
HDFS的架構及原理
HDFS(Hadoop Distributed File System)是Hadoop核心組成之一,是分散式計算中資料儲存管理的基礎,被設計成適合執行在通用硬體上的分散式檔案系統。HDFS架構中有兩類節點,一類是NameNode,又叫“元資料節點”,另一類是DataNode,又叫“資料節點”,分別執行Master和Worker的具體任務。
HDFS是一個(Master/Slave)體系結構,“一次寫入,多次讀取”。HDFS的設計思想:分而治之—將大檔案、大批量檔案分散式存放在大量獨立的機器上。
一、HDFS的優缺點
優點:
1、高容錯性。資料儲存多個副本,通過增加副本的形式提高容錯性,某個副本丟失後,它可以通過其它副本自動恢復。
2、適合大批量資料處理。處理達到GB、TB,甚至PB級別的資料,處理百萬規模以上的檔案數量,處理10K節點的規模。
3、流式檔案訪問。一次寫入多次讀取,檔案一旦寫入不能修改,只能追加,保證資料一致性。
4、可構建在廉價機器上。通過多副本機制提高可靠性,提供容錯和恢復機制。
缺點(不適用HDFS的場景):
1、低延時資料訪問。做不到毫秒級儲存資料,但是適合高吞吐率(某一時間內寫入大量的資料)的場景。
2、小檔案儲存。儲存大量小檔案會佔用NameNode大量的記憶體來儲存檔案、目錄和塊資訊。
3、併發寫入、隨機讀寫。一個檔案不允許多個執行緒同時寫,僅支援資料追加,不支援檔案的隨機修改。
二、HDFS儲存架構
資料儲存架構圖:
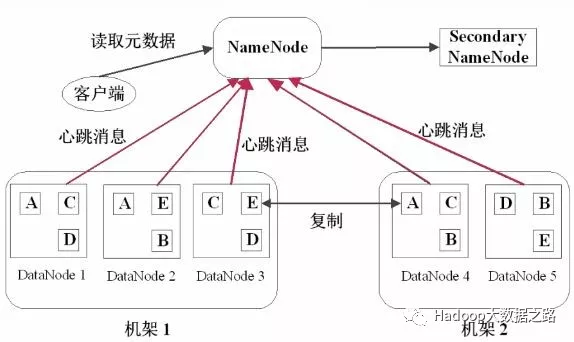
HDFS採用Master/Slave的架構儲存資料,由HDFS Client、NameNode、DataNode和Secondary NameNode四部分組成。
Client:客戶端
1、檔案切分。檔案上傳HDFS時,Client按照Block大小切分檔案,然後進行儲存
2、與NameNode互動,獲取檔案位置資訊
3、與DataNode互動,讀取或寫入資料
4、Client提供一些命令管理和訪問HDFS
NameNode:Master(管理者)
1、管理HDFS的名稱空間
2、管理資料塊(Block)對映資訊
3、配置副本策略
4、處理客戶端讀寫請求
DataNode:Slave(NN下達命令執行實際的操作)
1、儲存實際的資料塊
2、執行資料塊的讀/寫操作
Secondary NameNode:並非NameNode的熱備,當NN停止服務時,它並不能馬上替換NN並提供服務
1、輔助NN,分擔其工作量
2、定期合併fsimage和fsedits,並推送給NN
3、在緊急情況下,可輔助恢復NN
三、HDFS資料讀寫
檔案讀取步驟:
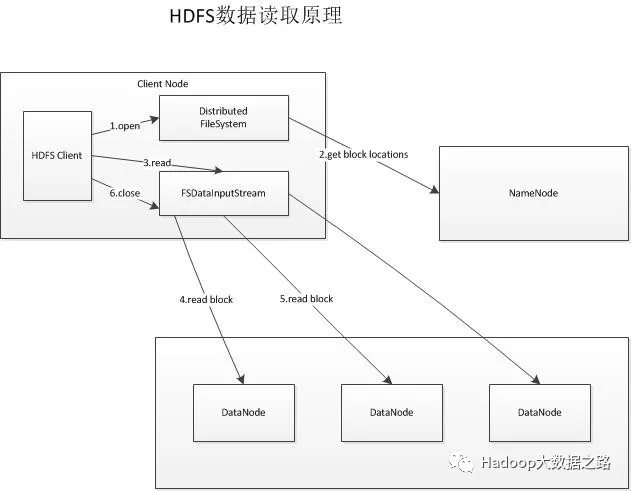
1、首先呼叫FileSystem的open方法獲取一個DistributedFileSystem例項。
