
閒談5個改變未來的人工智慧技術(CV方向)
前言
計算機視覺(CV)一直是目前深度學習領域最熱的研究領域,其是一種交叉學科包括電腦科學(computer science / (Graphics, Algorithms, Theory, Systems, Architecture)、數學 (Information Retrieval, Machine Learning)、工程學(Robotics, Speech, NLP, Image Processing)、物理(Optics)、生物學 (Neuroscience), and 神經科學 (Cognitive Science),由於計算機視覺表示了對視覺環境的理解,加上其學科交叉性,眾多科學家認為計算機視覺的發展可以為實現理想的人工智慧鋪路。
對於問題:什麼才是計算機視覺?以下有三個不同的教科書式計算機視覺定義:
“the construction of explicit, meaningful descriptions of physical objects from images” (Ballard & Brown, 1982)
“computing properties of the 3D world from one or more digital images” (Trucco & Verri, 1998)
“to make useful decisions about real physical objects and scenes based on sensed images” (Sockman & Shapiro, 2001)
那麼為什麼要研究計算機視覺呢?最簡單的答案就是其可以將研究快速有效的應用到現實場景中,下面列舉了幾個CV應用的場景:
- 人臉識別
- 影象檢索
- 遊戲和控制
- 監控
- 生物統計(指紋,虹膜,人臉匹配)
- 智慧駕駛
筆者最近完成了斯坦福的CS231課程【1】,課程中將卷積神經網路用在視覺識別任務中,包括影象分類,定位和檢測,尤其是深度學習技術的發展極大的提高了這些任務的精度,完成這個課程後,筆者想和大家分享5個最具影響力的計算機視覺技術。
