
爬取虎嗅 5 萬篇文章告訴你怎麼樣取標題
摘要: 不少時候,一篇文章能否得到廣泛的傳播,除了文章本身實打實的質量以外,一個好的標題也至關重要。本文爬取了虎嗅網建站至今共 5 萬條新聞標題內容,助你找到起文章標題的技巧與靈感。同時,分享一些值得關注的文章和作者。
1. 分析背景
1.1. 為什麼選擇「虎嗅」
在眾多新媒體網站中,「虎嗅」網的文章內容和質量還算不錯。在「新榜」科技類公眾號排名中,它位居榜單第 3 名,還是比較受歡迎的。所以選擇爬取該網站的文章資訊,順便從中瞭解一下這幾年科技網際網路都出現了哪些熱點資訊。
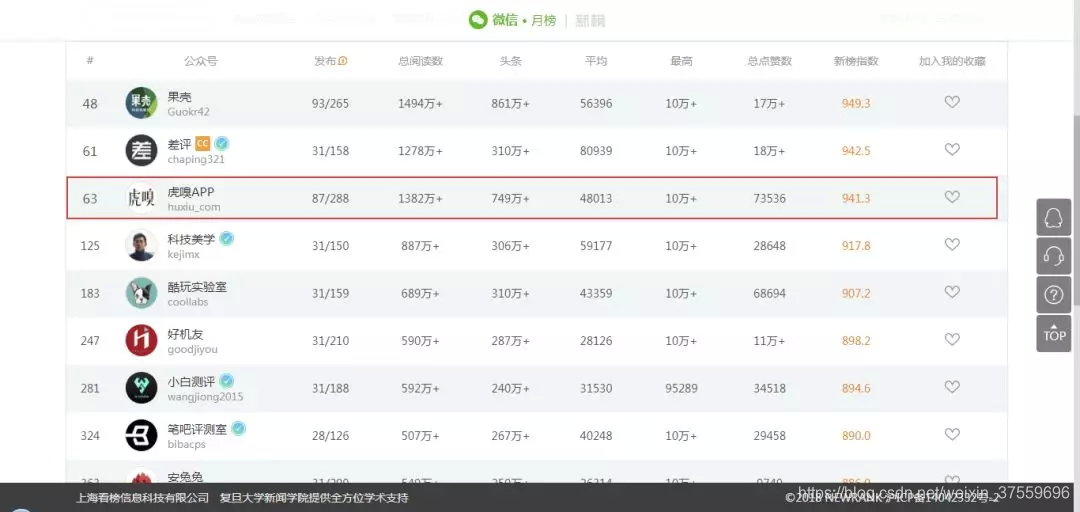
「關於虎嗅」
虎嗅網創辦於 2012 年 5 月,是一個聚合優質創新資訊與人群的新媒體平臺。該平臺專注於貢獻原創、深度、犀利優質的商業資訊,圍繞創新創業的觀點進行剖析與交流。虎嗅網的核心,是關注網際網路及傳統產業的融合、明星公司的起落軌跡、產業潮汐的動力與趨勢。
1.2. 分析內容
- 分析虎嗅網 5 萬篇文章的基本情況,包括收藏數、評論數等
- 發掘最受歡迎和最不受歡迎的文章及作者
- 分析文章標題形式(長度、句式)與受歡迎程度之間的關係
- 展現近些年科技網際網路行業的熱門詞彙
1.3. 分析工具
- Python 3.6
- pyspider
- MongoDB
- Matplotlib
- WordCloud
- Jieba
2. 資料抓取
使用 pyspider 抓取了虎嗅網的主頁文章,文章抓取時期為 2012 年建站至 2018 年 11 月 1 日,共計約 5 萬篇文章。抓取 了 7 個欄位資訊:文章標題、作者、發文時間、評論數、收藏數、摘要和文章連結。
2.1. 目標網站分析
這是要爬取的 網頁介面,可以看到是通過 AJAX 載入的。
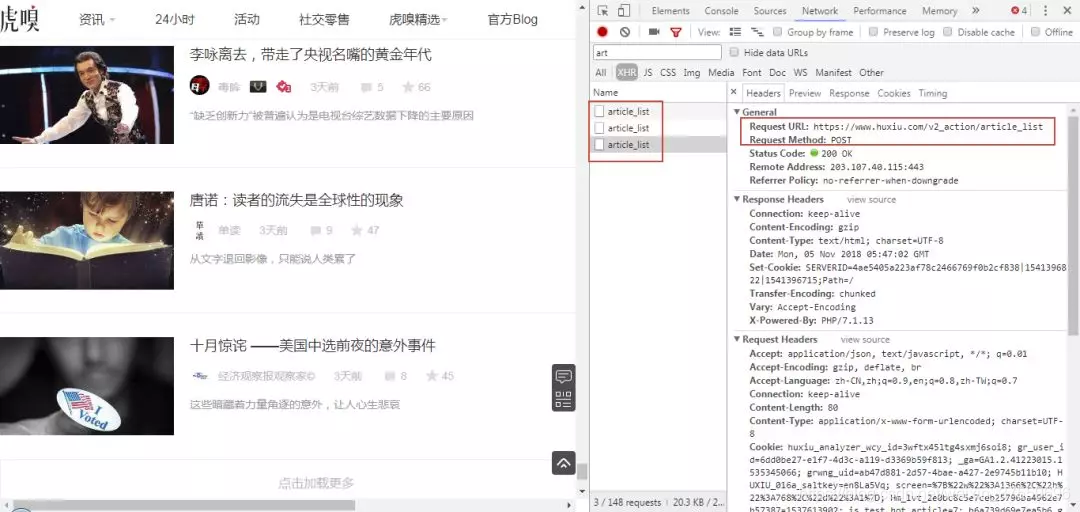
右鍵開啟開發者工具檢視翻頁規律,可以看到 URL 請求是 POST 型別,下拉到底部檢視 Form Data,表單需提交引數只有 3 項。經嘗試, 只提交 page 引數就能成功獲取頁面的資訊,其他兩項引數無關緊要,所以構造分頁爬取非常簡單。
1 huxiu_hash_code: 39bcd9c3fe9bc69a6b682343ee3f024a
2 page: 4
3 last_dateline: 1541123160
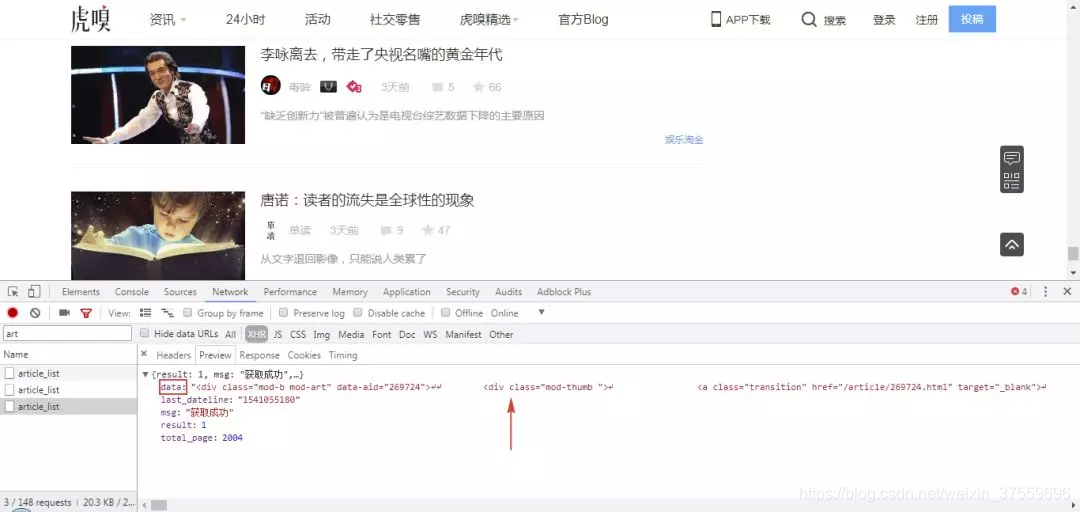
接著,切換選項卡到 Preview 和 Response 檢視網頁內容,可以看到資料都位於 data 欄位裡。total_page 為 2004,表示一共有 2004 頁的文章內容,每一頁有 25 篇文章,總共約 5 萬篇,也就是我們要爬取的數量。
2.2. pyspider 介紹
和之前文章不同的是,這裡我們使用一種新的工具來進行爬取,叫做:pyspider 框架。由國人 binux 大神開發,GitHub Star 數超過 12 K,足以證明它的知名度。可以說,學習爬蟲不能不會使用這個框架。
網上關於這個框架的介紹和實操案例非常多,這裡僅簡單介紹一下。
我們之前的爬蟲都是在 Sublime 、PyCharm 這種 IDE 視窗中執行的,整個爬取過程可以說是處在黑箱中,內部執行的些細節並不太清楚。而 pyspider 一大亮點就在於提供了一個視覺化的 WebUI 介面,能夠清楚地檢視爬蟲的執行情況。
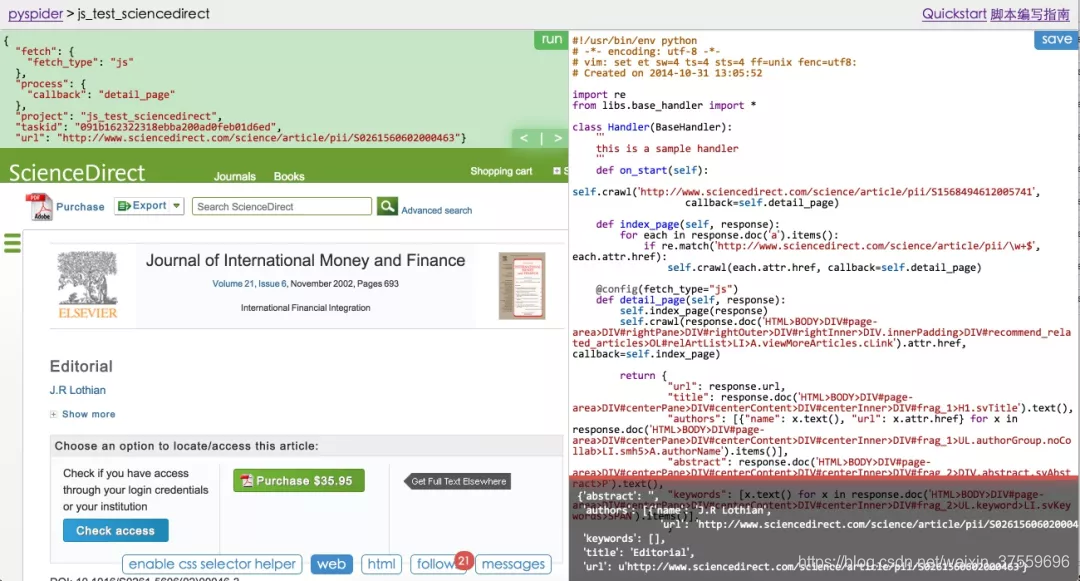
pyspider 的架構主要分為 Scheduler(排程器)、Fetcher(抓取器)、Processer(處理器)三個部分。Monitor(監控器)對整個爬取過程進行監控,Result Worker(結果處理器)處理最後抓取的結果。
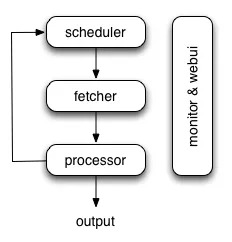
該框架比較容易上手,網頁右邊是程式碼區,先定義類(Class)然後在裡面新增爬蟲的各種方法(也可以稱為函式),執行的過程會在左上方顯示,左下方則是輸出結果的區域。
