
Apache Storm 入門教程
1、瞭解Storm
1.1、什麼是Storm?
疑問:已經有了Hadoop,為什麼還要有Storm?
-
Storm是一個開源免費的分散式實時計算系統,Storm可以輕鬆的處理無界的資料流。
-
Storm有許多用例:實時分析、線上機器學習、連續計算、分散式RPC、ETL等等。Storm很快:每個節點每秒處理超過一百萬個條訊息。Storm是可擴充套件的、容錯的,保證您的資料將被處理,並且易於設定和操作。
-
Storm只負責資料的計算,不負責資料的儲存。
-
2013年前後,阿里巴巴基於storm框架,使用java語言開發了類似的流式計算框架佳作,Jstorm。2016年年底阿里巴巴將原始碼貢獻給了Apache storm,兩個專案開始合併,新的專案名字叫做storm2.x。阿里巴巴團隊專注flink開發。
1.2、流式計算的架構

2、Storm架構
2.1、Storm的核心技術組成

-
Topology(拓撲)
-
一個拓撲是一個圖的計算。使用者在一個拓撲的每個節點包含處理邏輯,節點之間的連線顯示資料應該如何在節點間傳遞。Topology的執行時很簡單的。
-
-
Stream(流)
-
流是Storm的核心抽象。一個流是一個無界Tuple序列,Tuple可以包含整型、長整型、短整型、位元組、字元、雙精度數、浮點數、布林值和位元組陣列。使用者可以通過自定義序列化器,在本機Tuple使用自定義型別。
-
-
Spout(噴口)
-
Spout是Topology流的來源。一般Spout從外部來源讀取Tuple,提交到Topology(如Kestrel佇列或Twitter API)。Spout可以分為可靠的和不可靠的兩種模式。Spout可以發出超過一個流。
-
-
Bolt(螺栓)
-
Topology中的所有資料的處理都在Bolt中完成。Bolt可以完成資料過濾、業務處理、連線運算、連線、訪問資料庫等操作。Bolt可以做簡單的流轉換,發出超過一個流,主要方法是execute方法。完全可以在Bolt中啟動新的執行緒做非同步處理。
-
-
Stream grouping(流分組)
-
流分組在Bolt的任務中定義流應該如何分割槽。
-
-
Task(任務)
-
每個Spout或Bolt在叢集中執行許多工。每個任務對應一個執行緒的執行,流分組定義如何從一個任務集到另一個任務集傳送Tuple。
-
-
worker(工作程序)
-
Topology跨一個或多個Worker節點的程序執行。每個Worker節點的程序是一個物理的JVM和Topology執行所有任務的一個子集。
-
2.2、Storm應用的程式設計模型

需要我們知道的是:
-
Spout是資料的來源;
-
Bolt是執行具體業務邏輯;
-
資料的流向,是可以任意組合的;
-
一個Topology是由若干個Spout、Bolt組成。
2.3、叢集架構
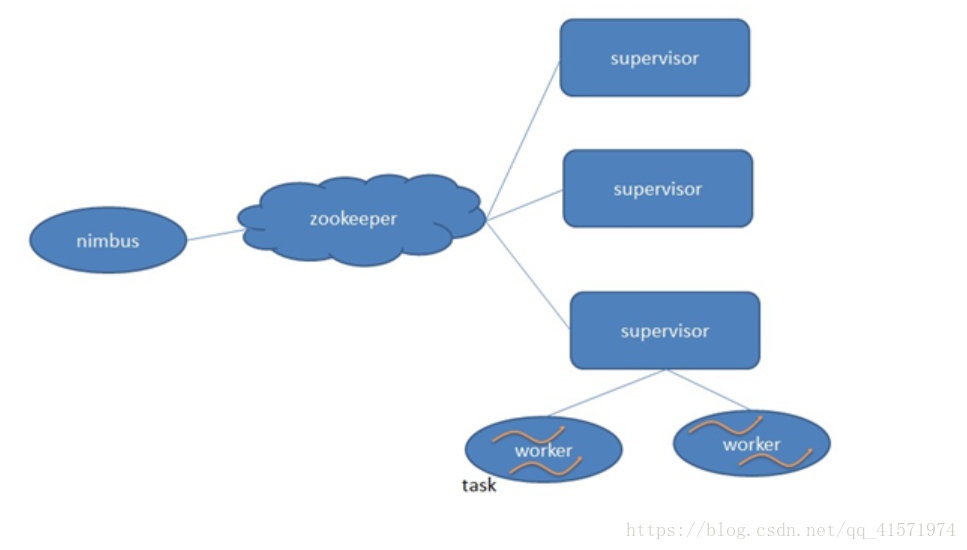
-
Nimbus:負責資源分配和任務排程。
-
Supervisor:負責接受nimbus分配的任務,啟動和停止屬於自己管理的worker程序。
-
Worker:執行具體處理元件邏輯的程序。
-
Task:worker中每一個spout/bolt的執行緒稱為一個task. 在storm0.8之後,task不再與物理執行緒對應,同一個spout/bolt的task可能會共享一個物理執行緒,該執行緒稱為executor。
架構說明:
-
在叢集架構中,使用者提交到任務到storm,交由nimbus處理。
-
nimbus通過zookeeper進行查詢supervisor的情況,然後選擇supervisor進行執行任務。
-
supervisor會啟動一個woker程序,在worker程序中啟動執行緒進行執行具體的業務邏輯。
2.4、開發環境與生產環境
在開發Storm應用時,會面臨著2套環境,一是開發環境,另一個是生產環境也是叢集環境。
-
開發環境無需搭建叢集,Storm已經為開發環境做了模擬支援,可以讓開發人員非常輕鬆的在本地執行Storm應用,無需安裝部分任何的環境。
-
叢集環境,需要在linux機器上進行部署,然後將開發好的jar包,部署到叢集中才能執行,類似於hadoop中的MapReduce程式的執行。
3、Storm快速入門
3.1、需求分析

Topology的設計:

說明:
-
RandomSentenceSpout:隨機生成一個英文的字串,模擬使用者的輸入;
-
SplitSentenceBolt:將接收到的句子按照空格進行分割;
-
WordCountBolt:負責將接收到上游的單詞對出現的次數進行統計;
-
PrintBolt:負責將接收到的資料打印出來;
3.2、建立工程,匯入依賴
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>itcast-bigdata</artifactId> <groupId>cn.itcast.bigdata</groupId> <version>1.0.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>itcast-bigdata-storm</artifactId> <dependencies> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.1.1</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> </dependencies> </project>
3.3、編寫RandomSentenceSpout
package cn.itcast.storm;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Map;
import java.util.Random;
/**
* Spout類需要繼承BaseRichSpout抽象類實現
*/
public class RandomSentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private String[] sentences = new String[]{"the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature"};
/**
* 初始化的一些操作放到這裡
*
* @param conf 配置資訊
* @param context 應用的上下文
* @param collector 向下遊輸出資料的收集器
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/**
* 處理業務邏輯,在最後向下遊輸出資料
*/
public void nextTuple() {
//隨機生成句子
String sentence = this.sentences[new Random().nextInt(sentences.length)];
System.out.println("生成的句子為 --> " + sentence);
//向下遊輸出
this.collector.emit(new Values(sentence));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
//定義向下遊輸出的名稱
declarer.declare(new Fields("sentence"));
}
}
3.4、編寫SplitSentenceBolt
package cn.itcast.storm;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
/**
* 實現Bolt,需要繼承BaseRichBolt
*/
public class SplitSentenceBolt extends BaseRichBolt{
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
// 通過Tuple的getValueByField獲取上游傳遞的資料,其中"sentence"是定義的欄位名稱
String sentence = input.getStringByField("sentence");
// 進行分割處理
String[] words = sentence.split(" ");
// 向下遊輸出資料
for (String word : words) {
this.collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
3.5、編寫WordCountBolt
package cn.itcast.storm;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
public class WordCountBolt extends BaseRichBolt {
private Map<String, Integer> wordMaps = new HashMap<String, Integer>();
private OutputCollector collector;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = this.wordMaps.get(word);
if (null == count) {
count = 0;
}
count++;
this.wordMaps.put(word, count);
// 向下遊輸出資料,注意這裡輸出的多個欄位資料
