext)
: hash(hf), equals(eql), get_key(ext), num_elements(0)
{
initialize_buckets(n);
}
hashtable(size_type n,
const HashFcn& hf,
const EqualKey& eql)
: hash(hf), equals(eql), get_key(ExtractKey()), num_elements(0)
{
initialize_buckets(n);
}
size_type next_size(size_type n) const { return __stl_next_prime(n); }
// 如果構造時傳入50,那麼就會從預定義的質數列表中找到大於50的最小元素,也就是53.
void initialize_buckets(size_type n)
{
const size_type n_buckets = next_size(n);
buckets.reserve(n_buckets);
buckets.insert(buckets.end(), n_buckets, (node*) 0); // vector中所有bucket都是null
num_elements = 0;
}
插入操作和表格重整
插入操作首先需要判斷是否需要重整(resize),之後再進行插入:
pair<iterator, bool> insert_unique(const value_type& obj)
{
resize(num_elements + 1);
return insert_unique_noresize(obj);
}
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::resize(size_type num_elements_hint)
{
const size_type old_n = buckets.size();
// 用插入後元素的總數和buckets的大小進行比較,大於時需要resize
// 可以推論:buckets大小應該和hashtable中存放元素的最大數量一致
if (num_elements_hint > old_n) {
// 獲得下一個預定義的質數,如果已經最大就不進行resize
const size_type n = next_size(num_elements_hint);
if (n > old_n) {
vector<node*, A> tmp(n, (node*) 0); // 重新分配一個vector
__STL_TRY {
for (size_type bucket = 0; bucket < old_n; ++bucket) {
node* first = buckets[bucket]; // 指向bucket的第一個節點
while (first) {
size_type new_bucket = bkt_num(first->val, n); // 計算當前bucket中的節點在新的vector中的位置
buckets[bucket] = first->next; // 記錄下一節點
first->next = tmp[new_bucket]; // 將first的下一節點指向新bucket的第一個節點
tmp[new_bucket] = first; // 將舊bucket的節點放到了新bucket的頭部
first = buckets[bucket]; // first指向了下一節點,迴圈將舊bucket中的節點移到新的bucket
}
}
// 最後將舊vector用新的vector替換掉
buckets.swap(tmp);
}
}
}
}
// 插入不重複的值
template <class V, class K, class HF, class Ex, class Eq, class A>
pair<typename hashtable<V, K, HF, Ex, Eq, A>::iterator, bool>
hashtable<V, K, HF, Ex, Eq, A>::insert_unique_noresize(const value_type& obj)
{
const size_type n = bkt_num(obj); // 計算元素所屬bucket的位置
node* first = buckets[n];
// bucket中有相等鍵值的元素,返回失敗
// 此處發現一個問題:先resize可能導致無效的擴容,因為有可能插入鍵值重複,實際上是不需要擴容的
for (node* cur = first; cur; cur = cur->next)
if (equals(get_key(cur->val), get_key(obj)))
return pair<iterator, bool>(iterator(cur, this), false);
// 分配新節點,並插入到bucket頭部
node* tmp = new_node(obj);
tmp->next = first;
buckets[n] = tmp;
++num_elements;
return pair<iterator, bool>(iterator(tmp, this), true);
}
計算元素所屬位置(bkt_num)
bkt_num使用SGI STL統一的hash演算法(後續會進行介紹)計算出hash值再進行取餘,在計算hash值之前,需要先獲取元素的key值,這是因為存放的元素可能無法直接計算hash值,比如存放字串型別,此時就需要進行轉換。
size_type bkt_num_key(const key_type& key) const
{
return bkt_num_key(key, buckets.size());
}
size_type bkt_num(const value_type& obj) const
{
return bkt_num_key(get_key(obj));
}
size_type bkt_num_key(const key_type& key, size_t n) const
{
return hash(key) % n;