這裡,分享幾個不錯的教程以供參考:
官方主頁:http://docs.pyspider.org/en/latest/
pyspider 爬蟲原理剖析:http://python.jobbole.com/81109/
pyspider 爬淘寶圖案例實操:https://cuiqingcai.com/2652.html
安裝好該框架並大概瞭解用法後,下面我們可以就開始爬取了。
2.3. 抓取資料
CMD 命令視窗執行:pyspider all 命令,然後瀏覽器輸入:http://localhost:5000/ 就可以啟動 pyspider 。
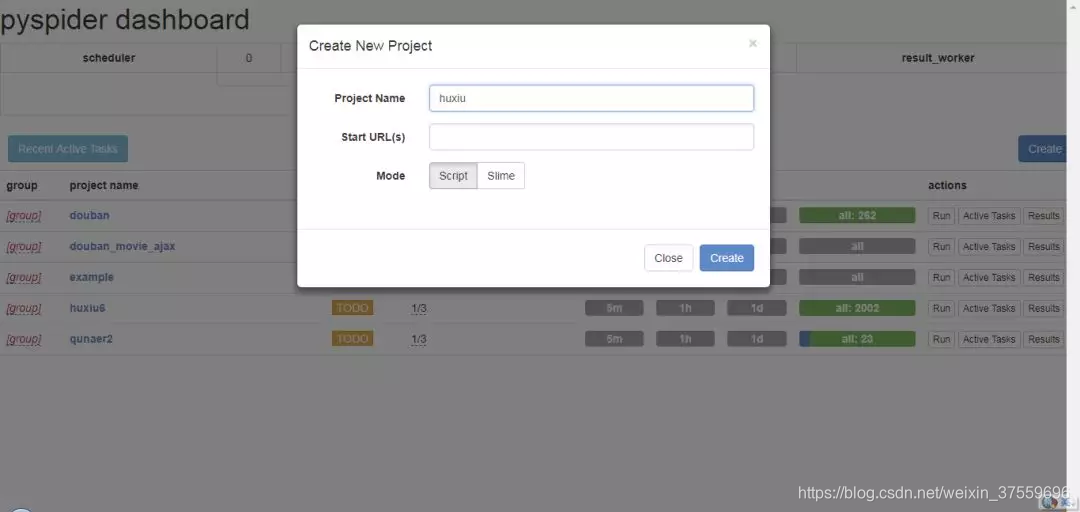
點選 Create 新建一個專案,Project Name 命名為:huxiu,因為要爬取的 URL 是 POST 型別,所以這裡可以先不填寫,之後可以在程式碼中新增,再次點選 Creat 便完成了該專案的新建。
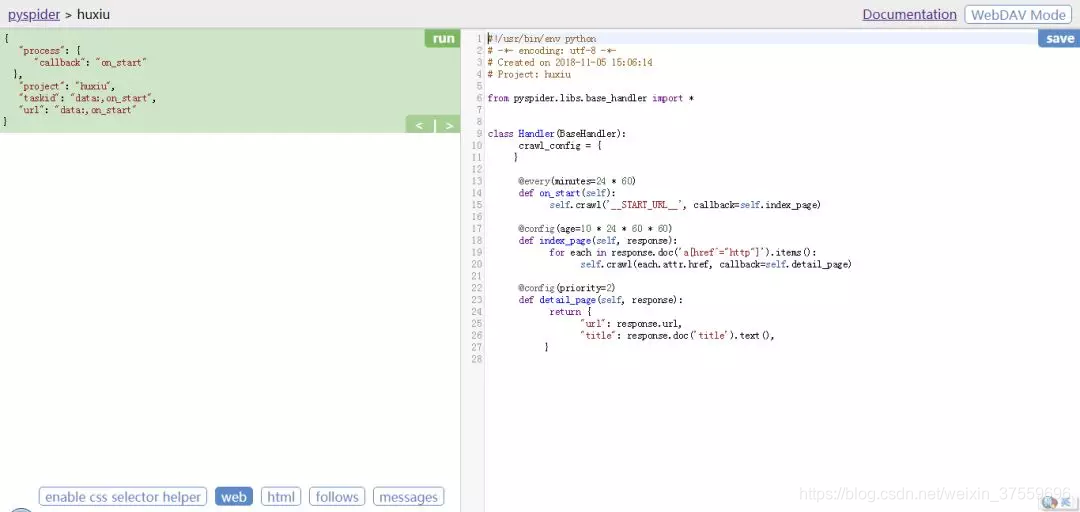
新專案建立好後會自動生成一部分模板程式碼,我們只需在此基礎上進行修改和完善,然後就可以執行爬蟲專案了。現在,簡單梳理下程式碼編寫步驟。
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config:{
"headers":{
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
}
def on_start(self):
for page in range(2,3): # 先迴圈1頁
print('正在爬取第 %s 頁' % page)
self.crawl('https://www.huxiu.com/v2_action/article_list',method='POST',data={'page':page}, callback=self.index_page)
這裡,首先定義了一個 Handler 主類,整個爬蟲專案都主要在該類下完成。 接著,可以將爬蟲基本的一些基本配置,比如 Headers、代理等設定寫在下面的 crawl_config 屬性中。
如果你還沒有習慣從函式(def)轉換到類(Class)的程式碼寫法,那麼需要先了解一下類的相關知識,之後我也會單獨用一篇文章介紹一下。
下面的 on_start() 方法是程式的入口,也就是說程式啟動後會首先從這裡開始執行。首先,我們將要爬取的 URL傳入 crawl() 方法,同時將 URL 修改成虎嗅網的:https://www.huxiu.com/v2_action/article_list。
由於 URL 是 POST 請求,所以我們還需要增加兩個引數:method 和 data。method 表示 HTTP 請求方式,預設是 GET,這裡我們需要設定為 POST;data 是 POST 請求表單引數,只需要新增一個 page 引數即可。
接著,通過 callback 引數定義一個 index_page() 方法,用來解析 crawl() 方法爬取 URL 成功後返回的 Response 響應。在後面的 index_page() 方法中,可以使用 PyQuery 提取響應中的所需內容。具體提取方法如下:
import json
from pyquery import PyQuery as pq
def index_page(self, response):
content = response.json['data']
# 注意,在sublime中,json後面需要新增(),pyspider 中則不用
doc = pq(content)
lis = doc('.mod-art').items()
data = [{
'title': item('.msubstr-row2').text(),
'url':'https://www.huxiu.com'+ str(item('.msubstr-row2').attr('href')),
'name': item('.author-name').text(),
