
R-FCN 與 Position Sensitive ROI Pooling
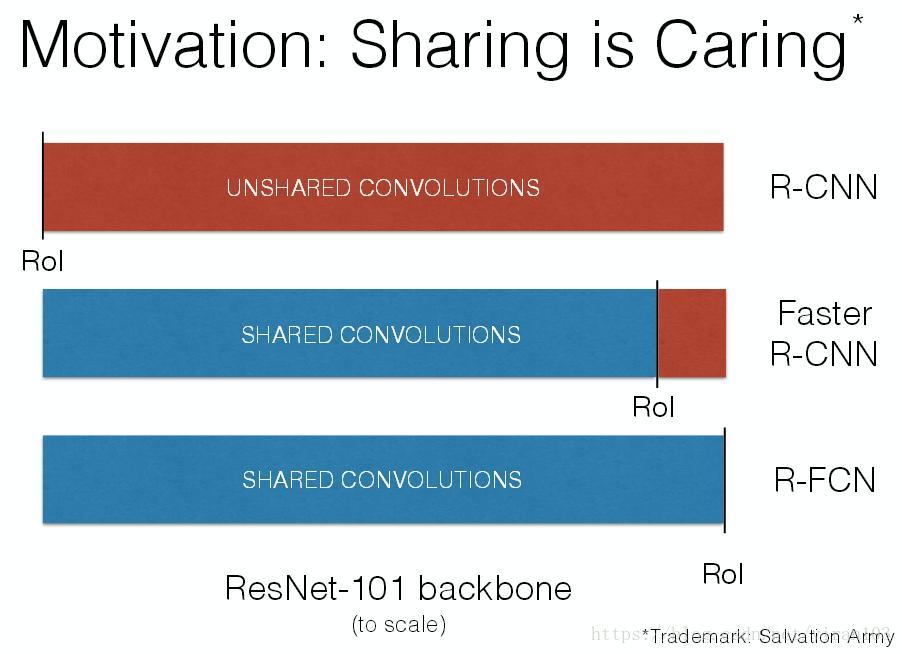
Faster R-CNN 通過與 RPN 共享特徵圖提高了整個檢測過程的速度。然而,其第2階段仍保留 Fast R-CNN 的處理手法,將數百區域逐一送入子網路。R-FCN 在 RoI 間亦共享特徵,減少了區域處理的計算量。在採用 ResNet-101 作為基礎網路時,測試速度為每張影象170毫秒,比 Faster R-CNN 對照模型快2.5-20倍。
R-FCN 的網路結構
為了實現這一目標,R-FCN 提出了位置敏感的得分圖,以解決影象分類中的平移不變性和物體檢測中的平移變化之間的衝突問題。因而,R-FCN 可以自然地採用全卷積影象分類器骨幹,例如最新的殘差網路(ResNets
R-FCN 檢測框架像 FCN 一樣由共享、完全卷積結構組成。為將平移變化引入 FCN 中,其使用一組特殊卷積層作為 FCN 的輸出,構造出位置敏感得分圖。每一個得分圖編碼了相對空間位置資訊(例如,“目標的左側”)。在這個 FCN 之上,附加一個位置敏感的 RoI 彙集層,它從這些得分圖中輸出資訊,其後沒有權重(卷積/fc)層。整個架構是端到端學習的。所有可學習的層都是卷積並且在整個影象上共享,然後編碼目標檢測所需的空間資訊。
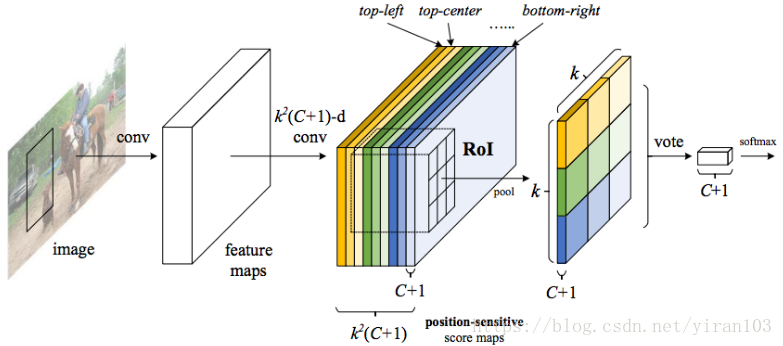
ResNet-101 中的最後一個卷積塊是2048-d,R-FCN 附加一個隨機初始化的1024-d 卷積層以減小維度。然後應用 —通道卷積層來生成得分圖。
假設基礎網路輸出的特徵圖維度為 ,RoI Pooling 的輸出尺寸為 。 則在第2階段,Fast R-CNN 的輸入為 ;而 R-FCN 為 。
基於區域的目標檢測與影象分類網路
目標檢測的常見深度網路系列(Fast R-CNN, SPPNet, Faster R-CNN)可以通過感興趣區域(RoI)池化層分為兩個子網路:
- 獨立於 RoI 的共享、“全卷積”子網路;
- 不共享計算的 RoI-wise 子網路。
這種分解歷史上來源於開創性的分類體系結構,例如 AlexNet 和 VGG 網路,它們由兩個子網路組成—— 一個以空間池化層結束的卷積子網,後面是幾個全連線(fc)層。因此,影象分類網路中的(最後)空間池化層自然地變成目標檢測網路(Fast R-CNN, SPPNet, Faster R-CNN)中的 RoI 池化層。
