
Elasticsearch基礎入門
本文以 Elasticsearch 5.6.2為例。
最新(截止到2018-09-23)的 Elasticsearch 是 6.4.1。5.x系列和6.x系列雖然有些區別,但基本用法是一樣的。
官方文件: https://www.elastic.co/guide/en/elasticsearch/reference/5.6/
安裝
安裝比較簡單。分兩步:
- 配置JDK環境
- 安裝Elasticsearch
Elasticsearch 依賴 JDK環境,需要系統先下載安裝 JDK 並配置
JAVA_HOME環境變數。JDK 版本推薦:1.8.0系列。地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
安裝JDk
Linux:
$ yum install -y java-1.8.0-openjdk配置環境變數,需要修改/etc/profile, 增加:
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el6_10.x86_64
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
JAVACMD=/usr/bin/java
export JAVA_HOME JAVACMD CLASSPATH PATH然後使之生效:
source /etc/profile
Windows:
安裝包地址: http://download.oracle.com/otn-pub/java/jdk/8u191-b12/2787e4a523244c269598db4e85c51e0c/jdk-8u191-windows-x64.exe
下載並配置JDK環境變數
JAVA_HOME=C:\Program Files\Java\jdk1.8.0_101
CLASSPATH=.;%JAVA_HOME%\lib;.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;安裝Elasticsearch
Elasticsearch 安裝只需要下載二進位制壓縮包包,解壓即可使用。需要特別注意的是版本號,如果還要安裝Kibana及外掛,需要注意選用一樣的版本號。
安裝包下載:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.2.tar.gz
這個頁面有 Elasticsearch 所有版本的下載:https://www.elastic.co/downloads/past-releases
下載後解壓到指定目錄,進入到 bin 目錄,就可以執行 Elasticsearch 了: Linux:
./elasticsearchWindows:
elasticsearch.bat注: Linux/Mac環境不能使用 root 使用者執行。
基礎入門
我們可以使用curl或者kibana提供的Dev Tools進行API測試。
例如: curl方式:
curl 'localhost:9200/_cat/health?format=json'
[{"epoch":"1537689647","timestamp":"16:00:47","cluster":"elasticsearch","status":"yellow","node.total":"1","node.data":"1","shards":"11","pri":"11","relo":"0","init":"0","unassign":"11","pending_tasks":"0","max_task_wait_time":"-","active_shards_percent":"50.0%"}]Dev Tools:
GET /_cat/health?format=json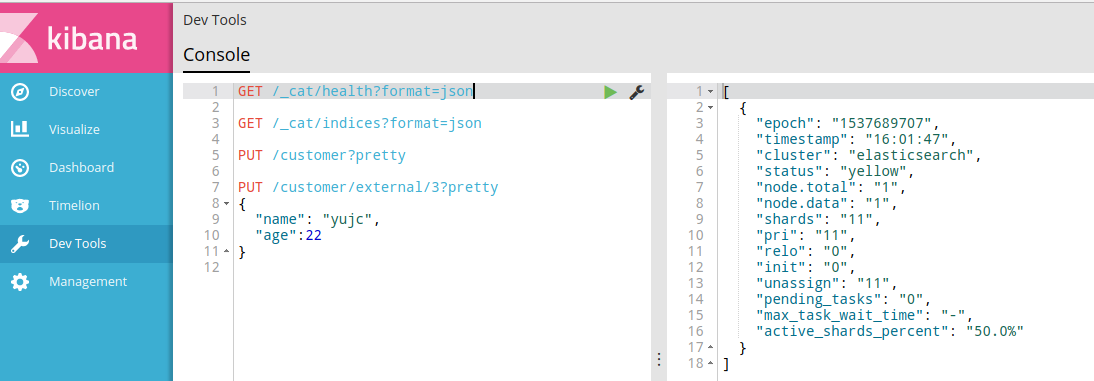
個人比較喜歡Kibana提供的Dev Tools,非常方便。
檢視_cat命令:
GET _cat=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master
/_cat/nodes
/_cat/tasks
/_cat/indices
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool
/_cat/thread_pool/{thread_pools}
/_cat/plugins
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates以下測試均在Dev Tools執行。
節點操作
檢視健康狀態
GET /_cat/health?format=json結果:
[
{
"epoch": "1537689915",
"timestamp": "16:05:15",
"cluster": "elasticsearch",
"status": "yellow",
"node.total": "1",
"node.data": "1",
"shards": "11",