'write_time':item('.time').text(),
'comment':item('.icon-cmt+ em').text(),
'favorites':item('.icon-fvr+ em').text(),
'abstract':item('.mob-sub').text()
} for item in lis ] # 列表生成式結果返回每頁提取出25條字典資訊構成的list
print(data)
return data
這裡,網頁返回的 Response 是 json 格式,待提取的資訊存放在其中的 data 鍵值中,由一段 HTML 程式碼構成。我們可以使用 response.json[‘data’] 獲取該 HTML 資訊,接著使用 PyQuery 搭配 CSS 語法提取出文章標題、連結、作者等所需資訊。這裡使用了列表生成式,能夠精簡程式碼並且轉換為方便的 list 格式,便於後續儲存到 MongoDB 中。
我們輸出並檢視一下第 2 頁的提取結果:
# 由25個 dict 構成的 list
[{'title': '想要長生不老?殺死體內的“殭屍細胞”吧', 'url': 'https://www.huxiu.com/article/270086.html', 'name': '造就Talk', 'write_time': '19小時前', 'comment': '4', 'favorites': '28', 'abstract': '如果有了最終療法,也不應該是每天都需要接受治療'},
{'title': '日本步入下流社會,我們還在買買買', 'url': 'https://www.huxiu.com/article/270112.html', 'name': '騰訊《大家》©', 'write_time': '20小時前', 'comment': '13', 'favorites': '142', 'abstract': '我買,故我在'}
...
]
可以看到,成功得到所需資料,然後就可以儲存了,可以選擇輸出為 CSV、MySQL、MongoDB 等方式,這裡我們選擇儲存到 MongoDB 中。
import pandas as pd
import pymongo
import time
import numpy as np
client = pymongo.MongoClient('localhost',27017)
db = client.Huxiu
mongo_collection = db.huxiu_news
def on_result(self,result):
if result:
self.save_to_mongo(result)
def save_to_mongo(self,result):
df = pd.DataFrame(result)
#print(df)
content = json.loads(df.T.to_json()).values()
if mongo_collection.insert_many(content):
print('儲存到 mongondb 成功')
# 隨機暫停
sleep = np.random.randint(1,5)
time.sleep(sleep)
上面,定義了一個 on_result() 方法,該方法專門用來獲取 return 的結果資料。這裡用來接收上面 index_page() 返回的 data 資料,在該方法裡再定義一個儲存到 MongoDB 的方法就可以儲存到 MongoDB 中。
關於資料如何儲存到 MongoDB 中,我們在之前的一篇文章中有過介紹,如果忘記了可以回顧一下。
下面,我們來測試一下整個爬取和儲存過程。點選左上角的 run 就可以順利執行單個網頁的抓取、解析和儲存,結果如下:
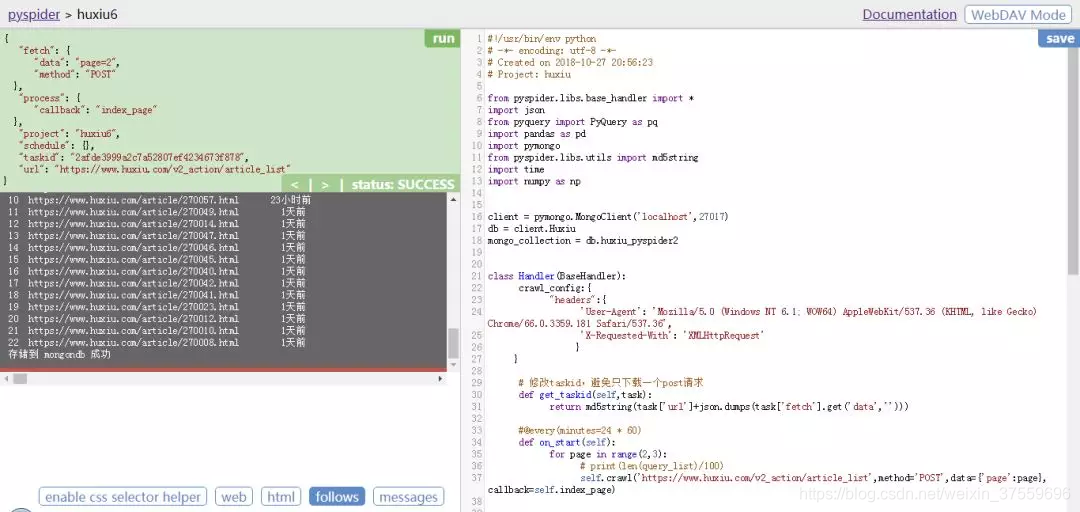
上面完成了單頁面的爬取,接下來,我們需要爬取全部 2000 餘頁內容。
需要修改兩個地方,首先在 on_start() 方法中將 for 迴圈頁數 3 改為 2002。改好以後,如果我們直接點選 run ,會發現還是隻能爬取第 2 頁的結果。