this.collector.emit(new Values(word, count));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
3.6、編寫PrintBolt
package cn.itcast.storm;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.util.Map;
public class PrintBolt extends BaseRichBolt {
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = input.getIntegerByField("count");
// 列印上游傳遞的資料
System.out.println(word + " : " + count);
// 注意:這裡不需要再向下游傳遞資料了,因為沒有下游了
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
3.7、編寫WordCountTopology
package cn.itcast.storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountTopology {
public static void main(String[] args) {
//第一步,定義TopologyBuilder物件,用於構建拓撲
TopologyBuilder topologyBuilder = new TopologyBuilder();
//第二步,設定spout和bolt
topologyBuilder.setSpout("RandomSentenceSpout", new RandomSentenceSpout());
topologyBuilder.setBolt("SplitSentenceBolt", new SplitSentenceBolt()).shuffleGrouping("RandomSentenceSpout");
topologyBuilder.setBolt("WordCountBolt", new WordCountBolt()).shuffleGrouping("SplitSentenceBolt");
topologyBuilder.setBolt("PrintBolt", new PrintBolt()).shuffleGrouping("WordCountBolt");
//第三步,構建Topology物件
StormTopology topology = topologyBuilder.createTopology();
//第四步,提交拓撲到叢集,這裡先提交到本地的模擬環境中進行測試
LocalCluster localCluster = new LocalCluster();
Config config = new Config();
localCluster.submitTopology("WordCountTopology", config, topology);
}
}
3.8、測試
生成的句子為 --> i am at two with nature i : 1 am : 1 at : 1 two : 1 with : 1 nature : 1 生成的句子為 --> the cow jumped over the moon the : 1 cow : 1 jumped : 1 over : 1 the : 2 moon : 1 生成的句子為 --> an apple a day keeps the doctor away an : 1 apple : 1 a : 1 day : 1 keeps : 1 the : 3 doctor : 1 away : 1
至此,一個簡單的Storm應用就編寫完成了。
4、叢集模式
編寫完的Storm的Topology應用最終需要提交到叢集執行的,所以需要先部署Storm叢集環境。
4.1、叢集機器的分配情況
| 主機名 | IP地址 | zookeeper | nimbus | supervisor |
|---|---|---|---|---|
| node01 | 192.168.40.133 | √ | √ | |
| node02 | 192.168.40.134 | √ | √ | |
| node03 | 192.168.40.135 | √ | √ |
注意:storm叢集依賴於zookeeper,所以要先保證zookeeper叢集的正確執行。
4.2、搭建Storm叢集環境
cd /export/software/
rz 上傳apache-storm-1.1.1.tar.gz
tar -xvf apache-storm-1.1.1.tar.gz -C /export/servers/
cd /export/servers/
mv apache-storm-1.1.1/ storm
#配置環境變數
export STORM_HOME=/export/servers/storm
export PATH=${STORM_HOME}/bin:$PATH
source /etc/profile
修改配置檔案:
cd /export/servers/storm/conf/ vim storm.yaml #指定zookeeper服務的地址 storm.zookeeper.servers: - "node01" - "node02" - "node03" #指定nimbus所在的機器 nimbus.seeds: ["node01"] #指定ui管理介面的埠 ui.port: 18080 #儲存退出
分發到node02、node03上。
scp -r /export/servers/storm/ node02:/export/servers/ scp -r /export/servers/storm/ node03:/export/servers/ scp /etc/profile node02:/etc/ source /etc/profile #在node02上執行 scp /etc/profile node03:/etc/ source /etc/profile #在node03上執行
在node01上啟動nimbus和ui,node02、node03上啟動supervisor。
node01:
nohup storm nimbus > /dev/null 2>&1 & nohup storm ui > /dev/null 2>&1 & #logviewer用於線上檢視日誌檔案 nohup storm logviewer > /dev/null 2>&1 &
node02:
nohup storm supervisor > /dev/null 2>&1 & nohup storm logviewer > /dev/null 2>&1 &
node03:
nohup storm supervisor > /dev/null 2>&1 & nohup storm logviewer > /dev/null 2>&1 &
4.3、檢查叢集是否正常執行

線上檢視日誌:

至此,storm的叢集搭建完畢。
5、提交Topology到叢集
5.1、修改Topology的提交程式碼
package cn.itcast.storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountTopology {
public static void main(String[] args) {
//第一步,定義TopologyBuilder物件,用於構建拓撲
TopologyBuilder topologyBuilder = new TopologyBuilder();
//第二步,設定spout和bolt
topologyBuilder.setSpout("RandomSentenceSpout", new RandomSentenceSpout());
topologyBuilder.setBolt("SplitSentenceBolt", new SplitSentenceBolt()).shuffleGrouping("RandomSentenceSpout");
topologyBuilder.setBolt("WordCountBolt", new WordCountBolt()).shuffleGrouping("SplitSentenceBolt");
topologyBuilder.setBolt("PrintBolt", new PrintBolt()).shuffleGrouping("WordCountBolt");
//第三步,構建Topology物件
StormTopology topology = topologyBuilder.createTopology();
Config config = new Config();
//第四步,提交拓撲到叢集,這裡先提交到本地的模擬環境中進行測試
// LocalCluster localCluster = new LocalCluster();
// localCluster.submitTopology("WordCountTopology", config, topology);
try {
//提交到叢集
StormSubmitter.submitTopology("WordCountTopology", config, topology);
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
} catch (AuthorizationException e) {
e.printStackTrace();
}
}
}
5.2、專案打包

打包成功。
5.3、上傳到伺服器