"pri": "11",
"relo": "0",
"init": "0",
"unassign": "11",
"pending_tasks": "0",
"max_task_wait_time": "-",
"active_shards_percent": "50.0%"
}
]健康狀態有3種:
- Green - 正常(叢集功能齊全)
- Yellow - 所有資料均可用,但尚未分配一些副本(群集功能齊全)
- Red - 某些資料由於某種原因不可用(群集部分功能可用)
注意:當群集為紅色時,它將繼續提供來自可用分片的搜尋請求,但您可能需要儘快修復它,因為存在未分配的分片。
檢視節點
GET /_cat/nodes?format=json索引
檢視所有index
GET /_cat/indices?format=json結果:
[
{
"health": "yellow",
"status": "open",
"index": "filebeat-2018.09.23",
"uuid": "bwWVhUkBTIe46h9QJfmZHw",
"pri": "5",
"rep": "1",
"docs.count": "4231",
"docs.deleted": "0",
"store.size": "2.5mb",
"pri.store.size": "2.5mb"
},
{
"health": "yellow",
"status": "open",
"index": ".kibana",
"uuid": "tnWbNLSMT7273UEh6RfcBg",
"pri": "1",
"rep": "1",
"docs.count": "4",
"docs.deleted": "0",
"store.size": "23.9kb",
"pri.store.size": "23.9kb"
}
]建立index
PUT /customer?pretty刪除index
DELETE /customer?pretty查詢指定 Index 的 mapping
GET /customer/_mapping?pretty注:ElasticSearch裡面有
index和type的概念:index稱為索引,type為文件型別,一個index下面有多個type,每個type的欄位可以不一樣。這類似於關係型資料庫的 database 和 table 的概念。但是,ES中不同type下名稱相同的filed最終在Lucene中的處理方式是一樣的。所以後來ElasticSearch團隊想去掉type,於是在6.x版本為了向下相容,一個index只允許有一個type。預計7.x版本徹底去掉type。參考:https://www.elastic.co/guide/en/elasticsearch/reference/current/removal-of-types.html
所以,實際使用中建議一個
index裡面僅有一個type,名稱可以和index一致,或者使用固定的doc。
增刪改查
按ID新增資料
type為doc:
PUT /customer/doc/1?pretty
{
"name": "John Doe"
}PUT /customer/doc/2?pretty
{
"name": "yujc",
"age":22
}如果index不存在,直接新增資料也會同時建立index。
同時,該操作也能修改資料:
PUT /customer/doc/2?pretty
{
"name": "yujc",
"age":23
}age欄位會被修改,而且_version會被修改為2:
{
"_index": "customer",
"_type": "doc",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}按ID查詢資料
GET /customer/doc/1?pretty結果:
{
"_index": "customer",
"_type": "doc",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"name": "John Doe"
}
}直接新增資料
我們也可以不指定文件ID從而直接新增資料:
POST /customer/doc?pretty
{
"name": "yujc",
"age":23
}注意這裡使用的動作是POST。PUT新增資料必須指定文件ID。
更新資料
我們使用下面兩種方式均能更新已有資料:
PUT /customer/doc/1?pretty
{
"name": "yujc2",
"age":22
}
POST /customer/doc/1?pretty
{
"name": "yujc2",
"age":22
}以上操作均會覆蓋現有資料。
如果只是想更新指定欄位,必須使用POST加引數的形式:
POST /customer/doc/1/_update?pretty
{
"doc":{"name": "yujc"}
}其中_update表示更新。doc必須有,否則會報錯。
增加欄位:
POST /customer/doc/1/_update?pretty
{
