
hand first python 選讀(2)
檔案讀取與異常
檔案讀取與判斷
os模組是呼叫來處理檔案的。
先從最原始的讀取txt檔案開始吧!
新建一個aaa.txt文件,鍵入如下英文名篇:
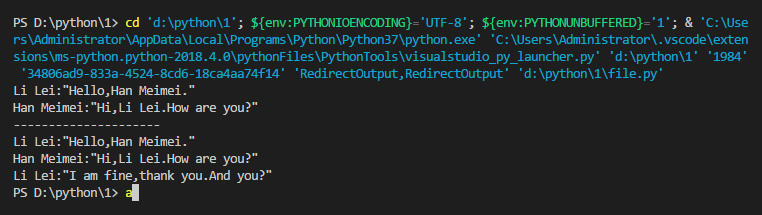
Li Lei:"Hello,Han Meimei."
Han Meimei:"Hi,Li Lei.How are you?"
Li Lei:"I am fine,thank you.And you?"同目錄下建立一個新的file.py文件
import os os.getcwd() data=open('aaa.txt') # 開啟檔案 print(data.readline(),end='') # 讀取檔案 print(data.readline(), end='') data.seek(0) # 又回到最初的起點 for line in data: print(line,end='')
結果如下
如果檔案不存在怎麼辦?
import os
if os.path.exists('aaa.txt'):
# 業務程式碼
else:
print('error:the file is not existed.')split切分
現在我們要把這個橋段轉化為第三人稱的形式
for line in data:
(role,spoken)=line.split(':')
print(role,end='')
print(' said:',end='')
print(spoken,end='')這裡是個極其簡單對話區分。如果我把對話稍微複雜點
。。。
Han Meimei:"There is a question:shall we go to the bed together?"
(pause)
Li Lei:"Oh,let us go to the bed together!"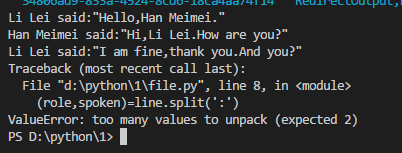
關鍵時刻豈可報錯。
首先發現問題出在冒號,split方法允許第二個引數.
以下例項展示了split()函式的使用方法:
#!/usr/bin/python str = "Line1-abcdef \nLine2-abc \nLine4-abcd"; print str.split( ); print str.split(' ', 1 );以上例項輸出結果如下:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd'] ['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
data = open('aaa.txt')
# 開啟檔案
for line in data:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')取反:not
結果pause解析不了。每一行做多一個判斷。取反用的是not方法,查詢用的是find方法。
Python find() 方法檢測字串中是否包含子字串 str ,如果指定 beg(開始) 和 end(結束) 範圍,則檢查是否包含在指定範圍內,如果包含子字串返回開始的索引值,否則返回-1。
find()方法語法:
str.find(str, beg=0, end=len(string))
考慮這樣寫
for line in data:
if not line.find(':')==-1:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
data.close()關注程式碼本身的目的功能:try...except...捕獲處理異常
劇本里的對話千差萬別,而我只想要人物的對話。不斷增加程式碼複雜度是絕對不明智的。
python遇到程式碼錯誤會以traceback方式告訴你大概出了什麼錯,並中斷處理流程(程式崩了!)。
而try...except...類似try...catch語法,允許程式碼中的錯誤發生,不中斷業務流程。
在上述業務程式碼中我想統一忽略掉所有
只顯示
木有冒號的文字行
可以 這麼寫:
for line in data:
try:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
except:
passpass是python中的null語句,理解為啥也不做。
通過這個語法,忽略處理掉了所有不必要的複雜邏輯。
複雜系統中,aaa.txt可能是不存在的,你固然可以用if讀取,還有一個更激進(先進)的寫法:
import os
try:
data = open('aaa.txt')
# 開啟檔案
for line in data:
try:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
except:
pass
except:
print('error:could not read the file.')兩種邏輯是不一樣的,上述是無法讀取(可能讀取出錯),if是路徑不存在。於是引發了最後一個問題。
錯誤型別指定
過於一般化的程式碼,總是不能很好地判斷就是是哪出了錯。try語句無法判斷:究竟是檔案路徑不對還是別的問題
import os
try:
data = open('aaa.txt')
# 開啟檔案
for line in data:
try:
(role,spoken)=line.split(':',1)