這是因為,pyspider 以 URL的 MD5 值作為 唯一 ID 編號,ID 編號相同的話就視為同一個任務,便不會再重複爬取。由於 GET 請求的 分頁URL 通常是有差異的,所以 ID 編號會不同,也就自然能夠爬取多頁。但這裡 POST 請求的分頁 URL 是相同的,所以爬完第 2 頁,後面的頁數便不會再爬取。
那有沒有解決辦法呢? 當然是有的,我們需要重新寫下 ID 編號的生成方式,方法很簡單,在 on_start() 方法前面新增下面 2 行程式碼即可:
def get_taskid(self,task):
return md5string(task['url']+json.dumps(task['fetch'].get('data','')))
這樣,我們再點選 run 就能夠順利爬取 2000 頁的結果了,我這裡一共抓取了 49,996 條結果,耗時 2 小時左右完成。
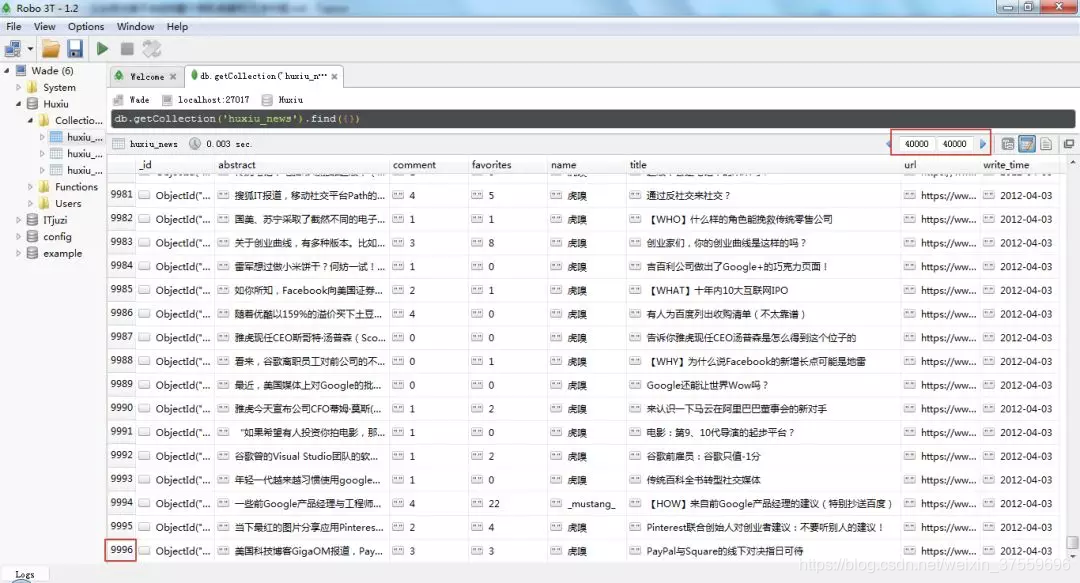
以上,就完成了資料的獲取。有了資料我們就可以著手分析,不過這之前還需簡單地進行一下資料的清洗、處理。
3. 資料清洗處理
首先,我們需要從 MongoDB 中讀取資料,並轉換為 DataFrame。
client = pymongo.MongoClient(host='localhost', port=27017)
db = client['Huxiu']
collection = db['huxiu_news']
# 將資料庫資料轉為DataFrame
data = pd.DataFrame(list(collection.find()))
下面我們看一下資料的總體情況,可以看到資料的維度是 49996 行 × 8 列。發現多了一列無用的 _id 需刪除,同時 name 列有一些特殊符號,比如© 需刪除。另外,資料格式全部為 Object 字串格式,需要將 comment 和 favorites 兩列更改為數值格式、 write_time 列更改為日期格式。
print(data.shape) # 檢視行數和列數
print(data.info()) # 檢視總體情況
3print(data.head()) # 輸出前5行
# 結果:
(49996, 8)
Data columns (total 8 columns):
_id 49996 non-null object
abstract 49996 non-null object
comment 49996 non-null object
favorites 49996 non-null object
name 49996 non-null object
title 49996 non-null object
url 49996 non-null object
write_time 49996 non-null object
dtypes: object(8)
_id abstract comment favorites name title url write_time
0 5bdc2 “在你們看到… 22 50 普象工業設計小站© 看了蘋果屌 https:// 10小時前
1 5bdc2 中國”綠卡”號稱“世界最難拿” 9 16 經濟觀察報© 遞交材料厚 https:// 10小時前
2 5bdc2 鮮衣怒馬少年時 2 13 小馬宋 金庸小說陪 https:// 11小時前
3 5bdc2 預告還是預警? 3 10 Cuba Libre 阿里即將發 https:// 11小時前
4 5bdc2 庫克:咋回事? 2 3 Cuba Libre 【虎嗅早報 https:// 11小時前
程式碼實現如下:
# 刪除無用_id列
data.drop(['_id'],axis=1,inplace=True)
# 替換掉特殊字元©
data['name'].replace('©','',inplace=True,regex=True)