}
size_type bkt_num(const value_type& obj, size_t n) const
{
return bkt_num_key(get_key(obj), n);
}
複製和清除
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::clear()
{
// 先刪除所有bucket中的所有節點
for (size_type i = 0; i < buckets.size(); ++i) {
node* cur = buckets[i];
while (cur != 0) {
node* next = cur->next;
delete_node(cur);
cur = next;
}
// 將bucket指向null
buckets[i] = 0;
}
// 元素數量置為0
num_elements = 0;
// 此時hashtable的vector還是原來的大小,沒有進行清除
}
template <class V, class K, class HF, class Ex, class Eq, class A>
void hashtable<V, K, HF, Ex, Eq, A>::copy_from(const hashtable& ht)
{
buckets.clear(); // 先清空原有的vector
buckets.reserve(ht.buckets.size()); // 重新配置vector的最大大小
buckets.insert(buckets.end(), ht.buckets.size(), (node*) 0); // 所有bucket指向null
__STL_TRY {
for (size_type i = 0; i < ht.buckets.size(); ++i) {
if (const node* cur = ht.buckets[i]) {
// 配置節點空間並賦值
node* copy = new_node(cur->val);
buckets[i] = copy;
// 對bucket中的元素一一賦值,並建立指向關係
for (node* next = cur->next; next; cur = next, next = cur->next) {
copy->next = new_node(next->val);
copy = copy->next;
}
}
}
// 修改元素數量
num_elements = ht.num_elements;
}
__STL_UNWIND(clear());
}
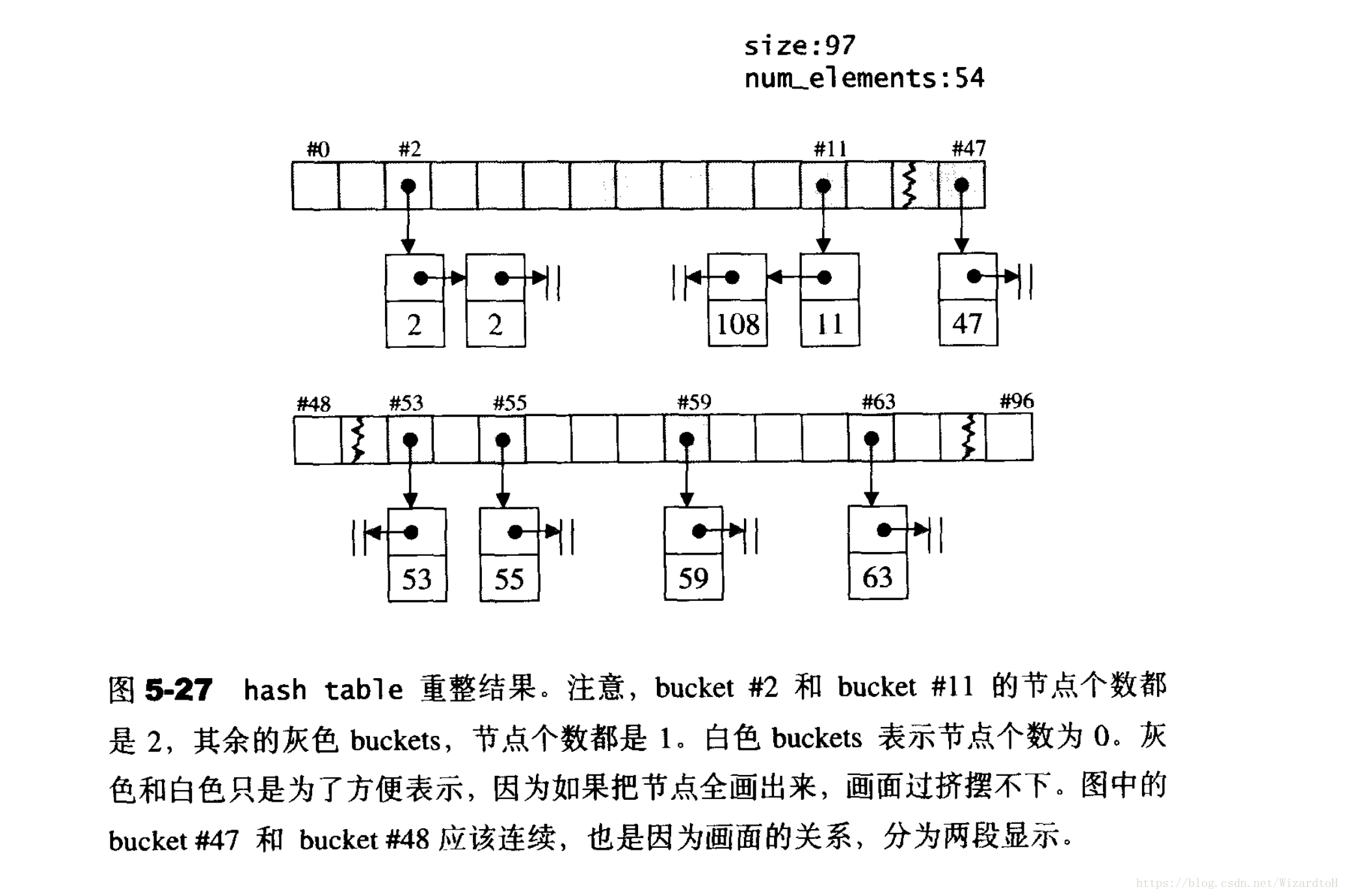
hashtable例項

再插入48個元素,使元素數量超過質數53,可以看到vector擴容到了下一個預定義的質數96。
hash functions
在介紹計算元素所屬位置函式時說到,對於char、int等整形,hash functions是能夠直接得出雜湊值的,但是對於字串型別需要進行轉換。stl_hash_fun.h中提供了一個轉換的方法:
// stl_hash_fun.h
template <class Key> struct hash { };
// 字串轉換成size_t
inline size_t __stl_hash_string(const char* s)
{
unsigned long h = 0;
for ( ; *s; ++s)
h = 5*h + *s;
return size_t(h);
}
__STL_TEMPLATE_NULL struct hash<char*>
{
size_t operator()(const char* s) const { return __stl_hash_string(s); }
};
__STL_TEMPLATE_NULL struct hash<const char*>
{
size_t operator()(const char* s) const { return __stl_hash_string(s); }
};
__STL_TEMPLATE_NULL struct hash<char> {
size_t operator()(char x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned char> {
size_t operator()(unsigned char x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<signed char> {
size_t operator()(unsigned char x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<short> {
size_t operator()(short x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned short> {
size_t operator()(unsigned short x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<int> {
size_t operator()(int x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned int> {
size_t operator()(unsigned int x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<long> {
size_t operator()(long x) const { return x; }
};
__STL_TEMPLATE_NULL struct hash<unsigned long> {
size_t operator()(unsigned long x) const { return x; }
};
而對於其他型別,比如string、double等,需要自定義對應的hash function來支援hash值的計算。