ZooKeeper內部原理
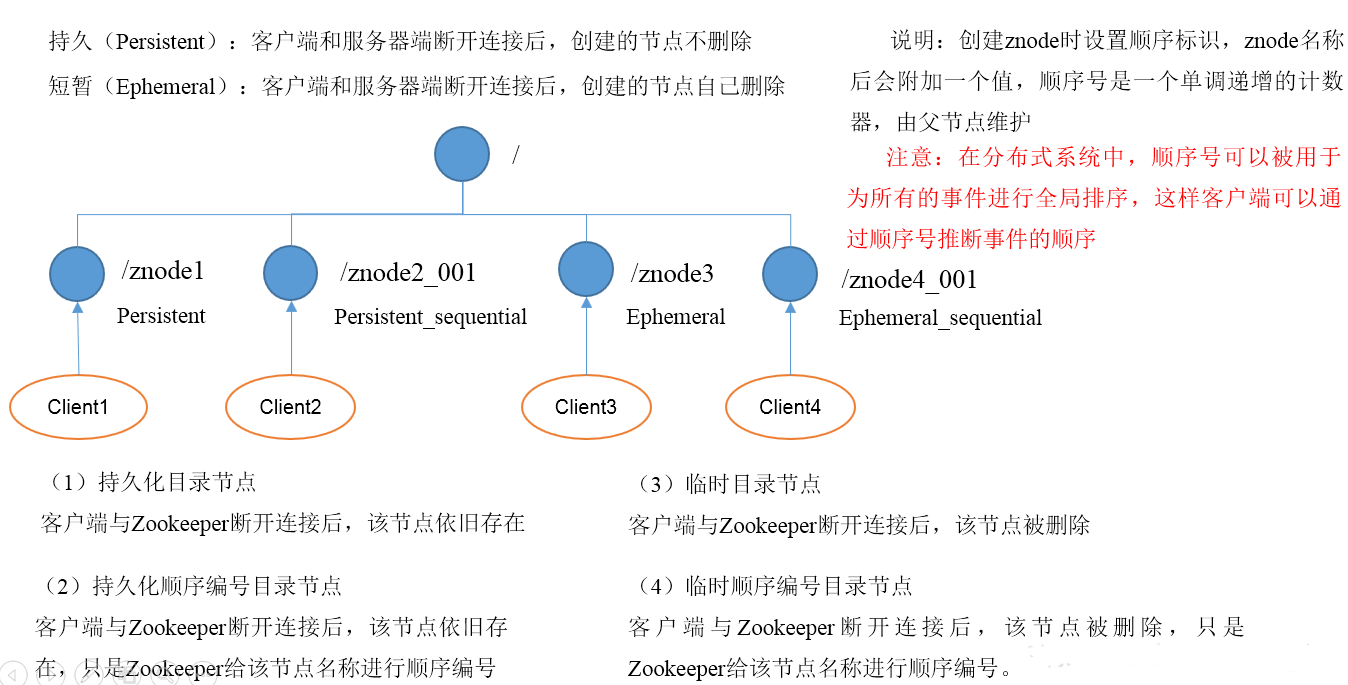
一. 節點型別
二. Stat結構體
1)czxid-建立節點的事務zxid
每次修改ZooKeeper狀態都會收到一個zxid形式的時間戳,也就是ZooKeeper事務ID。
事務ID是ZooKeeper中所有修改總的次序。每個修改都有唯一的zxid,如果zxid1小於zxid2,那麼zxid1在zxid2之前發生。
2)ctime - znode被建立的毫秒數(從1970年開始)
3)mzxid - znode最後更新的事務zxid
4)mtime - znode最後修改的毫秒數(從1970年開始)
5)pZxid-znode最後更新的子節點zxid
6)cversion - znode子節點變化號,znode子節點修改次數
7)dataversion - znode資料變化號
8)aclVersion - znode訪問控制列表的變化號
9)ephemeralOwner- 如果是臨時節點,這個是znode擁有者的session id。如果不是臨時節點則是0。
10)dataLength- znode的資料長度
11)numChildren - znode子節點數量
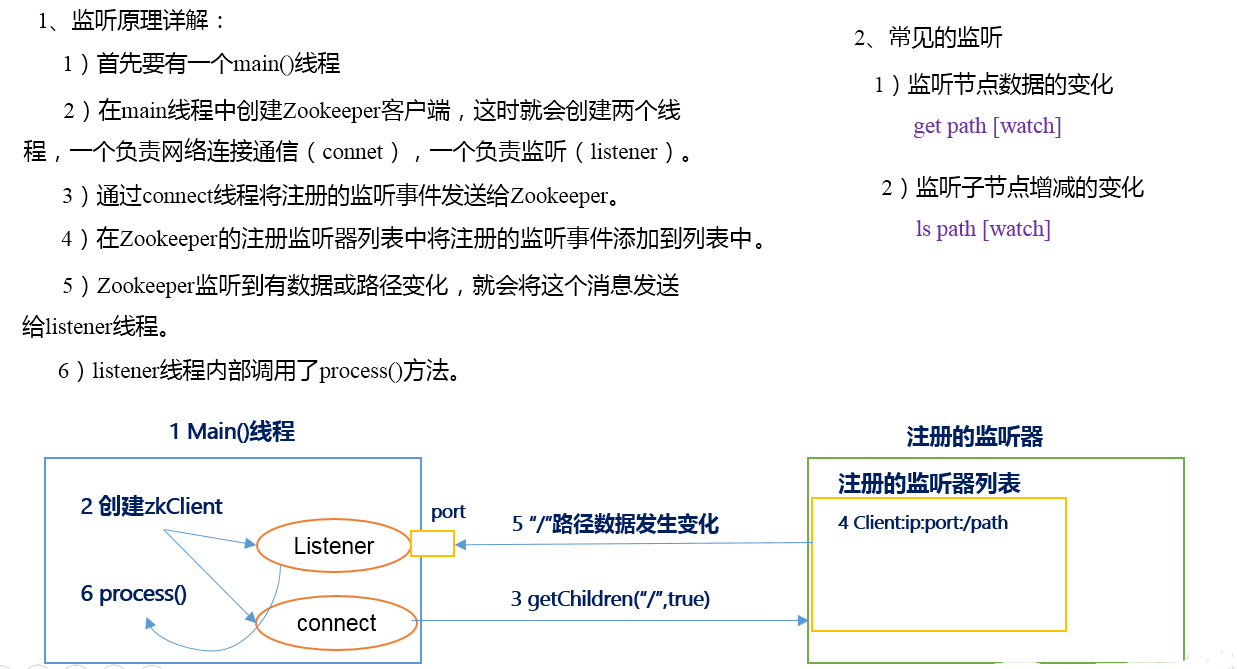
三. 監聽器原理
四. 選舉機制
1. 半數機制:叢集中半數以上機器存活,叢集可用。所以Zookeeper適合安裝奇數臺伺服器。