"doc":{"yeat": 2018}
}就會在已有的資料基礎上增加一個year欄位,不會覆蓋已有資料:
GET /customer/doc/1?pretty結果:
{
"_index": "customer",
"_type": "doc",
"_id": "1",
"_version": 16,
"found": true,
"_source": {
"name": "yujc",
"age": 22,
"yeat": 2018
}
}也可以使用簡單指令碼執行更新。此示例使用指令碼將年齡增加5:
POST /customer/doc/1/_update?pretty
{
"script":"ctx._source.age+=5"
}結果:
{
"_index": "customer",
"_type": "doc",
"_id": "1",
"_version": 17,
"found": true,
"_source": {
"name": "yujc",
"age": 27,
"yeat": 2018
}
}按ID刪除資料
DELETE /customer/doc/1?pretty批量
新增
POST /customer/doc/_bulk?pretty
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }該操作會新增2條記錄,而不是4條。查詢資料:
GET /customer/doc/2?pretty結果:
{
"_index": "customer",
"_type": "doc",
"_id": "2",
"_version": 2,
"found": true,
"_source": {
"name": "Jane Doe"
}
}更新、刪除
POST /customer/doc/_bulk?pretty
{"update":{"_id":"1"}}
{"doc": { "name": "John Doe becomes Jane Doe" } }
{"delete":{"_id":"2"}}該操作會更新ID為1的文件,刪除ID為2的文件。
注意:批量操作如果某條失敗了,並不影響下一條繼續執行。
全文檢索
經過前面的基礎入門,我們對ES的基本操作也會了。現在來學習ES最強大的部分:全文檢索。
準備工作
批量匯入資料
先需要準備點資料,然後匯入:
wget https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/account/_bulk?pretty&refresh" --data-binary "@accounts.json"這樣我們就匯入了1000條資料到ES。index是bank。我們可以檢視現在有哪些index:
curl "localhost:9200/_cat/indices?format=json&pretty"結果:
[
{
"health" : "yellow",
"status" : "open",
"index" : "bank",
"uuid" : "IhyOzz3WTFuO5TNgPJUZsw",
"pri" : "5",
"rep" : "1",
"docs.count" : "1000",
"docs.deleted" : "0",
"store.size" : "640.3kb",
"pri.store.size" : "640.3kb"
},
{
"health" : "yellow",
"status" : "open",
"index" : "customer",
"uuid" : "f_nzBLypSUK2SVjL2AoKxQ",
"pri" : "5",
"rep" : "1",
"docs.count" : "9",
"docs.deleted" : "0",
"store.size" : "31kb",
"pri.store.size" : "31kb"
},
{
"health" : "yellow",
"status" : "open",
"index" : ".kibana",
"uuid" : "tnWbNLSMT7273UEh6RfcBg",
"pri" : "1",
"rep" : "1",
"docs.count" : "5",
"docs.deleted" : "0",
"store.size" : "29.4kb",
"pri.store.size" : "29.4kb"
}
]
使用kibana視覺化資料
該小節是可選的,如果不感興趣,可以跳過。
該小節要求你已經搭建好了ElasticSearch + Kibana。
開啟kibana web地址:http://127.0.0.1:5601,依次開啟:Management
-> Kibana -> Index Patterns ,選擇Create Index Pattern:
a. Index pattern 輸入:bank ;
b. 點選Create。
然後開啟Discover,選擇 bank 就能看到剛才匯入的資料了。
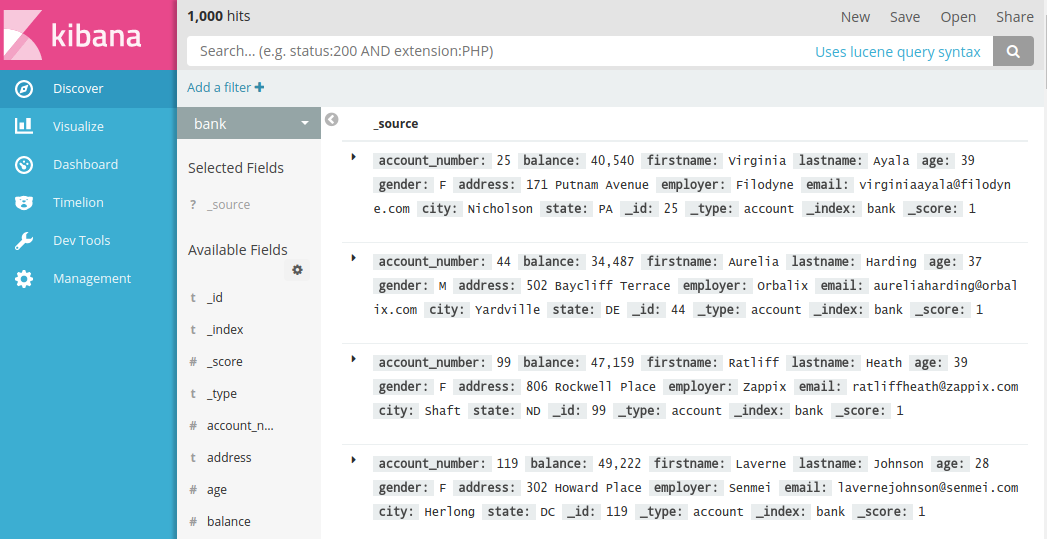
我們在視覺化介面裡檢索資料:

是不是很酷!