# 字元更改為數值
data = data.apply(pd.to_numeric,errors='ignore')
# 更該日期格式
data['write_time'] = data['write_time'].replace('.*前','2018-10-31',regex=True)
# 為了方便,將write_time列,包含幾小時前和幾天前的行,都替換為10月31日最後1天。
data['write_time'] = pd.to_datetime(data['write_time'])
下面,我們看一下資料是否有重複,如果有,那麼需要刪除。
# 判斷整行是否有重複值
print(any(data.duplicated()))
# 顯示True,表明有重複值,進一步提取出重複值數量
data_duplicated = data.duplicated().value_counts()
print(data_duplicated) # 顯示2 True ,表明有2個重複值
# 刪除重複值
data = data.drop_duplicates(keep='first')
# 刪除部分行後,index中斷,需重新設定index
data = data.reset_index(drop=True)
#結果:
True
False 49994
True 2
然後,我們再增加兩列資料,一列是文章標題長度列,一列是年份列,便於後面進行分析。
data['title_length'] = data['title'].apply(len)
data['year'] = data['write_time'].dt.year
Data columns (total 9 columns):
abstract 49994 non-null object
comment 49994 non-null int64
favorites 49994 non-null int64
name 49994 non-null object
title 49994 non-null object
url 49994 non-null object
write_time 49994 non-null datetime64[ns]
title_length 49994 non-null int64
year 49994 non-null int64
以上,就完成了基本的資料清洗處理過程,針對這 9 列資料可以開始進行分析了。
4. 描述性資料分析
通常,資料分析主要分為四類: 「描述型分析」、「診斷型分析」「預測型分析」「規範型分析」。「描述型分析」是用來概括、表述事物整體狀況以及事物間關聯、類屬關係的統計方法,是這四類中最為常見的資料分析型別。通過統計處理可以簡潔地用幾個統計值來表示一組資料地集中性(如平均值、中位數和眾數等)和離散型(反映資料的波動性大小,如方差、標準差等)。
這裡,我們主要進行描述性分析,資料主要為數值型資料(包括離散型變數和連續型變數)和文字資料。
4.1. 總體情況
先來看一下總體情況。
print(data.describe())
comment favorites title_length
count 49994.000000 49994.000000 49994.000000
mean 10.860203 34.081810 22.775333
std 24.085969 48.276213 9.540142
min 0.000000 0.000000 1.000000
25% 3.000000 9.000000 17.000000
50% 6.000000 19.000000 22.000000
75% 12.000000 40.000000 28.000000
max 2376.000000 1113.000000 224.000000
這裡,使用了 data.describe() 方法對數值型變數進行統計分析。從上面可以簡要得出以下幾個結論:
- 讀者的評論和收藏熱情都不算太高。大部分文章(75 %)的評論數量為十幾條,收藏數量不過幾十個。這和一些微信大 V 公眾號動輒百萬級閱讀、數萬級評論和收藏量相比,虎嗅網的確相對小眾一些。不過也正是因為小眾,也才深得部分人的喜歡。