cd /tmp rz上傳itcast-bigdata-storm-1.0.0-SNAPSHOT.jar
5.4、提交Topology到叢集
#通過storm jar命令提交jar,並且需要指定執行的入口類 storm jar itcast-bigdata-storm-1.0.0-SNAPSHOT.jar cn.itcast.storm.WordCountTopology
提交過程如下:
Running: /export/software/jdk1.8.0_141/bin/java -client -Ddaemon.name= -Dstorm.options= -Dstorm.home=/export/servers/storm -Dstorm.log.dir=/export/servers/storm/logs -Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file= -cp /export/servers/storm/lib/asm-5.0.3.jar:/export/servers/storm/lib/objenesis-2.1.jar:/export/servers/storm/lib/log4j-core-2.8.2.jar:/export/servers/storm/lib/reflectasm-1.10.1.jar:/export/servers/storm/lib/storm-rename-hack-1.1.1.jar:/export/servers/storm/lib/kryo-3.0.3.jar:/export/servers/storm/lib/log4j-over-slf4j-1.6.6.jar:/export/servers/storm/lib/slf4j-api-1.7.21.jar:/export/servers/storm/lib/servlet-api-2.5.jar:/export/servers/storm/lib/clojure-1.7.0.jar:/export/servers/storm/lib/log4j-slf4j-impl-2.8.2.jar:/export/servers/storm/lib/log4j-api-2.8.2.jar:/export/servers/storm/lib/disruptor-3.3.2.jar:/export/servers/storm/lib/storm-core-1.1.1.jar:/export/servers/storm/lib/minlog-1.3.0.jar:/export/servers/storm/lib/ring-cors-0.1.5.jar:itcast-bigdata-storm-1.0.0-SNAPSHOT.jar:/export/servers/storm/conf:/export/servers/storm/bin -Dstorm.jar=itcast-bigdata-storm-1.0.0-SNAPSHOT.jar -Dstorm.dependency.jars= -Dstorm.dependency.artifacts={} cn.itcast.storm.WordCountTopology
1197 [main] WARN o.a.s.u.Utils - STORM-VERSION new 1.1.1 old null
1248 [main] INFO o.a.s.StormSubmitter - Generated ZooKeeper secret payload for MD5-digest: -6891877266277720388:-8731485235457199991
1412 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : node01:6627
1539 [main] INFO o.a.s.s.a.AuthUtils - Got AutoCreds []
1564 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : node01:6627
1644 [main] INFO o.a.s.StormSubmitter - Uploading dependencies - jars...
1651 [main] INFO o.a.s.StormSubmitter - Uploading dependencies - artifacts...
1651 [main] INFO o.a.s.StormSubmitter - Dependency Blob keys - jars : [] / artifacts : []
1698 [main] INFO o.a.s.StormSubmitter - Uploading topology jar itcast-bigdata-storm-1.0.0-SNAPSHOT.jar to assigned location: /export/servers/storm/storm-local/nimbus/inbox/stormjar-d80d9d68-4257-4b69-b179-7ffff28134e5.jar
1742 [main] INFO o.a.s.StormSubmitter - Successfully uploaded topology jar to assigned location: /export/servers/storm/storm-local/nimbus/inbox/stormjar-d80d9d68-4257-4b69-b179-7ffff28134e5.jar
1742 [main] INFO o.a.s.StormSubmitter - Submitting topology WordCountTopology in distributed mode with conf {"storm.zookeeper.topology.auth.scheme":"digest","storm.zookeeper.topology.auth.payload":"-6891877266277720388:-8731485235457199991"}
1742 [main] WARN o.a.s.u.Utils - STORM-VERSION new 1.1.1 old 1.1.1
2553 [main] INFO o.a.s.StormSubmitter - Finished submitting topology: WordCountTopology

可以看到在介面中已經存在Topology的資訊。
提示:可以點選Topology的名稱檢視詳情。
5.5、檢視執行結果
通過介面管理工具可以看到,該任務被分配到了node02上:
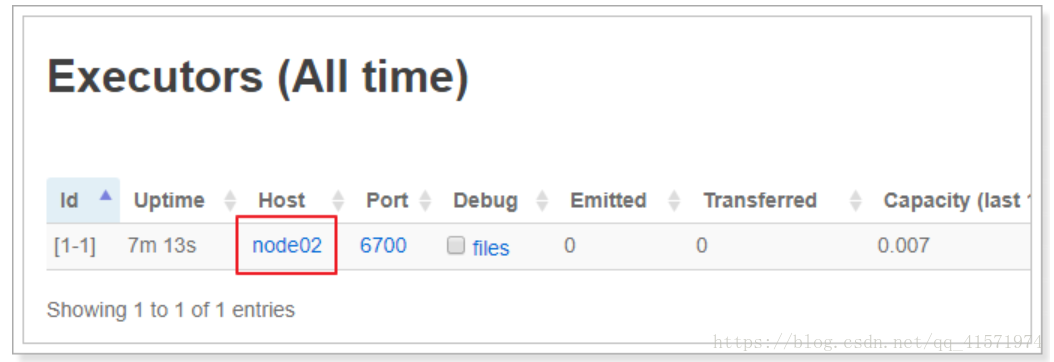
進入node02機器的logs目錄:/export/servers/storm/logs/workers-artifacts/WordCountTopology-1-1531816634/6700
tail -f worker.log 2018-07-17 16:48:06.401 STDIO Thread-4-RandomSentenceSpout-executor[2 2] [INFO] 生成的句子為 --> the cow jumped over the moon 2018-07-17 16:48:06.415 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] the : 2507 2018-07-17 16:48:06.415 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] cow : 642 2018-07-17 16:48:06.415 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] jumped : 642 2018-07-17 16:48:06.415 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] over : 642 2018-07-17 16:48:06.416 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] the : 2508 2018-07-17 16:48:06.417 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] moon : 642 2018-07-17 16:48:06.602 STDIO Thread-4-RandomSentenceSpout-executor[2 2] [INFO] 生成的句子為 --> i am at two with nature 2018-07-17 16:48:06.615 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] i : 625 2018-07-17 16:48:06.615 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] am : 625 2018-07-17 16:48:06.615 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] at : 625 2018-07-17 16:48:06.615 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] two : 625 2018-07-17 16:48:06.615 