1. 影象分類 image classification

影象分類任務描述如下:給定一系列標記為單標籤的影象,希望成功預測出未經標記的新的資料的標籤。與這個任務相聯絡的是更多的挑戰:包括:角度多樣性, scale多樣性, 額外新類的變化, 影象的損壞, 先驗條件, 和背景的變化。 so,如何才能設計一個演算法分類出不同的類,計算機視覺研究者提出以資料為驅動的解決方法,令計算機從一些已經有類別標記的影象中學習到影象的視覺表示。 而在這個演算法中最常用的就是卷積神經網路了,Convolutional Neural Networks (CNNs)。輸入影象到CNN網路中後,CNN並不是直接對整個影象做計算,而是建立一個滑動機制,假設先輸入影象中10*10的pixel,以相乘的計算方式計算,乘數部分成為卷積核,然後從左到右進行滑動,計算接下來的10*10pixel,這就是CNN中的滑動視窗計算機制
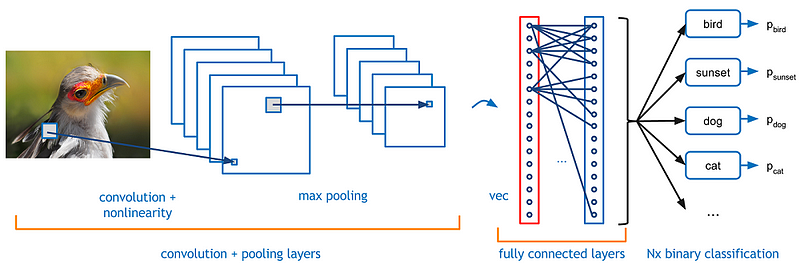 輸入資料輸入卷積層後,卷積層中卷積核僅關注當前部分和它附近的部分。整體的卷積網路趨向於更窄以便於在相同引數量的情況下搭建更深的網路。除了卷積層之外,在分類中常使用的還有池化層pooling layer,最常見的是最大池化 Max pooling,假設maxpooling的pooling核是2,maxpooling 的工作機制是取2x2大小的畫素塊中的最大值代替這個畫素塊。
影象分類最典型的資料集是imagenet,一個包含120萬張,1000類的大型影象資料集。以此資料集為基礎,衍生了許多典型的深度學習經典網路:
輸入資料輸入卷積層後,卷積層中卷積核僅關注當前部分和它附近的部分。整體的卷積網路趨向於更窄以便於在相同引數量的情況下搭建更深的網路。除了卷積層之外,在分類中常使用的還有池化層pooling layer,最常見的是最大池化 Max pooling,假設maxpooling的pooling核是2,maxpooling 的工作機制是取2x2大小的畫素塊中的最大值代替這個畫素塊。