- 評論數最多的文章有 2376 條,收藏數最多的文章有 1113 個收藏量,說明還是有一些潛在的比較火或者質量比較好的文章。
- 最長的文章標題長達 224 個字,大部分文章標題長度在 20 來個字左右,所以 標題最好不要太長或過短。
對於非數值型變數(name、write_time),使用 describe() 方法會產生另外一種彙總統計。
print(data['name'].describe())
print(data['write_time'].describe())
# 結果:
count 49994
unique 3162
top 虎嗅
freq 10513
Name: name, dtype: object
count 49994
unique 2397
top 2014-07-10 00:00:00
freq 274
first 2012-04-03 00:00:00
last 2018-10-31 00:00:00
unique 表示唯一值數量,top 表示出現次數最多的變數,freq 表示該變量出現的次數,所以可以簡單得出以下幾個結論:
- 在文章來源方面,3162 個作者貢獻了這 5 萬篇文章,其中自家官網「虎嗅」寫的數量最多,超過了 1 萬篇,這也很自然。
- 在文章發表時間方面,最早的一篇文章來自於 2012年 4 月 3 日。 6 年多時間,發文數最多的 1 天 是 2014 年 7 月 10 日,一共發了 274 篇文章。
4.2. 不同時期文章釋出的數量變化
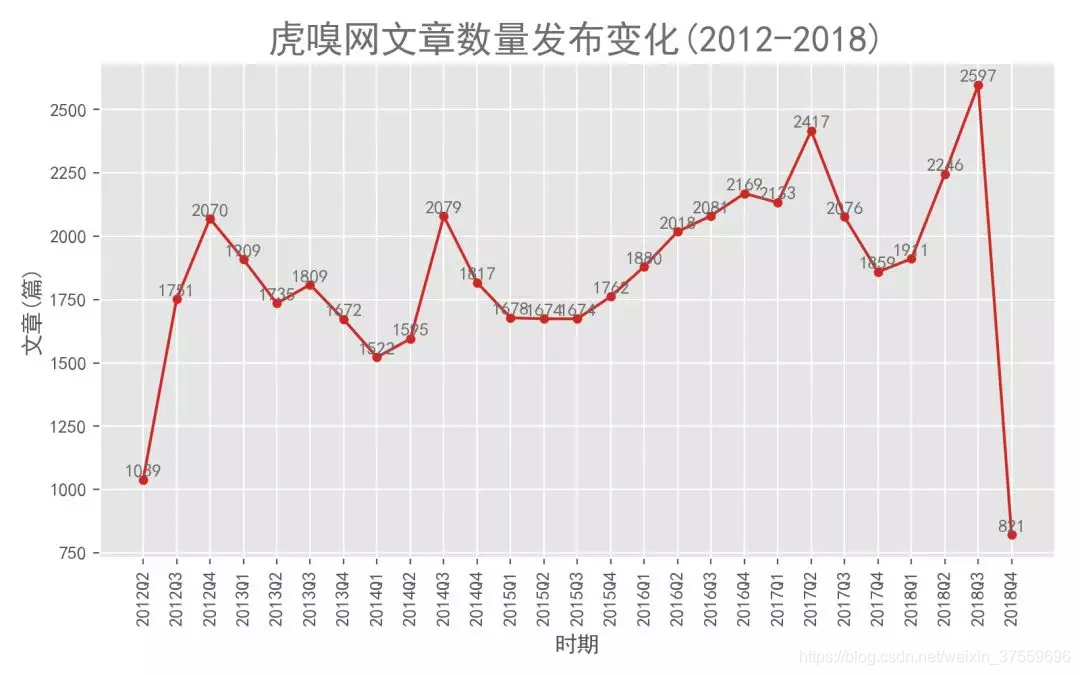
可以看到 ,以季度為時間尺度的 6 年間,前幾年發文數量比較穩定,大概在1750 篇左右,個別季度數量激增到 2000 篇以上。2016 年之後文章開始增加到 2000 篇以上,可能跟網站知名度提升有關。首尾兩個季度日期不全,所以數量比較少。
具體程式碼實現如下:
def analysis1(data):
# # 彙總統計
# print(data.describe())
# print(data['name'].describe())
# print(data['write_time'].describe())
data.set_index(data['write_time'],inplace=True)
data = data.resample('Q').count()['name'] # 以季度彙總
data = data.to_period('Q')
# 建立x,y軸標籤
x = np.arange(0,len(data),1)
ax1.plot(x,data.values, #x、y座標
color = color_line , #折線圖顏色為紅色
marker = 'o',markersize = 4 #標記形狀、大小設定
)
ax1.set_xticks(x) # 設定x軸標籤為自然數序列
ax1.set_xticklabels(data.index) # 更改x軸標籤值為年份
plt.xticks(rotation=90) # 旋轉90度,不至太擁擠
for x,y in zip(x,data.values):
plt.text(x,y + 10,'%.0f' %y,ha = 'center',color = colors,fontsize=fontsize_text )
# '%.0f' %y 設定標籤格式不帶小數
# 設定標題及橫縱座標軸標題
plt.title('虎嗅網文章數量釋出變化(2012-2018)',color = colors,fontsize=fontsize_title)
plt.xlabel('時期')
plt.ylabel('文章(篇)')
plt.tight_layout() # 自動控制空白邊緣
plt.savefig('虎嗅網文章數量釋出變化.png',dpi=200)
plt.show()
4.3. 文章收藏量 TOP10
接下來,到了我們比較關心的問題:幾萬篇文章裡,到底哪些文章寫得比較好或者比較火?