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] with : 625 2018-07-17 16:48:06.615 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] nature : 625 2018-07-17 16:48:06.803 STDIO Thread-4-RandomSentenceSpout-executor[2 2] [INFO] 生成的句子為 --> an apple a day keeps the doctor away 2018-07-17 16:48:06.811 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] an : 598 2018-07-17 16:48:06.812 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] apple : 598 2018-07-17 16:48:06.812 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] a : 598 2018-07-17 16:48:06.812 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] day : 598 2018-07-17 16:48:06.812 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] keeps : 598 2018-07-17 16:48:06.812 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] the : 2509 2018-07-17 16:48:06.812 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] doctor : 598 2018-07-17 16:48:06.812 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] away : 598 2018-07-17 16:48:07.004 STDIO Thread-4-RandomSentenceSpout-executor[2 2] [INFO] 生成的句子為 --> an apple a day keeps the doctor away 2018-07-17 16:48:07.017 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] an : 599 2018-07-17 16:48:07.018 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] apple : 599 2018-07-17 16:48:07.018 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] a : 599 2018-07-17 16:48:07.018 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] day : 599 2018-07-17 16:48:07.018 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] keeps : 599 2018-07-17 16:48:07.018 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] the : 2510 2018-07-17 16:48:07.018 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] doctor : 599 2018-07-17 16:48:07.018 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] away : 599 2018-07-17 16:48:07.205 STDIO Thread-4-RandomSentenceSpout-executor[2 2] [INFO] 生成的句子為 --> an apple a day keeps the doctor away 2018-07-17 16:48:07.215 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] an : 600 2018-07-17 16:48:07.215 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] apple : 600 2018-07-17 16:48:07.215 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] a : 600 2018-07-17 16:48:07.215 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] day : 600 2018-07-17 16:48:07.215 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] keeps : 600 2018-07-17 16:48:07.216 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] the : 2511 2018-07-17 16:48:07.216 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] doctor : 600 2018-07-17 16:48:07.216 STDIO Thread-8-PrintBolt-executor[1 1] [INFO] away : 600
可以看到任務在正常的執行。
除了通過命令列檢視,也可以在介面中檢視,如下:

5.6、停止任務
在Storm叢集中,停止任務有2種方式:(停止後,如果想繼續執行該任務需要重新提交任務)
方式一:通過命令停止
#指定Topology的名稱進行停止 storm kill WordCountTopology Running: /export/software/jdk1.8.0_141/bin/java -client -Ddaemon.name= -Dstorm.options= -Dstorm.home=/export/servers/storm -Dstorm.log.dir=/export/servers/storm/logs -Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file= -cp /export/servers/storm/lib/asm-5.0.3.jar:/export/servers/storm/lib/objenesis-2.1.jar:/export/servers/storm/lib/log4j-core-2.8.2.jar:/export/servers/storm/lib/reflectasm-1.10.1.jar:/export/servers/storm/lib/storm-rename-hack-1.1.1.jar:/export/servers/storm/lib/kryo-3.0.3.jar:/export/servers/storm/lib/log4j-over-slf4j-1.6.6.jar:/export/servers/storm/lib/slf4j-api-1.7.21.jar:/export/servers/storm/lib/servlet-api-2.5.jar:/export/servers/storm/lib/clojure-1.7.0.jar:/export/servers/storm/lib/log4j-slf4j-impl-2.8.2.jar:/export/servers/storm/lib/log4j-api-2.8.2.jar:/export/servers/storm/lib/disruptor-3.3.2.jar:/export/servers/storm/lib/storm-core-1.1.1.jar:/export/servers/storm/lib/minlog-1.3.0.jar:/export/servers/storm/lib/ring-cors-0.1.5.jar:/export/servers/storm/conf:/export/servers/storm/bin org.apache.storm.command.kill_topology WordCountTopology 3484 [main] INFO o.a.s.u.NimbusClient - Found leader nimbus : node01:6627 3609 [main] INFO o.a.s.c.kill-topology - Killed topology: WordCountTopology
方式二:通過管理介面停止

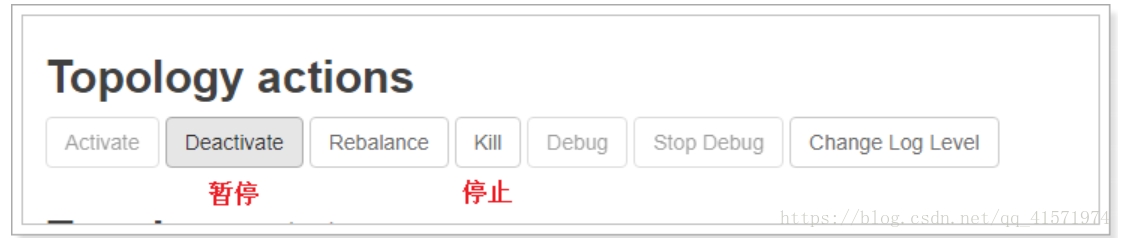
推薦使用第二種方式。
6、核心內容詳解
通過以上的學習,我們基本掌握了Storm的應用開發。
6.1、Topology的並行度(Parallelism)
問題:
-
如果Spout中產生的資料過多,下游的bolt處理不及時,怎麼辦?