接下來我們使用API來實現檢索。
關鍵字檢索
模糊檢索
GET /bank/_search?q="Virginia"&pretty解釋:檢索關鍵字為"Virginia"的結果。結果示例:
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 4.631368,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "298",
"_score": 4.631368,
"_source": {
"account_number": 298,
"balance": 34334,
"firstname": "Bullock",
"lastname": "Marsh",
"age": 20,
"gender": "M",
"address": "589 Virginia Place",
"employer": "Renovize",
"email": "[email protected]",
"city": "Coinjock",
"state": "UT"
}
},
{
"_index": "bank",
"_type": "account",
"_id": "25",
"_score": 4.6146765,
"_source": {
"account_number": 25,
"balance": 40540,
"firstname": "Virginia",
"lastname": "Ayala",
"age": 39,
"gender": "F",
"address": "171 Putnam Avenue",
"employer": "Filodyne",
"email": "[email protected]",
"city": "Nicholson",
"state": "PA"
}
}
]
}
}返回欄位含義:
- took – Elasticsearch執行搜尋的時間(以毫秒為單位)
- timed_out – 搜尋是否超時
- _shards – 搜尋了多少個分片,以及搜尋成功/失敗分片的計數
- hits – 搜尋結果,是個物件
- hits.total – 符合我們搜尋條件的文件總數
- hits.hits – 實際的搜尋結果陣列(預設為前10個文件)
- hits.sort - 對結果進行排序(如果按score排序則沒有該欄位)
- hits._score、max_score - 暫時忽略這些欄位
GET /bank/_search?q=*&sort=account_number:asc&pretty解釋:所有結果通過account_number欄位升序排列。預設只返回前10條。
下面的查詢與上面的含義一致:
GET /bank/_search
{
"query": {
"multi_match" : {
"query" : "Virginia",
"fields" : ["_all"]
}
}
}
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
]
}通常我們會採用傳JSON方式查詢。Elasticsearch提供了一種JSON樣式的特定於域的語言,可用於執行查詢。這被稱為查詢DSL。
注意:上述的查詢裡面我們僅指定了index,並沒有指定type,那麼ES將不會區分type。如果想區分,請在URI後面追加type。示例:
GET /bank/account/_search。
欄位檢索
再看按欄位查詢:
GET /bank/_search
{
"query": {
"multi_match" : {
"query" : "Virginia",
"fields" : ["firstname"]
}
}
}
GET /bank/_search
{
"query": {
"match" : {
"firstname" : "Virginia"
}
}
}上面2種查詢是等效的,都是查詢firstname為Virginia的結果。
不分詞
預設檢索都是分詞的,如果我們希望精確匹配,可以這樣實現:
GET /bank/_search
{
"query": {
"match" : {
"address.keyword" : "171 Putnam Avenue"
}
}
}在欄位後面加上.keyword表示不分詞,使用精確匹配。大家可以測試下面2種查詢結果的區別:
GET /bank/_search
{
"query": {
"match" : {
"address" : "Putnam"
}
}
}
GET /bank/_search
{
"query": {
"match" : {
"address.keyword" : "Putnam"
}
}
}第二種將查不到任何結果。
分頁
分頁使用關鍵字from、size,分別表示偏移量、分頁大小。
GET /bank/_search
{
"query": { "match_all": {} },
"from": 0,
"size": 2
}from預設是0,size預設是10。
欄位排序
欄位排序關鍵字是sort。支援升序(asc)、降序(desc)。
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
],
"from":0,
"size":10
}過濾欄位
預設情況下,ES返回所有欄位。這被稱為源(_source搜尋命中中的欄位)。如果我們不希望返回所有欄位,我們可以只請求返回源中的幾個欄位。
GET /bank/_search
{
"query": { "match_all": {} },
"_source": ["account_number", "balance"]
}通過_source關鍵字可以實現欄位過濾。
AND查詢
如果我們想同時查詢符合A和B欄位的結果,該怎麼查呢?可以使用must關鍵字組合。
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "account_number":136 } },
{ "match": { "address": "lane" } },