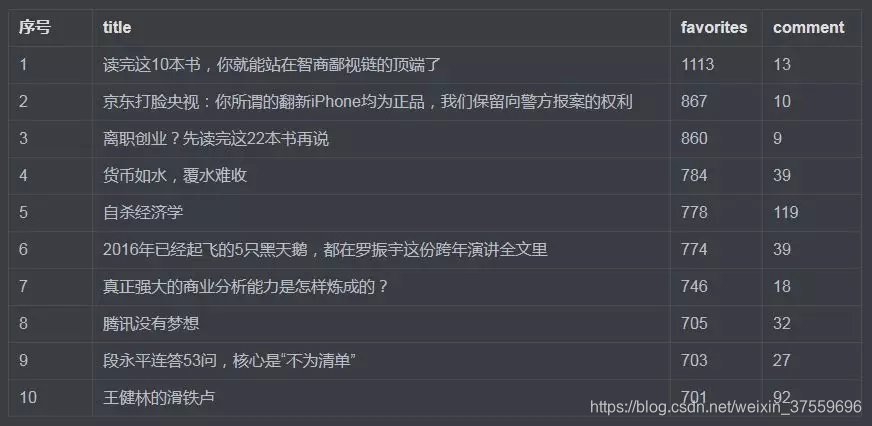
此處選取了「favorites」(收藏數量)作為衡量標準。畢竟,一般好的文章,我們都會有收藏的習慣。
第一名「讀完這10本書,你就能站在智商鄙視鏈的頂端了 」以 1113 次收藏位居第一,並且遙遙領先於後者,看來大家都懷有「想早日攀上人生巔峰,一覽眾人小」的想法啊。開啟這篇文章的連結,文中提到了這幾本書:《思考,快與慢》、《思考的技術》、《麥肯錫入職第一課:讓職場新人一生受用的邏輯思考力》等。一本都沒看過,看來這輩子是很難登上人生巔峰了。
發現兩個有意思的地方:
第一,文章標題都比較短小精煉。
第二,文章收藏量雖然比較高,但評論數都不多,猜測這是因為 大家都喜歡做伸手黨?
4.4. 歷年文章收藏量 TOP3
在瞭解文章的總體排名之後,我們來看看歷年的文章排名是怎樣的。這裡,每年選取了收藏量最多的 3 篇文章。
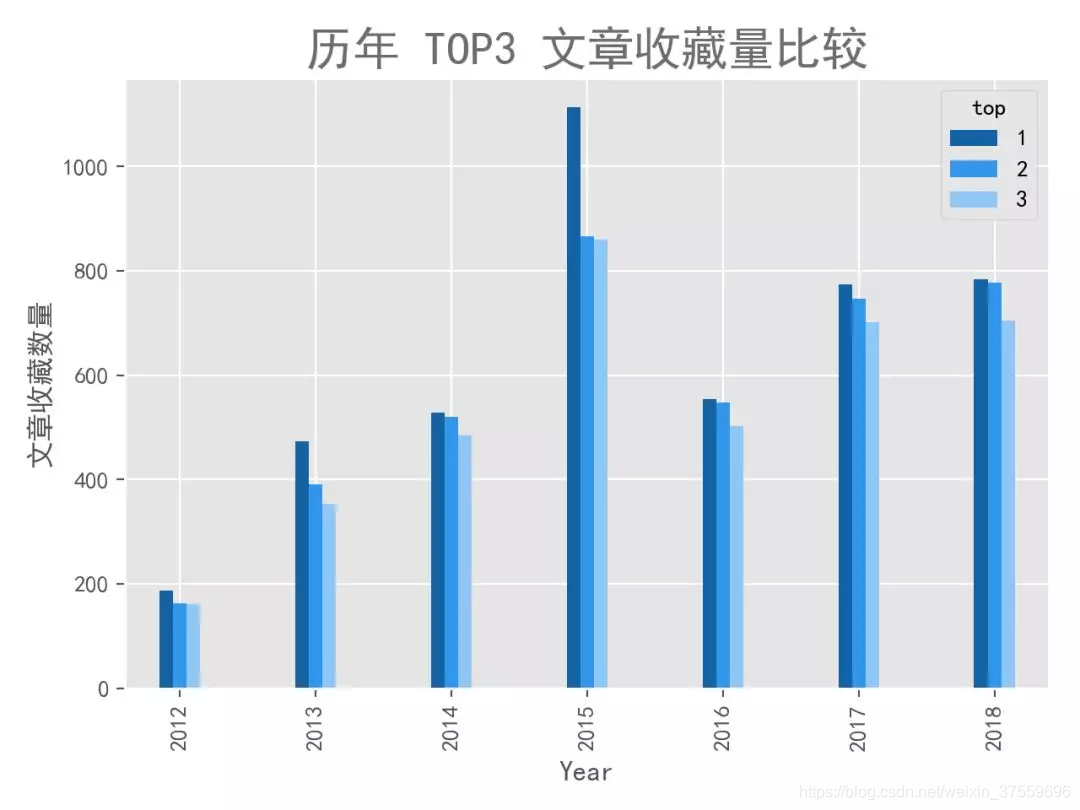
可以看到,文章收藏量基本是逐年遞增的,但 2015 年的 3 篇文章的收藏量卻是最高的,包攬了總排名的前 3 名,不知道這一年的文章有什麼特別之處。
以上只羅列了一小部分文章的標題,可以看到標題起地都蠻有水準的。關於標題的重要性,有這樣通俗的說法:「一篇好文章,標題佔一半」,一個好的標題可以大大增強文章的傳播力和吸引力。文章標題雖只有短短數十字,但要想起好,裡面也是很有很多技巧的。
好在,這裡提供了 5 萬個標題可供參考。如需,可以在公眾號後臺回覆「虎嗅」得到這份 CSV 檔案。
程式碼實現如下:
def analysis2(data):
# # 總收藏排名
# top = data.sort_values(['favorites'],ascending = False)
# # 收藏前10
# top.index = (range(1,len(top.index)+1)) # 重置index,並從1開始編號
# print(top[:10][['title','favorites','comment']])
# 按年份排名
# # 增加一列年份列
# data['year'] = data['write_time'].dt.year
def topn(data):