影象分類最典型的資料集是imagenet,一個包含120萬張,1000類的大型影象資料集。以此資料集為基礎,衍生了許多典型的深度學習經典網路:
- AlexNet(2012)
- ZFNet(2013)
- VGG(2014)
- GoogleNet(2014)
- InceptionNet(2015)
- ResNet(2016)
- DenseNet(2016)
影象分類任務雖然簡單,應用範圍也有限,但是其是計算視覺的基礎,影象分類上的成功表明深度學習網路具有學習並理解影象的能力。目前計算機視覺的其他任務使用的basemodel都是在image classification上取得成功的網路結構。因此,可以把影象分類視為深度學習實現人工智慧的第一步。 注:貌似16年往後,基本沒有革新性質的網路結構出現了,/手動笑哭/。
2. 目標檢測 object detection
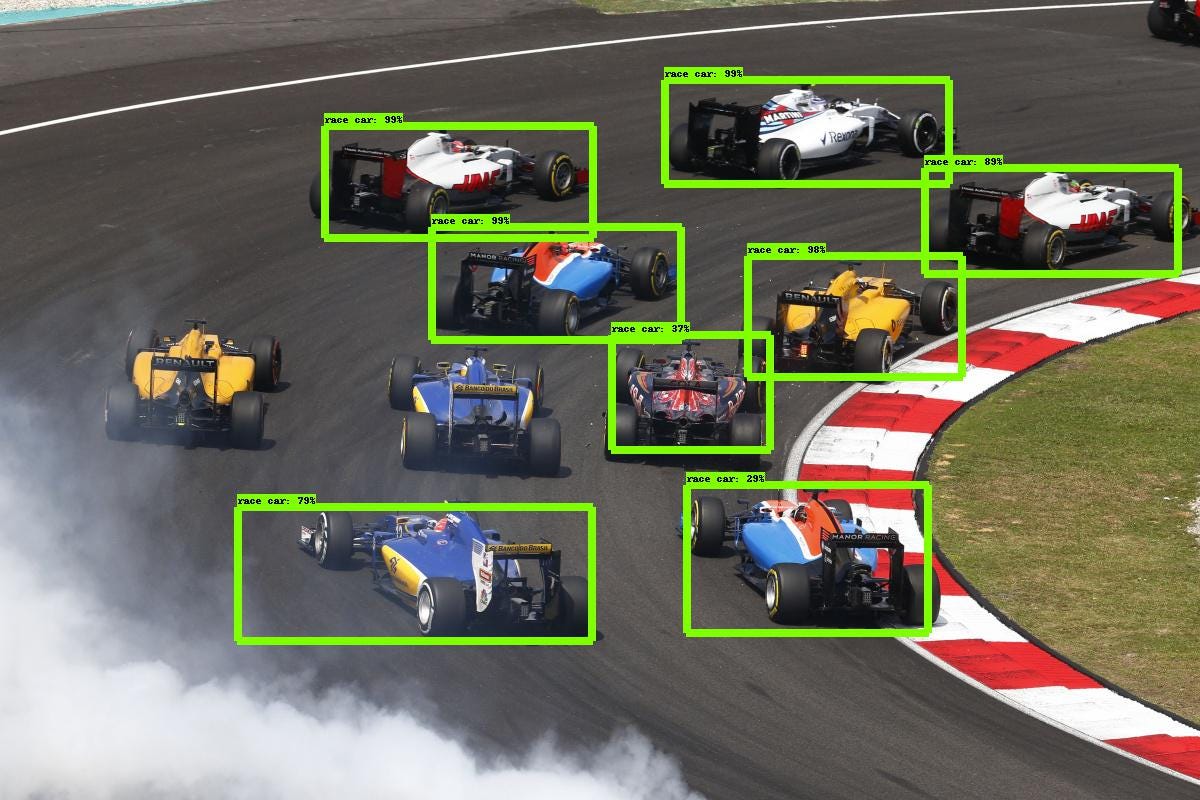
object detection的任務是檢測到影象中的目標並分類出目標種類,如上圖所示,檢測出車並框住,並給出框中目標的置信度,當然上圖並不是目前深度學習最好的結構,圖中有兩個漏檢測的目標。 目標檢測與影象分類,目標定位不同的地方在於目標檢測是同時應用分類和定位技術到影象中的多個目標,此類任務的label也更復雜,不僅要知道目標的位置(bounding box)還要知道目標的類別,而且為了檢測到比較小的目標,提高檢測精度,此類任務的batch size往往很小。
目標檢測的技術實現相對複雜,但是應用場景非常多,比如統計:統計人、車、花朵或者微生物的數量是現實生活中各種不同型別的使用圖形資訊的系統最廣泛的需求;影象檢索,根據影象檢測影象;衛星影象分析;安防場景等等。
目前深度學習在這方面的工作有很多:
以上這些都是近幾年來最典型的目標檢測成果,這些工作提供了深度學習技術在目標檢測上的應用形式以及研究方向,目前的大部分較好的結果都是基於這些工作改進而來。