print(role,end='')
print(' said:',end='')
print(spoken,end='')
except ValueError:
# 引數出錯
pass
except IOError:
# 輸入輸出出錯
print('error:could not find the file.')python中異常物件有很多,可自行查閱。
資料不符合期望格式:ValueError
IOError:路徑出錯
資料儲存到檔案
業務程式碼工作流程可以儲存到檔案中儲存下來。下面先看一個需求:
- 分別建立一個名為lilei和hanmeimei的空列表
- 刪除一個line裡面的換行符(replace方法和js中幾乎一樣。去除左右空格用
strip方法)- 給出條件和程式碼,根據role的值將line新增到適當的列表中
- 輸出各自列表。
簡單說就是一個條件查詢的實現。
try:
data = open('aaa.txt')
lilei = []
hanmeimei = []
for line in data:
try:
(role, spoken) = line.split(':', 1)
spoken = spoken.replace('\n', '')
if role == 'Li Lei':
lilei.append(spoken)
else:
hanmeimei.append(spoken)
except ValueError:
pass
data.close()
except IOError:
print('error:the file is not found.')
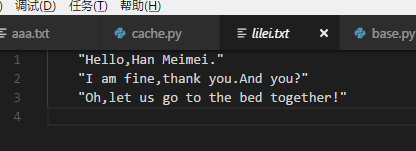
print(lilei)
print(hanmeimei)很簡單。
寫模式:open('bbb.txt',w')
open方法預設為讀模式open('bbb.txt','r'),寫模式對因為open('bbb.txt','w')。
在同目錄下建立一個bbb.txt
寫入檔案可以用以下命令:
out = open('bbb.txt', 'w')
print('we are who we are.', file=out)
out.close()| 檔案訪問模式 | 釋義 |
|---|---|
| r | 讀取,是為預設模式 |
| w | 開啟一個檔案,覆寫檔案內容,如沒有則建立。 |
| w+ | 讀取和追加寫入(不清除) |
| a | 追加寫入 |
開啟的檔案必須執行關閉!
好了,介紹完知識之後可以在上一節程式碼中分別寫入檔案吧
try:
data = open('aaa.txt')
lilei = []
hanmeimei = []
for line in data:
try:
(role, spoken) = line.split(':', 1)
spoken = spoken.strip()
if role == 'Li Lei':
lilei.append(spoken)
else:
hanmeimei.append(spoken)
except ValueError:
pass
data.close()
try:
_lilei = open('lilei.txt', 'w')
_hanmeimei = open('hanmeimei.txt', 'w')
print(lilei,file=_lilei)
print(hanmeimei,file=_hanmeimei)
_lilei.close()
_hanmeimei.close()
print('works completed.')
except IOError:
print('file error.')
except IOError:
print('error:the file is not found.')測試成功,但以上程式碼有個問題:我需要無論IOError都執行一套程式碼。並且在檔案建立後關閉
擴充套件try語句
當我嘗試以read模式開啟一個檔案,:
try:
data = open('lilei.txt')
except IOError as err:
print('file error.'+str(err))
finally:
if 'data' in locals():
_lilei.close()
print('works completed.')- finally:無論是否執行成功都執行的程式碼。
- locals():告訴你檔案是否成功被建立並開啟。
- as xxx:為異常物件命名,並且通過str()轉化為字元以便列印,也是一個賦值過程
實在太麻煩了。
with語句
with語句利用了一個上下文管理協議。有了它就不用些finally了。
目前為止條件查詢的方案是這樣的
# ...
try:
_lilei = open('lilei.txt','w')
_hanmeimei = open('hanmeimei.txt','w')
print(lilei, file=_lilei)
print(hanmeimei, file=_hanmeimei)
except IOError as err:
print('file error.'+str(err))
finally:
if '_lilei' in locals():
_lilei.close()
if '_hanmeimei' in locals():
_hanmeimei.close()
print('works completed.')