-
同理,bolt中產生的資料過多,下游的bolt處理不及時,怎麼辦?
-
所提交的任務只被分配給了一個supervisor,另一個空閒,怎麼辦?
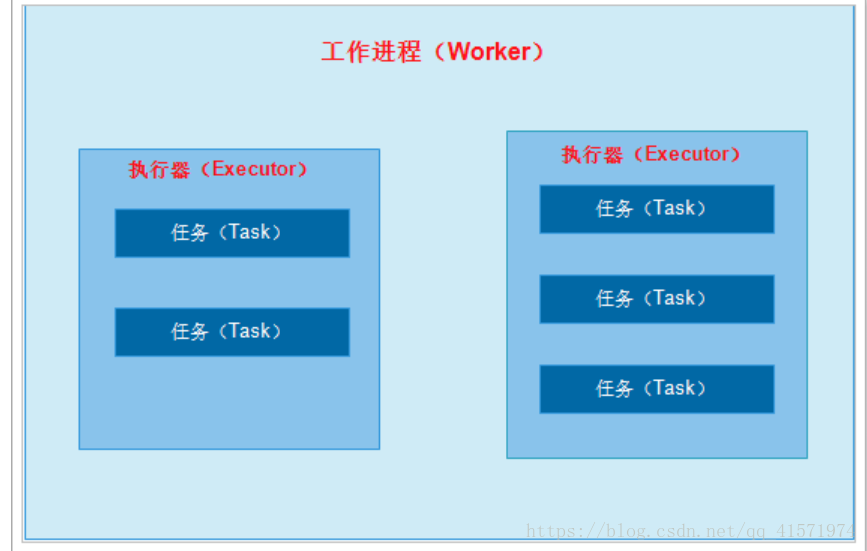
6.1.1、工作程序、執行器、任務
在瞭解Topology的並行度之前先要理清楚工作程序、執行器、任務的關係。
工作程序(worker):在Storm中,所提交的Topology將會在supervisor伺服器上,啟動獨立的程序來執行。
worker數可以在config物件中設定:
config.setNumWorkers(2); // 設定工作程序數
執行器(Executor):是在worker中執行的執行緒,在向Topology新增spout或bolt時可以設定執行緒數;
如:
topologyBuilder.setSpout("RandomSentenceSpout", new RandomSentenceSpout(),2);
說明:數字2代表是執行緒數,也是並行度數,但,並不是Topology的並行度。
任務(task):是在執行器中最小的工作單元,從storm 0.8後,task不再對應的是物理執行緒,每個 spout 或者 bolt 都會在叢集中執行很多個 task。可以在程式碼中設定tast數,如:
topologyBuilder.setBolt("SplitSentenceBolt", new SplitSentenceBolt()).shuffleGrouping("RandomSentenceSpout").setNumTasks(4);
在拓撲的整個生命週期中每個元件的 task 數量都是保持不變的,不過每個元件的 executor 數量卻是有可能會隨著時間變化。在預設情況下 task 的數量是和 executor 的數量一樣的,也就是說,預設情況下 Storm 會在每個執行緒上執行一個 task。
它們三者的關係如下:
6.1.2、案例
package cn.itcast.storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountTopology {
public static void main(String[] args) {
//第一步,定義TopologyBuilder物件,用於構建拓撲
TopologyBuilder topologyBuilder = new TopologyBuilder();
//第二步,設定spout和bolt
topologyBuilder.setSpout("RandomSentenceSpout", new RandomSentenceSpout(),2).setNumTasks(2);
topologyBuilder.setBolt("SplitSentenceBolt", new SplitSentenceBolt(), 4).shuffleGrouping("RandomSentenceSpout").setNumTasks(4);
topologyBuilder.setBolt("WordCountBolt", new WordCountBolt(), 2).shuffleGrouping("SplitSentenceBolt");
topologyBuilder.setBolt("PrintBolt", new PrintBolt()).shuffleGrouping("WordCountBolt");
//第三步,構建Topology物件
StormTopology topology = topologyBuilder.createTopology();
Config config = new Config();
config.setNumWorkers(2); // 設定工作程序數
//第四步,提交拓撲到叢集,這裡先提交到本地的模擬環境中進行測試
// LocalCluster localCluster = new LocalCluster();
// localCluster.submitTopology("WordCountTopology", config, topology);
try {
//提交到叢集
StormSubmitter.submitTopology("WordCountTopology", config, topology);
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
} catch (AuthorizationException e) {
e.printStackTrace();
}
}
}
以上的Topology提交到集群后,總共是有多個worker、Executor、Task?
works:2
Executor:9
Task:8
對嗎?

每個執行器至少會有一個任務。所以,任務數應該是9。
6.1.3、實際開發中,這些數該如何設定?
首先,這些數字不能拍腦袋設定,需要進行計算每個spout、bolt的執行時間和需要處理的資料量大小進行計算。才能設定出合理的數字,並且這些數字需要根據業務量的變化和進行調整。
6.2、Stream grouping(流分組)
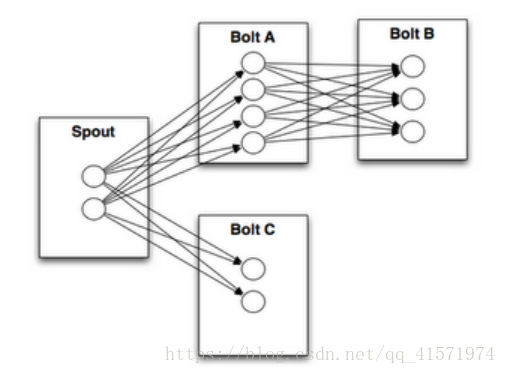
如上圖所示,BoltA向BoltB傳送資料時,由於BoltB中有3個任務,那麼應該發給哪一個呢?