3. 目標追蹤 object tracking
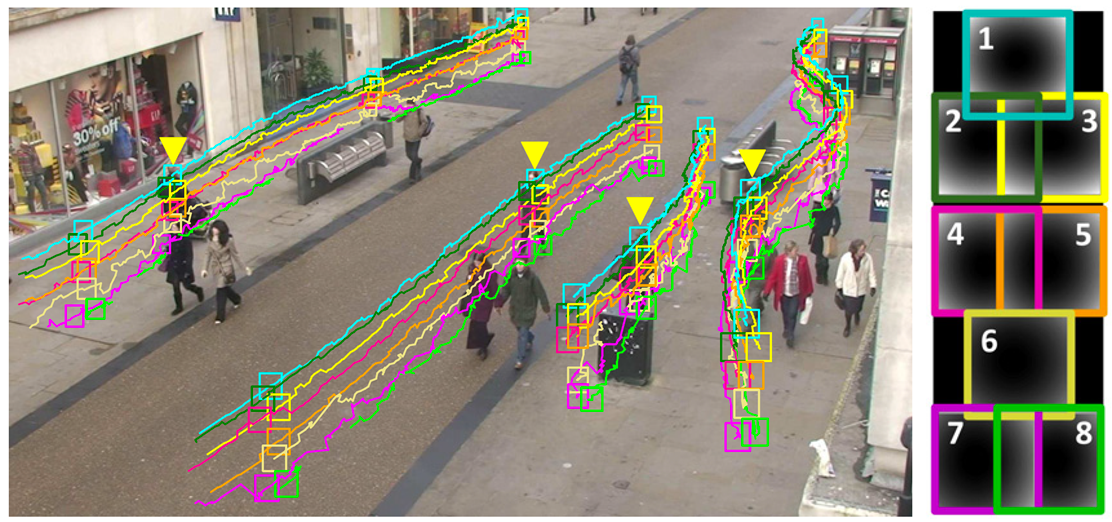 目標追蹤即是在一個給定的場景中,follow一個或者多個目標。傳統上,目標追蹤都是應用在視訊或者實時場景互動,比如觀測者追蹤一個初始的目標。目前來講,使用最典型的場景就是自動駕駛了。
目標追蹤可以分為兩類:一類是生成式方法,另一類是判別式方法。生成方法使用生成模型來描述表觀特徵並最小化重建誤差以搜尋目標,如PCA。而判別式方法可以用來區分物體和背景,其效能更穩健,並逐漸成為跟蹤的主要方法。判別法也被稱為跟蹤檢測,深度學習屬於這一類別。為了通過檢測實現跟蹤,我們檢測所有幀的候選物件,並使用深度學習從候選物件中識別想要的物件。有兩種可以使用的基本網路模型:堆疊自動編碼器(SAE)和卷積神經網路(CNN)。
使用SAE跟蹤任務的最受歡迎的深度網路是Deep Learning Tracker,它提出線下預訓練和線上微調網路,工作流程如下:
目標追蹤即是在一個給定的場景中,follow一個或者多個目標。傳統上,目標追蹤都是應用在視訊或者實時場景互動,比如觀測者追蹤一個初始的目標。目前來講,使用最典型的場景就是自動駕駛了。
目標追蹤可以分為兩類:一類是生成式方法,另一類是判別式方法。生成方法使用生成模型來描述表觀特徵並最小化重建誤差以搜尋目標,如PCA。而判別式方法可以用來區分物體和背景,其效能更穩健,並逐漸成為跟蹤的主要方法。判別法也被稱為跟蹤檢測,深度學習屬於這一類別。為了通過檢測實現跟蹤,我們檢測所有幀的候選物件,並使用深度學習從候選物件中識別想要的物件。有兩種可以使用的基本網路模型:堆疊自動編碼器(SAE)和卷積神經網路(CNN)。
使用SAE跟蹤任務的最受歡迎的深度網路是Deep Learning Tracker,它提出線下預訓練和線上微調網路,工作流程如下:
- 離線無監督預先訓練使用大規模自然影象資料集的堆疊去噪自動編碼器,以獲得一般物件的表示。疊加去噪自動編碼器通過在輸入影象中新增噪聲並重構原始影象可以獲得更強大的特徵表達能力。