except IOError:
print('error:the file is not found.')用with重寫之後:
try:
with open('lilei.txt','w') as _lilei:
print(lilei, file=_lilei)
with open('hanmeimei.txt','w') as _hanmeimei:
print(hanmeimei, file=_hanmeimei)
print('works completed.')
except IOError as err:
print('file error.'+str(err))寫好之後就非常簡潔了。
因地制宜選擇輸出樣式
對於列表資料來說,直接存字串是很不合適的。現在我要把第二章中的flatten加進來並加以改造。
# base.py
def flatten(_list, count=False, level=0):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item,count,level+1)
else:
if count:
for step in range(level):
print("\t", end='')
print(_list)
else:
print(_list)需求:向flatten新增第四個引數,標識資料寫入的位置,並允許預設。
# base.py
def flatten(_list, count=False, level=0,_file=False):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item,count,level+1,_file)
else:
if count:
for step in range(level):
print("\t", end='',file=_file)
print(_list,file=_file)
else:
print(_list)呼叫
import base as utils
try:
data = open('aaa.txt')
lilei = []
hanmeimei = []
for line in data:
try:
(role, spoken) = line.split(':', 1)
spoken = spoken.strip()
if role == 'Li Lei':
lilei.append(spoken)
else:
hanmeimei.append(spoken)
except ValueError:
pass
data.close()
try:
with open('lilei.txt','w') as _lilei:
utils.flatten(lilei,True,0,_lilei)
with open('hanmeimei.txt','w') as _hanmeimei:
utils.flatten(hanmeimei, True, 0, _hanmeimei)
print('works completed.')
except IOError as err:
print('file error.'+str(err))
except IOError:
print('error:the file is not found.')輸出成功
把格局拉高點吧,這仍然是一個高度定製化的程式碼。
pickle庫的使用
pickle庫介紹
pickle是python語言的一個標準模組,安裝python後已包含pickle庫,不需要單獨再安裝。
pickle模組實現了基本的資料序列化和反序列化。通過pickle模組的序列化操作我們能夠將程式中執行的物件資訊儲存到檔案中去,永久儲存;通過pickle模組的反序列化操作,我們能夠從檔案中建立上一次程式儲存的物件。
一、記憶體中操作:
import pickle #dumps 轉化為二進位制檔案 li = [11,22,33] r = pickle.dumps(li) print(r) #loads 將二進位制資料編譯出來 result = pickle.loads(r) print(result)二、檔案中操作:
#dump:以二進位制形式開啟(讀取:rb,寫入wb)檔案 li = [11,22,33] pickle.dump(li,open('db','wb')) #load ret = pickle.load(open('db','rb')) print(ret)
把二進位制檔案寫入檔案中:
try:
with open('lilei.txt','wb') as _lilei:
# utils.flatten(lilei,True,0,_lilei)
pickle.dump(lilei,_lilei)
with open('hanmeimei.txt','wb') as _hanmeimei:
# utils.flatten(hanmeimei, True, 0, _hanmeimei)
pickle.dump(hanmeimei,_hanmeimei)
print('works completed.')
except IOError as err:
print('file error.'+str(err))
except pickle.PickleError as pError:
print('err:'+str(pError))資料已經被寫入。

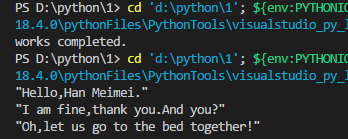
舉例說:如何開啟lileii.txt並正確編譯呢?
new_lilei=[]
try:
with open('lilei.txt','rb') as _new_lilei:
new_lilei = pickle.load(_new_lilei)
print(utils.flatten(new_lilei))
except IOError as io:
print('err:'+str(io))
except pickle.PickleError as pError:
print('pickleError'+str(pError))
測試成功。
用pickle的通用io才是上策。