流分組就是來解決這個問題的。
Storm內建了8個流分組方式:
package org.apache.storm.topology;
import org.apache.storm.generated.GlobalStreamId;
import org.apache.storm.generated.Grouping;
import org.apache.storm.grouping.CustomStreamGrouping;
import org.apache.storm.tuple.Fields;
public interface InputDeclarer<T extends InputDeclarer> {
// 欄位分組
public T fieldsGrouping(String componentId, Fields fields);
public T fieldsGrouping(String componentId, String streamId, Fields fields);
// 全域性分組
public T globalGrouping(String componentId);
public T globalGrouping(String componentId, String streamId);
// 隨機分組
public T shuffleGrouping(String componentId);
public T shuffleGrouping(String componentId, String streamId);
// 本地或隨機分組
public T localOrShuffleGrouping(String componentId);
public T localOrShuffleGrouping(String componentId, String streamId);
// 無分組
public T noneGrouping(String componentId);
public T noneGrouping(String componentId, String streamId);
// 廣播分組
public T allGrouping(String componentId);
public T allGrouping(String componentId, String streamId);
// 直接分組
public T directGrouping(String componentId);
public T directGrouping(String componentId, String streamId);
// 部分關鍵字分組
public T partialKeyGrouping(String componentId, Fields fields);
public T partialKeyGrouping(String componentId, String streamId, Fields fields);
// 自定義分組
public T customGrouping(String componentId, CustomStreamGrouping grouping);
public T customGrouping(String componentId, String streamId, CustomStreamGrouping grouping);
}
-
欄位分組(Fields Grouping ):根據指定的欄位的值進行分組,舉個栗子,流按照“user-id”進行分組,那麼具有相同的“user-id”的tuple會發到同一個task,而具有不同“user-id”值的tuple可能會發到不同的task上。這種情況常常用在單詞計數,而實際情況是很少用到,因為如果某個欄位的某個值太多,就會導致task不均衡的問題。
-
全域性分組(Global grouping ):這種分組會將所有的tuple都發到一個taskid最小的task上。由於所有的tuple都發到唯一一個task上,勢必在資料量大的時候會造成資源不夠用的情況。
-
隨機分組(Shuffle grouping):隨機的將tuple分發給bolt的各個task,每個bolt例項接收到相同數量的tuple。
-
本地或隨機分組(Local or shuffle grouping):和隨機分組類似,但是如果目標Bolt在同一個工作程序中有一個或多個任務,那麼元組將被隨機分配到那些程序內task。簡而言之就是如果傳送者和接受者在同一個worker則會減少網路傳輸,從而提高整個拓撲的效能。有了此分組就完全可以不用shuffle grouping了。
-
無分組(None grouping):不指定分組就表示你不關心資料流如何分組。目前來說不分組和隨機分組效果是一樣的,但是最終,Storm可能會使用與其訂閱的bolt或spout在相同程序的bolt來執行這些tuple。
-
廣播分組(All grouping):將所有的tuple都複製之後再分發給Bolt所有的task,每一個訂閱資料流的task都會接收到一份相同的完全的tuple的拷貝。
-
直接分組(Direct grouping):這是一種特殊的分組策略。這種方式分組的流意味著將由元組的生成者決定消費者的哪個task能接收該元組。
-
部分關鍵字分組(Partial Key grouping):流由分組中指定的欄位分割槽,如“欄位”分組,但是在兩個下游Bolt之間進行負載平衡,當輸入資料歪斜時,可以更好地利用資源。有了這個分組就完全可以不用Fields grouping了。
-
自定義分組(Custom Grouping):通過實現CustomStreamGrouping介面來實現自己的分組策略。
6.2.1、案例
對於我們寫的WordCount的程式應該使用哪一種? 原來使用的隨機分組有沒有問題?
package cn.itcast.storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountTopology {
public static void main(String[] args) {
//第一步,定義TopologyBuilder物件,用於構建拓撲
TopologyBuilder topologyBuilder = new TopologyBuilder();
//第二步,設定spout和bolt
topologyBuilder.setSpout("RandomSentenceSpout", new RandomSentenceSpout(), 2).setNumTasks(2);
topologyBuilder.setBolt("SplitSentenceBolt", new SplitSentenceBolt(), 4).shuffleGrouping("RandomSentenceSpout").setNumTasks(4);
topologyBuilder.setBolt("WordCountBolt", new WordCountBolt(), 2).partialKeyGrouping("SplitSentenceBolt", new Fields("word"));
topologyBuilder.setBolt("PrintBolt", new PrintBolt()).shuffleGrouping("WordCountBolt");
//第三步,構建Topology物件
StormTopology topology = topologyBuilder.createTopology();
Config config = new Config();
config.setNumWorkers(1); // 設定工作程序數
//第四步,提交拓撲到叢集,這裡先提交到本地的模擬環境中進行測試
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("WordCountTopology", config, topology);
// try {
// //提交到叢集
// StormSubmitter.submitTopology("WordCountTopology", config, topology);
// } catch (AlreadyAliveException e) {
// e.printStackTrace();
// } catch (InvalidTopologyException e) {
// e.printStackTrace();
// } catch (AuthorizationException e) {
// e.printStackTrace();
// }
}
}
測試:
生成的句子為 --> the cow jumped over the moon 生成的句子為 --> an apple a day keeps the doctor away apple : 21 day : 21 keeps : 21 away : 21 over : 19 an : 21 a : 21 the : 71 doctor : 21 the : 72 cow : 19 jumped : 19 the : 73 moon : 19 生成的句子為 --> the cow jumped over the moon 生成的句子為 --> the cow jumped over the moon over : 20 the : 74 cow : 20 jumped : 20 the : 75 moon : 20 over : 21 the : 76 cow : 21 jumped : 21 the : 77 moon : 21 生成的句子為 --> four score and seven years ago four : 12 score : 12 years : 12 and : 26 seven : 26 ago : 12 生成的句子為 --> four score and seven years ago four : 13 score : 13 years : 13 and : 27 seven : 27 ago : 13 生成的句子為 --> the cow jumped over the moon over : 22 the : 78 cow : 22 jumped : 22 the : 79 moon : 22 生成的句子為 --> four score and seven years ago four : 14 score : 14 years : 14 and : 28 seven : 28 ago : 14 生成的句子為 --> snow white and the seven dwarfs snow : 15 white : 15 and : 29 the : 80 seven : 29 dwarfs : 15 生成的句子為 --> four score and seven years ago four : 15 score : 15 years : 15 and : 30 seven : 30 ago : 15