- 將預先訓練好的網路的編碼部分與分類器合併得到分類網路,然後使用從初始幀中獲得的正負樣本對網路進行微調,從而可以區分當前的物件和背景。 DLT使用粒子濾波器作為運動模型來生成當前幀的候選patches。分類網路輸出這些patches的概率分數,即分類的置信度,然後選擇這些patches中最高的patches作為目標。
- DLT使用有限閾值的方式更新模型。
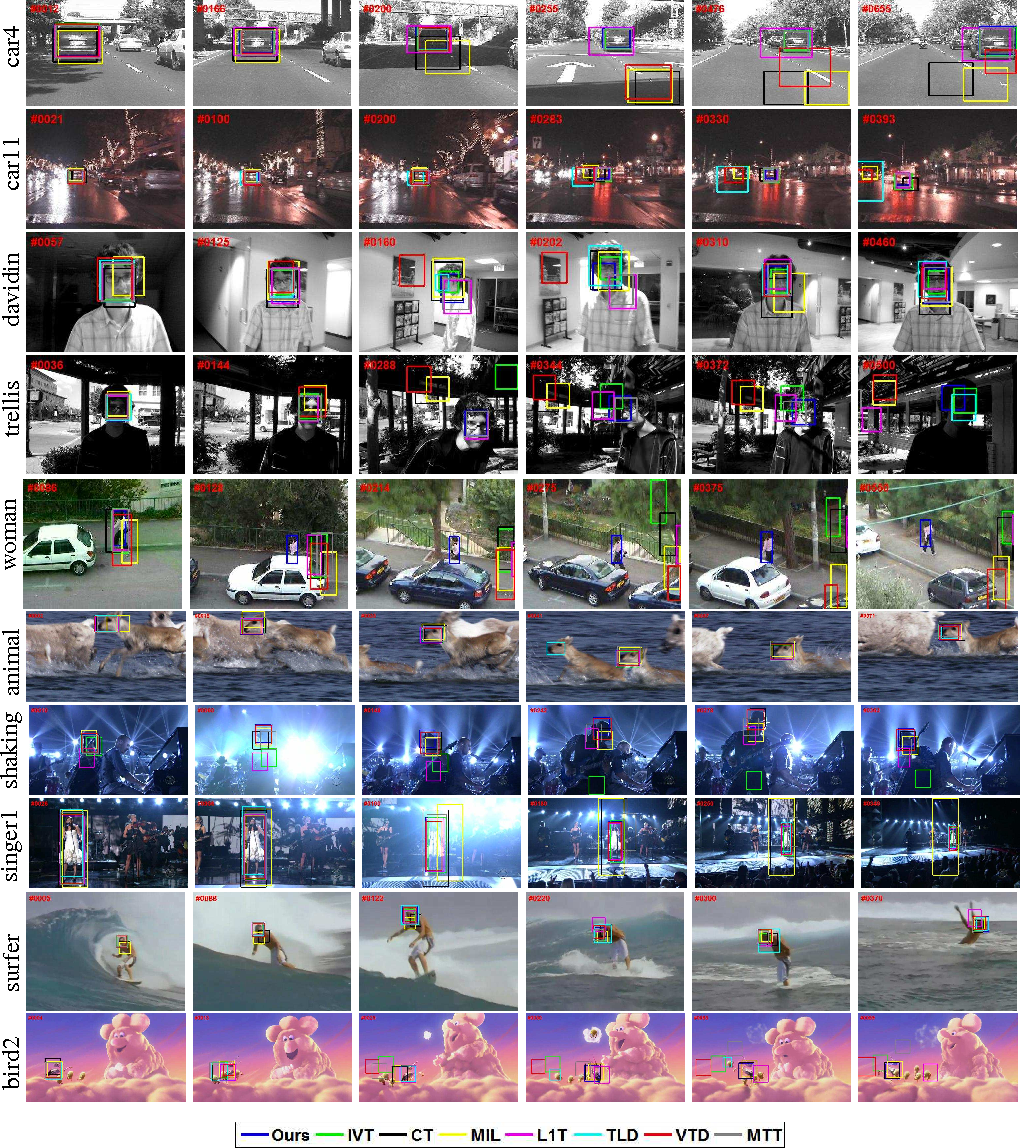
由於其在影象分類和目標檢測方面的優勢,CNN已成為計算機視覺和視覺跟蹤的主流深度模型。一般來說,大規模的CNN既可以作為分類器也可以作為跟蹤器來訓練。 2種有代表性的基於CNN的跟蹤演算法是全卷積網路跟蹤器(FCNT)和多域CNN(MD Net)。 FCNT成功地分析和利用了VGG模型的特徵圖,這是一個預先訓練好的ImageNet,並得出以下結論:
- CNN feature maps可用於定位和跟蹤。
- 許多CNN feature maps對於區分背景中的特定物件的任務而言是嘈雜或不相關的。
- 較高層捕獲物件類別的語義概念,而較低層編碼更多區分性特徵以捕獲類內變體。
因此,FCNT設計了特徵選擇網路以在VGG網路的conv4-3和conv5-3層上選擇最相關的特徵圖。然後為了避免嘈雜的過擬合,它還為兩層單獨選擇的特徵對映設計了額外的兩個通道(稱為SNet和GNet)。 GNet捕獲物件的類別資訊,而SNet將該物件從具有相似外觀的背景中區分出來。兩個網路都使用第一幀中給定的邊界框進行初始化,以獲取物件的熱圖,而對於新幀,將裁剪並傳播最後一幀中以物件位置為中心的感興趣區域(ROI)。最後,通過SNet和GNet,分類器獲取兩個預測的熱圖,跟蹤器根據是否存在干擾,決定使用哪個熱圖來生成最終的跟蹤結果。 FCNT的pipline如下所示。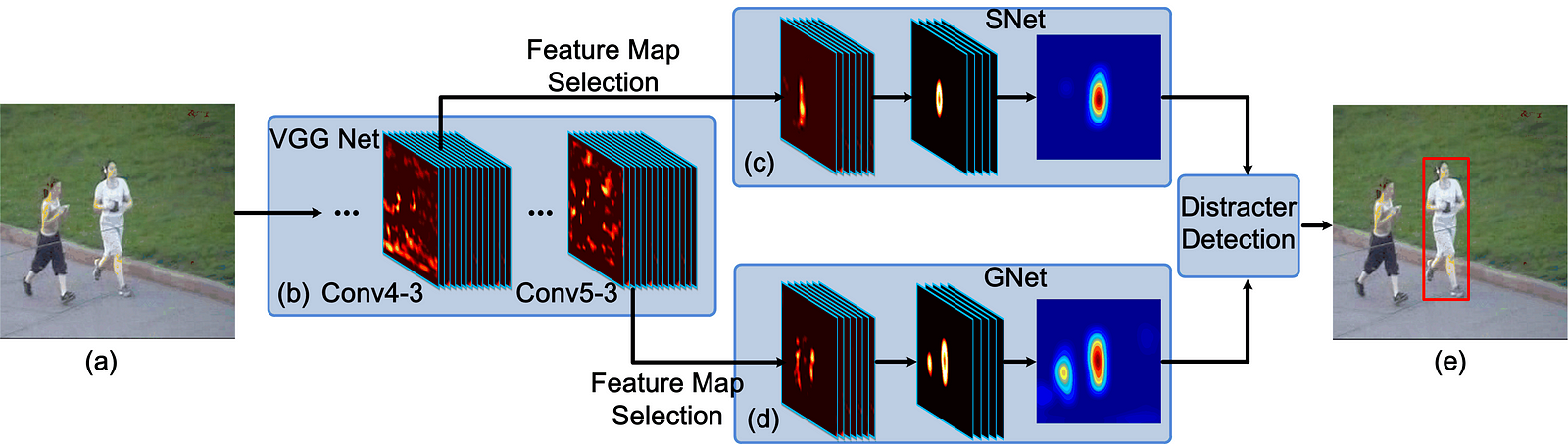