2. Zookeeper雖然在配置檔案中並沒有指定Master和Slave。但是,Zookeeper工作時,是有一個節點為Leader,其他則為Follower,Leader是通過內部的選舉機制臨時產生的。
3. 以一個簡單的例子來說明整個選舉的過程。
假設有五臺伺服器組成的Zookeeper叢集,它們的id從1-5,同時它們都是最新啟動的,也就是沒有歷史資料,在存放資料量這一點上,都是一樣的。假設這些伺服器依序啟動,來看看會發生什麼:
(1)伺服器1啟動,發起一次選舉。伺服器1投自己一票。此時伺服器1票數一票,不夠半數以上(3票),選舉無法完成,伺服器1狀態保持為LOOKING;
(2)伺服器2啟動,再發起一次選舉。伺服器1和2分別投自己一票並交換選票資訊:此時伺服器1發現伺服器2的ID比自己目前投票推舉的(伺服器1)大,更改選票為推舉伺服器2。此時伺服器1票數0票,伺服器2票數2票,沒有半數以上結果,選舉無法完成,伺服器1,2狀態保持LOOKING
(3)伺服器3啟動,發起一次選舉。此時伺服器1和2都會更改選票為伺服器3。此次投票結果:伺服器1為0票,伺服器2為0票,伺服器3為3票。此時伺服器3的票數已經超過半數,伺服器3當選Leader。伺服器1,2更改狀態為FOLLOWING,伺服器3更改狀態為LEADING;
(4)伺服器4啟動,發起一次選舉。此時伺服器1,2,3已經不是LOOKING狀態,不會更改選票資訊。交換選票資訊結果:伺服器3為3票,伺服器4為1票。此時伺服器4服從多數,更改選票資訊為伺服器3,並更改狀態為FOLLOWING;
(5)伺服器5啟動,同4一樣當小弟。
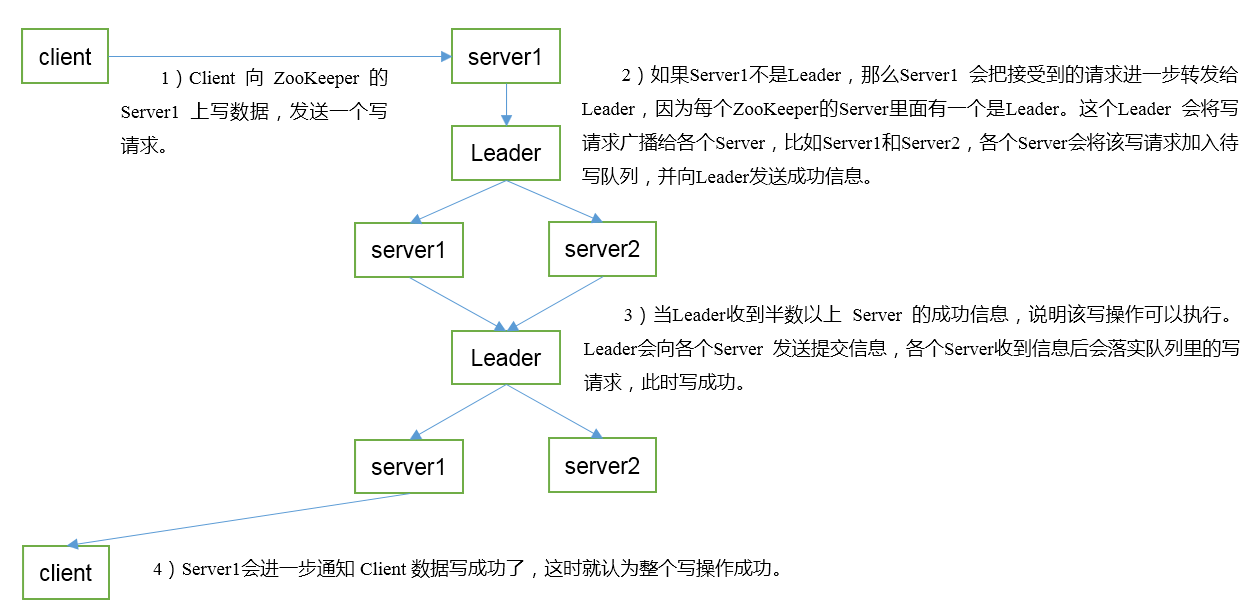
五. 寫資料流程