{ "match": { "city": "Urie" } }
]
}
}
}must也等價於:
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "address": "mill" } }
],
"must": [
{ "match": { "address": "lane" } }
]
}
}
}這種相當於先查詢A再查詢B,而上面的則是同時查詢符合A和B,但結果是一樣的,執行效率可能有差異。有知道原因的朋友可以告知。
OR查詢
ES使用should關鍵字來實現OR查詢。
GET /bank/_search
{
"query": {
"bool": {
"should": [
{ "match": { "account_number":136 } },
{ "match": { "address": "lane" } },
{ "match": { "city": "Urie" } }
]
}
}
}AND取反查
must_not關鍵字實現了既不包含A也不包含B的查詢。
GET /bank/_search
{
"query": {
"bool": {
"must_not": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}表示 address 欄位需要符合既不包含 mill 也不包含 lane。
布林組合查詢
我們可以組合 must 、should 、must_not 進行復雜的查詢。
- A AND NOT B
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "age": 40 } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}相當於SQL:
select * from bank where age=40 and state!= "ID";- A AND (B OR C)
GET /bank/_search
{
"query":{
"bool":{
"must":[
{"match":{"age":39}},
{"bool":{"should":[
{"match":{"city":"Nicholson"}},
{"match":{"city":"Yardville"}}
]}
}
]
}
}
}相當於SQL:
select * from bank where age=39 and (city="Nicholson" or city="Yardville");範圍查詢
GET /bank/_search
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}相當於SQL:
select * from bank where balance between 20000 and 30000;聚合查詢
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}結果:
{
"took": 29,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped" : 0,
"failed": 0
},
"hits" : {
"total" : 1000,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound": 20,
"sum_other_doc_count": 770,
"buckets" : [ {
"key" : "ID",
"doc_count" : 27
}, {
"key" : "TX",
"doc_count" : 27
}, {
"key" : "AL",
"doc_count" : 25
}, {
"key" : "MD",
"doc_count" : 25
}, {
"key" : "TN",
"doc_count" : 23
}, {
"key" : "MA",
"doc_count" : 21
}, {
"key" : "NC",
"doc_count" : 21
}, {
"key" : "ND",
"doc_count" : 21
}, {
"key" : "ME",
"doc_count" : 20
}, {
"key" : "MO",
"doc_count" : 20
} ]
}
}
}查詢結果返回了ID州(Idaho)有27個賬戶,TX州(Texas)有27個賬戶。
相當於SQL:
SELECT state, COUNT(*) FROM bank GROUP BY state ORDER BY COUNT(*) DESC該查詢意思是按照欄位state分組,返回前10個聚合結果。
其中size設定為0意思是不返回文件內容,僅返回聚合結果。state.keyword表示欄位精確匹配,因為使用模糊匹配效能很低,所以不支援。
多重聚合
我們可以在聚合的基礎上再進行聚合,例如求和、求平均值等等。
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}上述查詢實現了在前一個聚合的基礎上,按州計算平均帳戶餘額(同樣僅針對按降序排序的前10個州)。
我們可以在聚合中任意巢狀聚合,以從資料中提取所需的統計資料。
在前一個聚合的基礎上,我們現在按降序排列平均餘額:
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}這裡基於第二個聚合結果進行倒序排列。其實上一個例子隱藏了預設排序,也就是預設按照_sort(分值)倒序:
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"_sort": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}此示例演示了我們如何按年齡段(20-29歲,30-39歲和40-49歲)進行分組,然後按性別分組,最後得到每個年齡段的平均帳戶餘額:
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}