top = data.sort_values('favorites',ascending=False)
return top[:3]
data = data.groupby(by=['year']).apply(topn)
print(data[['title','favorites']])
# 增加每年top123列,列依次值為1、2、3
data['add'] = 1 # 輔助
data['top'] = data.groupby(by='year')['add'].cumsum()
data_reshape = data.pivot_table(index='year',columns='top',values='favorites').reset_index()
# print(data_reshape) # ok
data_reshape.plot(
# x='year',
y=[1,2,3],
kind='bar',
width=0.3,
color=['#1362A3','#3297EA','#8EC6F5'] # 設定不同的顏色
# title='虎嗅網歷年收藏數最多的3篇文章'
)
plt.xlabel('Year')
plt.ylabel('文章收藏數量')
plt.title('歷年 TOP3 文章收藏量比較',color = colors,fontsize=fontsize_title)
plt.tight_layout() # 自動控制空白邊緣,以全部顯示x軸名稱
# plt.savefig('歷年 Top3 文章收藏量比較.png',dpi=200)
plt.show()
4.4.1. 最高產作者 TOP20
上面,我們從收藏量指標進行了分析,下面,我們關注一下發布文章的作者(個人/媒體)。前面提到發文最多的是虎嗅官方,有一萬多篇文章,這裡我們篩除官媒,看看還有哪些比較高產的作者。
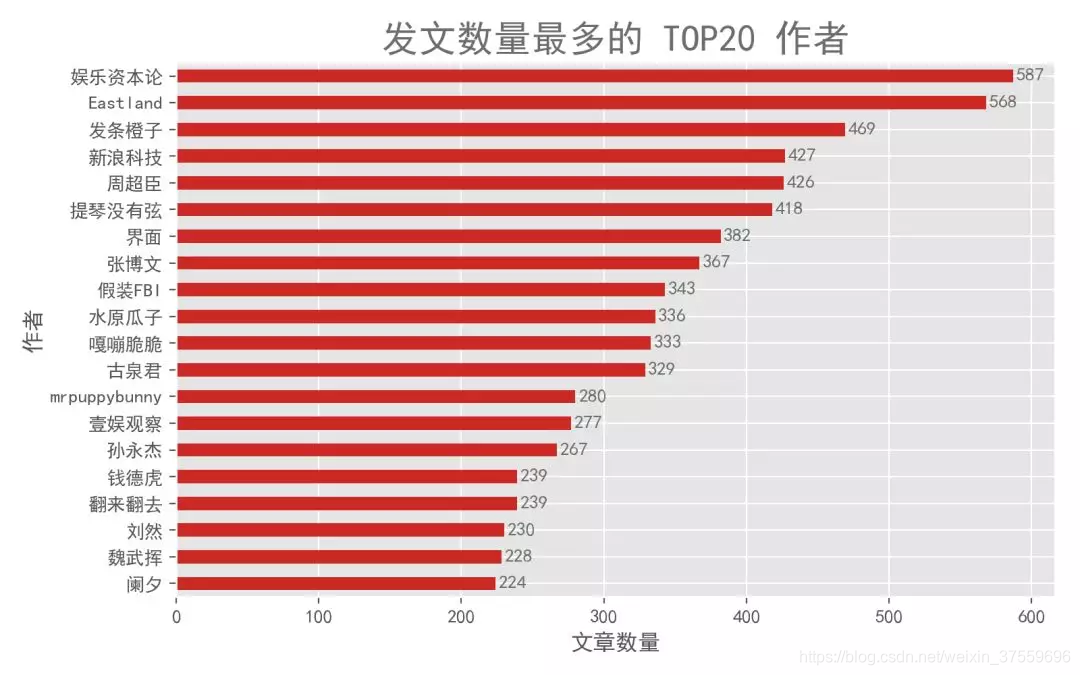
可以看到,前 20 名作者的發文量差距都不太大。發文比較多的有「娛樂資本論」、「Eastland」、「發條橙子」這類媒