6.2.2、建議
Storm提供了8種分組方式,實際常用的有幾種? 一般常用的有2種:
-
本地或隨機分組
-
優化了網路傳輸,優先在同一個程序中傳遞。
-
-
部分關鍵字分組
-
實現了根據欄位分組,並且考慮了下游的負載均衡。
-
7、案例
將前面我們寫的WordCount程式進行優化改造,結果儲存到Redis,並且通過圖表的形式將各個單詞出現的次數進行展現。
7.1、部署Redis服務
yum -y install cpp binutils glibc glibc-kernheaders glibc-common glibc-devel gcc make gcc-c++ libstdc++-devel tcl cd /export/software wget http://download.redis.io/releases/redis-3.0.2.tar.gz 或者 rz 上傳 tar -xvf redis-3.0.2.tar.gz -C /export/servers cd /export/servers/ mv redis-3.0.2 redis cd redis make make test #這個就不要執行了,需要很長時間 make install mkdir /export/servers/redis-server cp /export/servers/redis/redis.conf /export/servers/redis-server vi /export/servers/redis-server/redis.conf # 修改如下,預設為no daemonize yes cd /export/servers/redis-server/ #啟動 redis-server ./redis.conf #測試 redis-cli
7.2、匯入jedis依賴
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency>
7.3、編寫RedisBolt,實現儲存資料到redis
package cn.itcast.storm;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.util.Map;
public class RedisBolt extends BaseRichBolt {
private JedisPool jedisPool;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
jedisPool = new JedisPool(new JedisPoolConfig(), "node01",6379);
}
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = input.getIntegerByField("count");
// 儲存到redis中的key
String key = "wordCount:" + word;
Jedis jedis = null;
try {
jedis = this.jedisPool.getResource();
jedis.set(key, String.valueOf(count));
} finally {
if(null != jedis){
jedis.close();
}
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
7.4、修改WordCountTopology類
增加RedistBolt到Topology中。具體如下:
package cn.itcast.storm;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountTopology {
public static void main(String[] args) {
//第一步,定義TopologyBuilder物件,用於構建拓撲
TopologyBuilder topologyBuilder = new TopologyBuilder();
//第二步,設定spout和bolt
topologyBuilder.setSpout("RandomSentenceSpout", new RandomSentenceSpout(), 2).setNumTasks(2);
topologyBuilder.setBolt("SplitSentenceBolt", new SplitSentenceBolt(), 4).localOrShuffleGrouping("RandomSentenceSpout").setNumTasks(4);
topologyBuilder.setBolt("WordCountBolt", new WordCountBolt(), 2).partialKeyGrouping("SplitSentenceBolt", new Fields("word"));
// topologyBuilder.setBolt("PrintBolt", new PrintBolt()).shuffleGrouping("WordCountBolt");
topologyBuilder.setBolt("RedistBolt", new RedisBolt()).localOrShuffleGrouping("WordCountBolt");
//第三步,構建Topology物件
StormTopology topology = topologyBuilder.createTopology();
Config config = new Config();
config.setNumWorkers(2); // 設定工作程序數
//第四步,提交拓撲到叢集,這裡先提交到本地的模擬環境中進行測試
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("WordCountTopology", config, topology);
// try {
// //提交到叢集
// StormSubmitter.submitTopology("WordCountTopology", config, topology);
// } catch (AlreadyAliveException e) {
// e.printStackTrace();
// } catch (InvalidTopologyException e) {
// e.printStackTrace();
// } catch (AuthorizationException e) {
// e.printStackTrace();
// }
}
}
7.5、測試
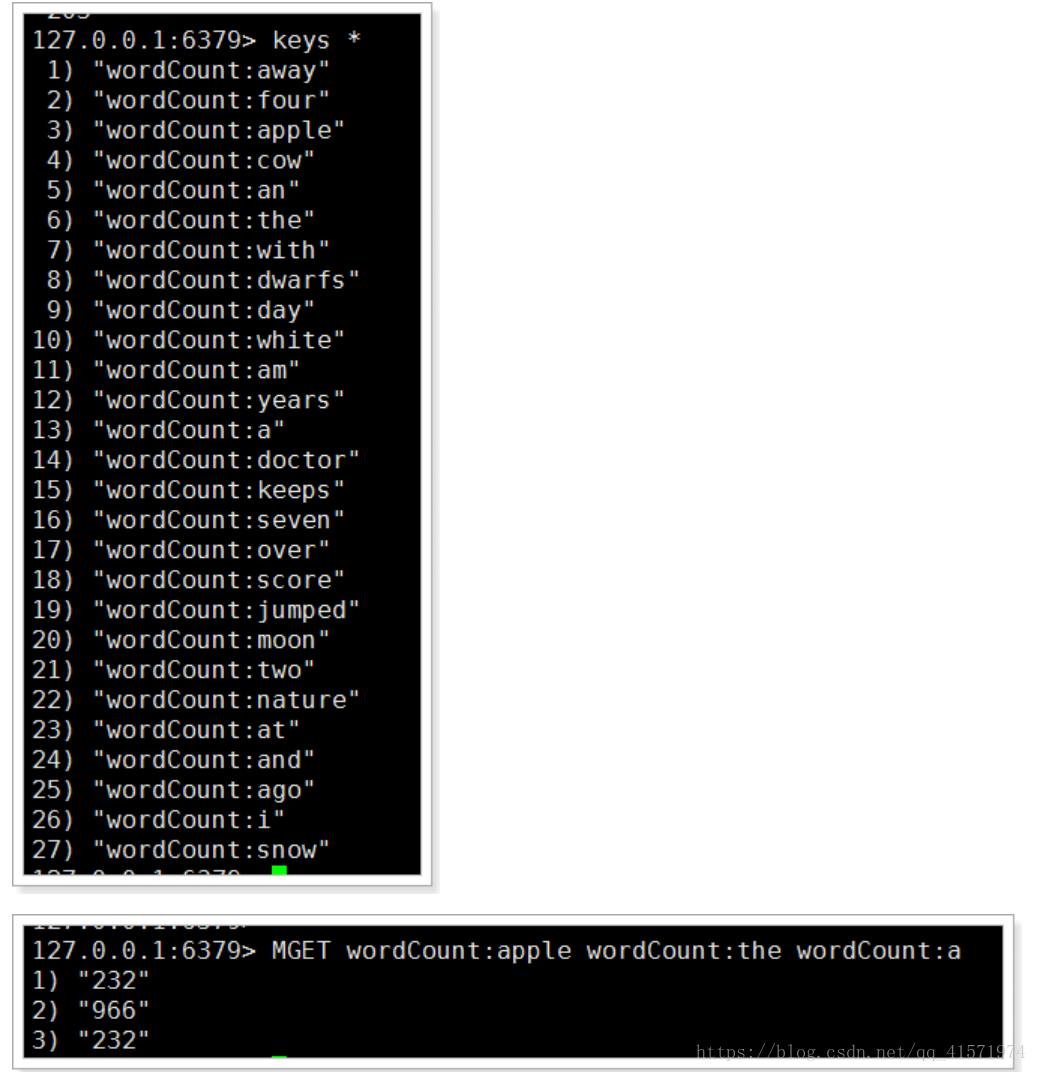
可以看到已經有資料儲存到了Redis中。
7.6、建立工程 itcast-wordcount-web
該工程用於展示資料。
使用技術:SpringMVC +spring-data-redis + echarts
效果:

<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>itcast-bigdata</artifactId>
<groupId>cn.itcast.bigdata</groupId>
<version>1.0.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<packaging>war</packaging>
<artifactId>itcast-wordcount-web</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.0.7.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>2.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<!-- Jackson Json處理工具包 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.4</version>
</dependency>
<!-- JSP相關 -->
<dependency>
<groupId>jstl</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jsp-api</artifactId>
<version>2.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}</finalName>
<plugins>
<!-- 資原始檔拷貝外掛 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>2.7</version>
<configuration>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- java編譯外掛 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- 配置Tomcat外掛 -->