}這個結果就複雜了,屬於巢狀分組,結果也是巢狀的:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1000,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_age": {
"buckets": [
{
"key": "20.0-30.0",
"from": 20,
"to": 30,
"doc_count": 451,
"group_by_gender": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "M",
"doc_count": 232,
"average_balance": {
"value": 27374.05172413793
}
},
{
"key": "F",
"doc_count": 219,
"average_balance": {
"value": 25341.260273972603
}
}
]
}
},
{
"key": "30.0-40.0",
"from": 30,
"to": 40,
"doc_count": 504,
"group_by_gender": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "F",
"doc_count": 253,
"average_balance": {
"value": 25670.869565217392
}
},
{
"key": "M",
"doc_count": 251,
"average_balance": {
"value": 24288.239043824702
}
}
]
}
},
{
"key": "40.0-50.0",
"from": 40,
"to": 50,
"doc_count": 45,
"group_by_gender": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "M",
"doc_count": 24,
"average_balance": {
"value": 26474.958333333332
}
},
{
"key": "F",
"doc_count": 21,
"average_balance": {
"value": 27992.571428571428
}
}
]
}
}
]
}
}
}term與match查詢
首先大家看下面的例子有什麼區別:
已知條件:ES裡address為171 Putnam Avenue的資料有1條;address為Putnam的資料有0條。index為bank,type為account,文件ID為25。
GET /bank/_search
{
"query": {
"match" : {
"address" : "Putnam"
}
}
}
GET /bank/_search
{
"query": {
"match" : {
"address.keyword" : "Putnam"
}
}
}
GET /bank/_search
{
"query": {
"term" : {
"address" : "Putnam"
}
}
}結果: 1、第一個能匹配到資料,因為會分詞查詢。 2、第二個不能匹配到資料,因為不分詞的話沒有該條資料。 3、結果不確定。需要看實際是怎麼分詞的。
我們通過下列查詢可以知曉該條資料欄位address的分詞情況:
GET /bank/account/25/_termvectors?fields=address結果:
{
"_index": "bank",
"_type": "account",
"_id": "25",
"_version": 1,
"found": true,
"took": 0,
"term_vectors": {
"address": {
"field_statistics": {
"sum_doc_freq": 591,
"doc_count": 197,
"sum_ttf": 591
},
"terms": {
"171": {
"term_freq": 1,
"tokens": [
{
"position": 0,
"start_offset": 0,
"end_offset": 3
}
]
},
"avenue": {
"term_freq": 1,
"tokens": [
{
"position": 2,
"start_offset": 11,
"end_offset": 17
}
]
},
"putnam": {
"term_freq": 1,
"tokens": [
{
"position": 1,
"start_offset": 4,
"end_offset": 10
}
]
}
}
}
}
}可以看出該條資料欄位address一共分了3個詞:
171
avenue
putnam現在可以得出第三個查詢的答案:匹配不到!但值改成小寫的putnam又能匹配到了!
原因是:
- term query 查詢的是倒排索引中確切的term
- match query 會對filed進行分詞操作,然後再查詢
由於Putnam不在分詞裡(大小寫敏感),所以匹配不到。match query先對filed進行分詞,也就是分成putnam,再去匹配倒排索引中的term,所以能匹配到。
standardanalyzer 分詞器分詞預設會將大寫字母全部轉為小寫字母。
參考
1、Getting Started | Elasticsearch Reference [5.6] | Elastic https://www.elastic.co/guide/en/elasticsearch/reference/5.6/getting-started.html 2、Elasticsearch 5.x 關於term query和match query的認識 - wangchuanfu - 部落格園 https://www.cnblogs.com/wangchuanfu/p/7444253.html