與FCNT的想法不同,MD Net使用視訊的所有序列來跟蹤它們的移動。上述網路使用不相關的影象資料來減少跟蹤資料的訓練需求,並且這種想法與跟蹤有一些偏差。該視訊中的一個類的物件可以是另一個視訊中的背景,因此MD Net提出了多域的思想來獨立地區分每個域中的物件和背景。而一個域表示一組包含相同型別物件的視訊。
如下圖所示,MD Net分為兩部分:域特定層的共享層和K分支。每個分支包含一個softmax損失的二進位制分類層,用於區分每個域中的物件和背景,共享層與所有域共享以確保一般表示。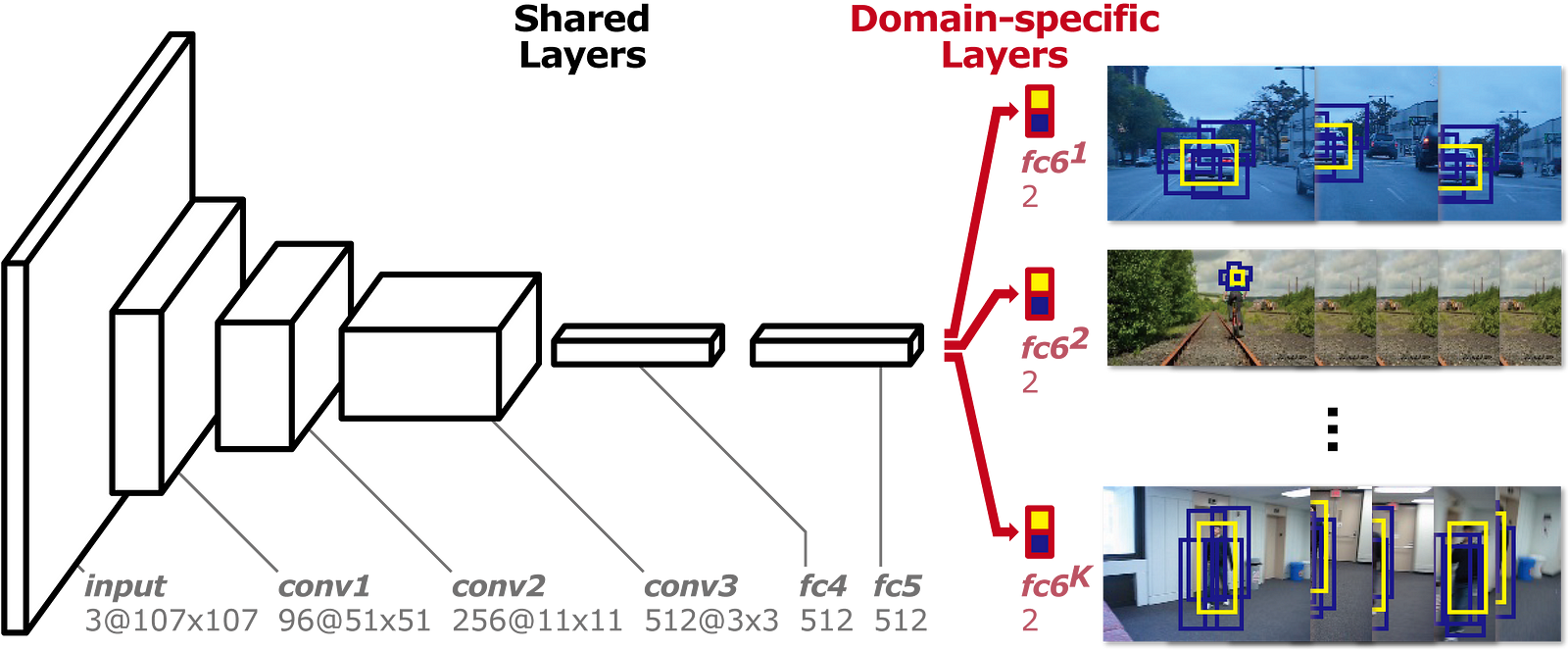
近年來,深度學習研究人員嘗試了不同的方法來適應視覺追蹤任務的特徵。有許多方向已經被探索:應用其他網路模型,如Recurrent Neural Net和Deep Belief Net,設計網路結構以適應視訊處理和端到端學習,優化流程,結構和引數,或者甚至將深度學習與計算機視覺的傳統方法或其他領域的方法(如語言處理和語音識別)相結合。
4. 語義分割 Semantic Segmentation
 計算機視覺的核心是分割過程,它將整個影象分成畫素分組,然後可以對其進行標記和分類。特別地,語義分割試圖在語義上理解影象中每個畫素的角色(例如,它是汽車,摩托車還是其他型別的類)。例如,在上圖中,除了識別人,道路,汽車,樹木等之外,我們還必須劃定每個物體的邊界。因此,與分類不同,我們需要從我們的模型進行畫素級的預測。
計算機視覺的核心是分割過程,它將整個影象分成畫素分組,然後可以對其進行標記和分類。特別地,語義分割試圖在語義上理解影象中每個畫素的角色(例如,它是汽車,摩托車還是其他型別的類)。例如,在上圖中,除了識別人,道路,汽車,樹木等之外,我們還必須劃定每個物體的邊界。因此,與分類不同,我們需要從我們的模型進行畫素級的預測。
與其他計算機視覺任務一樣,CNN在分割問題上取得了巨大成功。最流行的初始方法之一是通過滑動視窗進行patches分類,其中每個畫素使用其周圍的影象pathes分別分類。但是,這在計算上效率非常低,因為我們不重用重疊patches之間的共享功能。