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.2</version>
<configuration>
<path>/</path>
<port>8086</port>
</configuration>
</plugin>
</plugins>
</build>
</project>
7.7、編寫配置檔案
7.7.1、log4j.properties
log4j.rootLogger=DEBUG,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss} [%t] [%c]-[%p] %m%n
7.7.2、itcast-wordcount-servlet.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-4.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd">
<!-- 掃描包 -->
<context:component-scan base-package="cn.itcast.wordcount"/>
<!-- 註解驅動 -->
<mvc:annotation-driven />
<!-- 配置檢視解析器 -->
<!--
Example: prefix="/WEB-INF/jsp/", suffix=".jsp", viewname="test" -> "/WEB-INF/jsp/test.jsp"
-->
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/views/"/>
<property name="suffix" value=".jsp"/>
</bean>
<!--靜態資源交由web容器處理-->
<mvc:default-servlet-handler/>
</beans>
7.7.3、itcast-wordcount-redis.xml
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="jedisConnectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory" p:use-pool="true" p:hostName="node01" p:port="6379"/> <bean id="stringRedisTemplate" class="org.springframework.data.redis.core.StringRedisTemplate" p:connection-factory-ref="jedisConnectionFactory"/> </beans>
7.7.4、web.xml
需要建立webapp以及WEB-INF目錄。
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://java.sun.com/xml/ns/javaee" xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd" id="WebApp_ID" version="2.5"> <display-name>itcast-wordcount</display-name> <!-- 配置SpringMVC框架入口 --> <servlet> <servlet-name>itcast-wordcount</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> <init-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:itcast-wordcount-*.xml</param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet> <servlet-mapping> <servlet-name>itcast-wordcount</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping> <welcome-file-list> <welcome-file>index.jsp</welcome-file> </welcome-file-list> </web-app>
7.8、編寫程式碼
7.8.1、編寫Controller
package cn.itcast.wordcount.controller;
import cn.itcast.wordcount.service.WordCountService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.List;
import java.util.Map;
@Controller
public class WordCountController {
@Autowired
private WordCountService wordCountService;
@RequestMapping("view")
public String wordCountView(){
return "view";
}
@RequestMapping("data")
@ResponseBody
public Map<String,String> queryData(){
return this.wordCountService.queryData();
}
}
7.8.2、編寫WordCountService
package cn.itcast.wordcount.service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
@Service
public class WordCountService {
@Autowired
private RedisTemplate redisTemplate;
public Map<String, String> queryData() {
Set<String> keys = this.redisTemplate.keys("wordCount:*");
Map<String, String> result = new HashMap<>();
for (String key : keys) {
result.put(key.substring(key.indexOf(':') + 1), this.redisTemplate.opsForValue().get(key).toString());
}
return result;
}
}
7.9、編寫view.jsp
在WEB-INF/view下建立view.jsp
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>Word Count View Page</title>
<script type="application/javascript" src="/js/jquery.min.js"></script>
<script type="application/javascript" src="/js/echarts.min.js"></script>
</head>
<body>
<div id="main" style="height: 100%"></div>
<script type="text/javascript">
// 基於準備好的dom,初始化echarts例項
var myChart = echarts.init(document.getElementById('main'));
// 指定圖表的配置項和資料
var option = {
title: {
text: 'Word Count'
},
tooltip : {//滑鼠懸浮彈窗提示
trigger : 'item',
show:true,
showDelay: 5,
hideDelay: 2,
transitionDuration:0,
formatter: function (params,ticket,callback) {
// console.log(params);
var res = "次數:"+params.value;
return res;
}
},
xAxis: {
data: [],
type: 'category',
axisLabel: {
interval: 0
}
},
yAxis: {},
series: [{
name: '數量',
type: 'bar',
data: [],
itemStyle: {
color: '#2AAAE3'
}
}, {
name: '折線',
type: 'line',
itemStyle: {
color: '#FF3300'
},
data: []
}
]
};
// 使用剛指定的配置項和資料顯示圖表。
myChart.setOption(option);
myChart.showLoading();
// 非同步載入資料
$.get('/data', function (data) {
var words = [];
var counts = [];
var counts2 = [];
for (var d in data) {
words.push(d);
counts.push(data[d]);
counts2.push(eval(data[d]) + 50);
}
myChart.hideLoading();
// 填入資料
myChart.setOption({
xAxis: {
data: words
},
series: [{
name: '數量',
data: counts
},{
name: '折線',
data: counts2
}]
});
});
</script>
</body>
</html>
7.10、itcast-bigdata-storm 專案打包
現在我們需要將itcast-bigdata-storm專案打包成jar包,釋出到storm叢集環境中。
7.10.1、修改WordCountTopology