2、DistributedFileSystem通過RPC(遠端過程呼叫)獲得檔案的第一批block的locations,同一個block按照重複數返回多個locations,這些locations按照Hadoop拓撲結構排序,按照就近原則進行排序。
3、前兩步結束後會返回一個FSDataInputStream物件,通過呼叫read方法時,該物件會找出離客戶端最近的DataNode並連線。
4、資料從DataNode源源不斷地流向客戶端。
5、如果第一個block塊資料讀取完成,就會關閉指向第一個block塊的DataNode連線,接著讀取下一個block塊。
6、如果第一批blocks讀取完成,FSDataInputStream會向NN獲取下一批blocks的locations,然後重複4、5步驟,直到所有blocks讀取完成,這時就會關閉所有的流。
檔案寫入步驟:
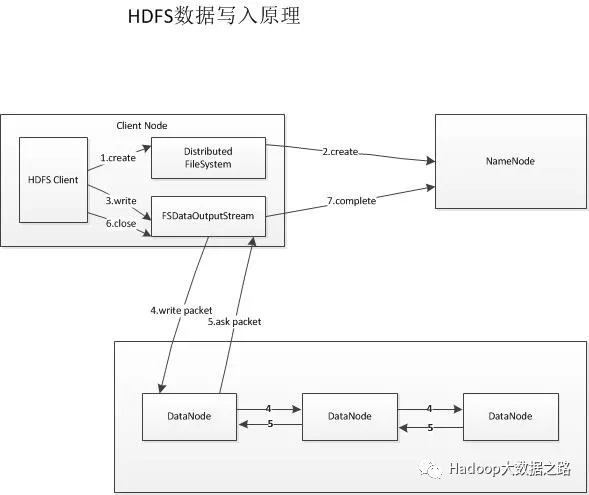
1、客戶端通過呼叫DistributedFileSystem的create方法,建立一個新檔案。
2、DistributedFileSystem通過RPC(遠端過程呼叫)呼叫NameNode,去建立一個沒有blocks關聯的新檔案。建立前,NN會進行各種校驗,如果校驗通過,NN就會記錄下新檔案,否則丟擲I/O異常。
3、前兩步結束後會返回一個FSDataOutputStream物件,客戶端開始寫資料到FSDataOutputStream,FSDataOutputStream會把資料切成一個個小packet,然後排成data queue。
4、DataStreamer 會去處理接受 data queue,它先問詢 NameNode 這個新的 block 最適合儲存的在哪幾個DataNode裡,比如重複數是3,那麼就找到3個最適合的 DataNode,把它們排成一個 pipeline。DataStreamer 把 packet 按佇列輸出到管道的第一個 DataNode 中,第一個 DataNode又把 packet 輸出到第二個 DataNode 中,以此類推。
5、DFSOutputStream 還有一個佇列叫 ack queue,也是由 packet 組成,等待DataNode的收到響應,當pipeline中的所有DataNode都表示已經收到的時候,這時akc queue才會把對應的packet包移除掉。
6、客戶端完成寫資料後,呼叫close方法關閉寫入流。
7、DataStreamer 把剩餘的包都刷到 pipeline 裡,然後等待 ack 資訊,收到最後一個 ack 後,通知 NameNode 把檔案標示為已完成。
RackAware機架感知功能:
1、若client為DataNode節點,那儲存block時,規則為:副本1儲存在同client的節點上;副本2儲存在不同機架節點上;副本3同第副本2機架的另外一個節點上;其它副本隨機挑選。
2、若client不為DataNode節點,那儲存block時,規則為:副本1隨機選擇一個節點;副本2儲存在不同於副本1的機架節點;副本3同副本2所在機架的另一個節點;其它副本隨機挑選。