加州大學伯克利分校的研究員提出了全卷積網路(FCN),它在沒有任何完全連線層的情況下推廣端到端CNN體系結構進行密集預測。這允許針對任何尺寸的影象生成分割圖,並且與patches分類方法相比也快得多。幾乎所有後續的語義分割方法都採用了這種正規化。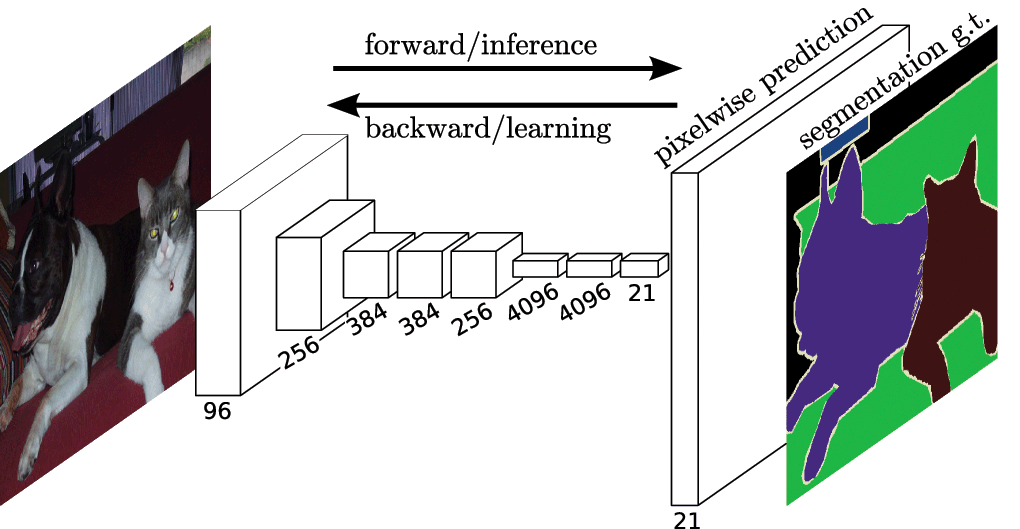
然而,仍然存在一個問題:原始影象解析度的卷積將非常昂貴。為了解決這個問題,FCN在網路內部使用下采樣和上取樣。下采樣層被稱為條帶卷積,而上取樣層被稱為轉置卷積。
儘管有上取樣/下采樣層,但由於池中的資訊丟失,FCN會生成粗分割圖。 SegNet是一種比使用最大池和編碼器 - 解碼器框架的FCN更高效的記憶體架構。在SegNet中,從更高解析度的特徵對映中引入了快捷/跳過連線,以改善上取樣/下采樣的粗糙度。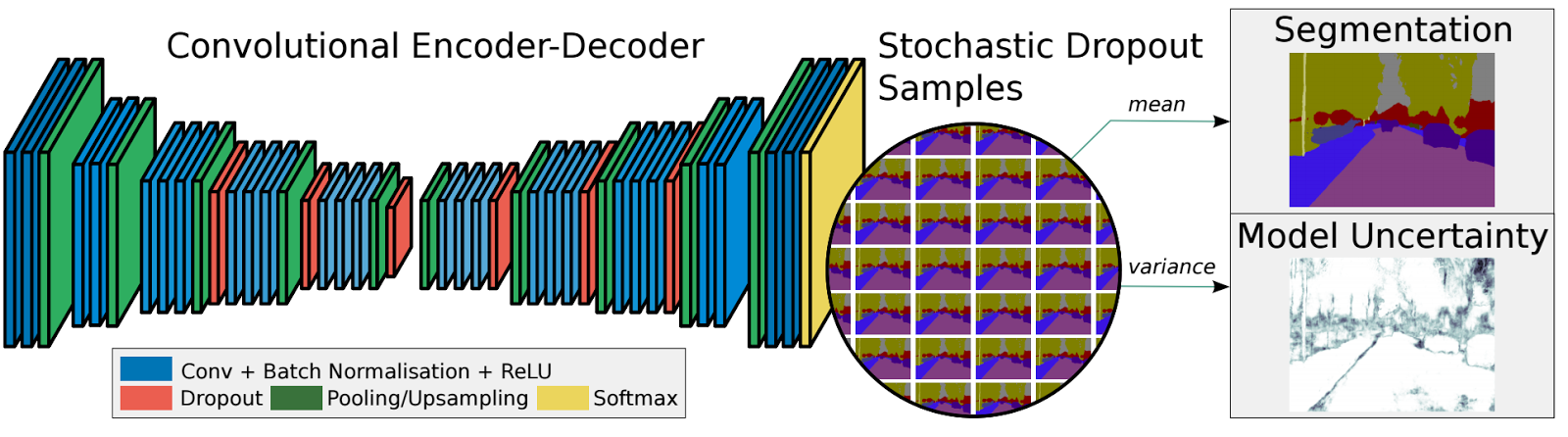 最近的語義分割研究都嚴重依賴完全卷積網路,如
空洞卷積 https://arxiv.org/pdf/1511.07122.pdf,
DeepLab https://arxiv.org/pdf/1412.7062.pdf
RefineNet https://arxiv.org/pdf/1611.06612.pdf。
最近的語義分割研究都嚴重依賴完全卷積網路,如
空洞卷積 https://arxiv.org/pdf/1511.07122.pdf,
DeepLab https://arxiv.org/pdf/1412.7062.pdf
RefineNet https://arxiv.org/pdf/1611.06612.pdf。
5. 例項分割 Instance Segmentation

除了語義分段之外,例項分段還將不同的例項分類,例如用5種不同顏色標記5輛汽車。在分類中,通常有一個影象包含單個物件作為焦點,任務是說出該影象是什麼。但為了分割例項,我們需要執行更復雜的任務。我們看到多個重疊物體和不同背景的複雜景點,我們不僅分類這些不同的物體,而且還確定它們的邊界,差異和彼此之間的關係!
到目前為止,我們已經看到了如何以許多有趣的方式使用CNN特徵,以便用bounding box框住影象中的不同物件。我們可以擴充套件這種技術來定位每個物件的精確畫素,而不僅僅是邊界框嗎?當然可以, Facebook AI使用稱為Mask R-CNN的體系結構研究了此例項分割問題。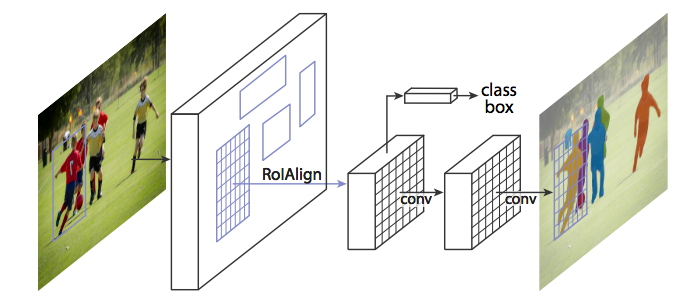 就像Fast R-CNN和更快的R-CNN一樣,Mask R-CNN的底層直覺很直觀鑑於更快的R-CNN在物體檢測方面的工作如此出色,我們是否可以將其擴充套件到進行畫素級分割?
就像Fast R-CNN和更快的R-CNN一樣,Mask R-CNN的底層直覺很直觀鑑於更快的R-CNN在物體檢測方面的工作如此出色,我們是否可以將其擴充套件到進行畫素級分割?
Mask R-CNN通過向Faster R-CNN新增分支來完成此操作,該分支輸出一個二進位制掩碼,該掩碼錶示給定畫素是否為物件的一部分。該分支是基於CNN特徵對映的完全卷積網路。給定CNN特徵對映作為輸入,網路輸出一個矩陣,其中畫素屬於該物件的所有位置均為1,而其他位置為0(這稱為二進位制掩碼)。
另外,當在原始Faster R-CNN架構上執行時沒有修改時,由RoIPool(感興趣區域)選擇的特徵對映區域與原始影象的區域略微錯開。由於影象分割需要畫素級別的特異性,與邊界框不同,這自然會導致不準確。 Mask R-CNN通過調整RoIPool使用稱為Roialign(感興趣區域對齊)的方法更精確地對齊來解決此問題。本質上,RoIAlign使用雙線性插值來避免舍入錯誤,這會導致檢測和分割不準確。
一旦生成這些蒙版,Mask R-CNN將它們與來自Faster R-CNN的分類和邊界框相結合,以生成如此精確的精確分割:
結論
這5種主要的計算機視覺技術可以幫助計算機從單個或一系列影象中提取,分析和理解有用的資訊。還有許多其他我尚未涉及的高階技術,包括樣式轉換,著色,動作識別,3D物件,人體姿勢估計等等。事實上,計算機視覺領域的成本太高,無法深入報道,我鼓勵您進一步探索,無論是通過線上課程,部落格教程還是正式文件。我強烈推薦CS231n作為初學者,因為您將學習實施,訓練和除錯自己的神經網路。作為獎勵,您可以從我的GitHub儲存庫中獲取所有演講幻燈片和分配指南。我希望它會引導你改變如何看待這個世界!