但近期最先進的影象分類網路,如殘差網路(ResNets)和 GoogLeNets(GoogLeNet, Inception-V3)是全卷積設計(只有最後一層是全連線,在目標檢測微調時將其移除並替換)。通過類比,我們自然而然地使用所有卷積層在目標檢測體系結構中構建共享的卷積子網,這使得 RoI-wise 子網沒有隱藏層。然而,該領域的經驗性研究表明,這種簡單的解決方案所產生的較差的檢測準確度與網路的較高分類準確度不匹配。為了解決這個問題,在 ResNet 論文中,Faster R-CNN 檢測器將 RoI 彙集層以不太自然的方式插入到兩組卷積層之間——這會建立一個更深的 RoI-wise 子網,由於每個 RoI 的計算非共享,以較低的速度為代價提高了準確性。
R-FCN 認為上述不自然的設計是由於影象分類增加平移不變性而物體檢測關注平移變化的兩難選擇造成的:
- 一方面,影象級分類任務促成平移不變性——影象內部物件的移位應該是不加區分的。因此,深度(全)卷積體系結構儘可能是平移不變的,這可以通過ImageNet分類中的主要結果來證明 (ResNet, GoogLeNet, Inception-V3)。
- 另一方面,目標檢測任務需要在一定程度上平移變化的定位表示。例如,候選框內目標的平移應該產生有意義的響應,用於描述候選框與物件重疊的程度。我們假設影象分類網路中較深的卷積層對平移不敏感。
為了解決這個難題,ResNet 論文的檢測方案將 RoI 彙集層插入卷積中——這個特定區域操作打破了平移不變性,在評估不同區域時 RoI 後的卷積層不再是平移不變的。然而,這種設計犧牲了訓練和測試效率,因為它引入了相當多的區域層(如下表所示)。

位置敏感的得分圖與位置敏感的 RoI 池化
為了將位置資訊顯式編碼到每個 RoI 中,R-FCN 通過規則網格將每個 RoI 矩形劃分為 個區間。對於大小為 的 RoI 矩形,區間的大小 (Fast R-CNN, SPPNet)。R-FCN 的最後一個卷積層為每個類別生成 通道的得分圖。在第 個區間(),定義一個位置敏感的 RoI 池化操作,它只彙集第 的得分圖:
這裡 是第 個區間對第 個類別的彙集響應, 是 個得分圖中的一個, 表示 RoI 的左上角, 是區間中的畫素數, 表示網路全部可學習的引數。第 個區間的跨度為 和 。彙集操作如圖2.所示,其中一種顏色代表一對 。公式執行平均池化,但也可以進行最大池化。
然後 個位置敏感的分數在 RoI 上投票。在本文中,我們簡單地通過平均得分進行投票,為每個 RoI 生成 維向量:。然後我們跨類別計算 softmax 響應:。它們用於評估訓練期間的交叉熵損失以及在推理期間對 RoI 進行排序。
R-FCN 以類似的方式進一步解決了邊界框迴歸(R-CNN, Fast R-CNN)。除了上面的 維卷積層,其為邊界框迴歸追加一個並蒂的 維卷積層。位置敏感的 RoI 池化在這一 特徵圖集上執行,為每個 RoI 產生 維向量。然後通過平均投票將其彙總到 維向量中。這個 維向量根據 Fast R-CNN 中的引數化方法將邊界框引數化為 。為簡單起見,實現中執行未知類別的邊界框迴歸,但同樣適用於特定於類的對應物(即,具有 維輸出層)。
位置敏感得分圖的概念部分受到 FCIS 的啟發,它開發了用於例項級語義分割的 FCN。位置敏感的 RoI 池化層用於學習目標檢測的得分圖。在 RoI 層之後沒有可學習的層,幾乎可以無開銷實現區域計算並加速訓練和推理。
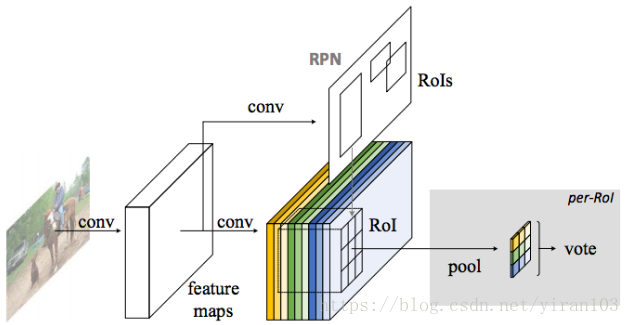
區域提案網路(RPN)提出候選 RoI,然後將其應用於得分圖。所有可學習的權重層都是卷積的,並在整個影象上計算;逐 RoI 的計算成本可以忽略不計。
視覺化
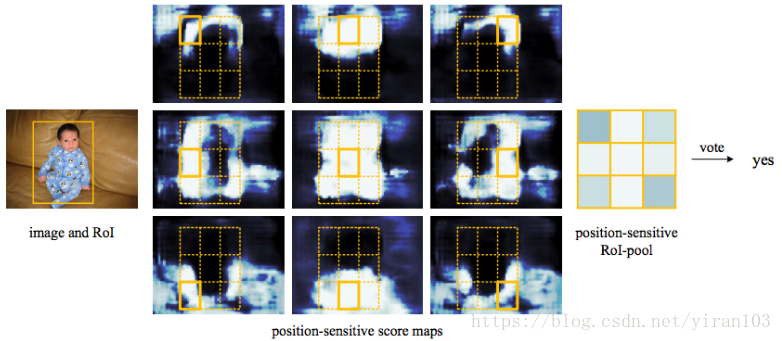
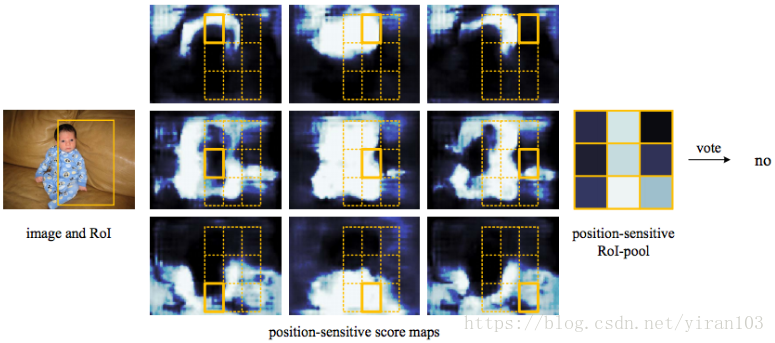
在圖5 和圖6 中,當 時,我們視覺化由 R-FCN 學習的位置敏感得分圖。期望在目標的特定相對位置強烈啟用這些專用對映。 例如,“top-center-sensitive”分數圖顯示大致靠近目標頂部中心位置的高分。
如果候選框與真實目標精確重疊(圖5.),則 RoI 中的大部分 bin 被強烈啟用,並且他們的投票導致高分。相反,如果候選框與真實目標沒有正確重疊(圖6.),則 RoI 中的某些 bin 不會被啟用,並且投票得分較低。
Position Sensitive ROI Pooling 在 Caffe2 中的實現
spatial_scale_指輸入特徵圖 相對於輸入影象的空間比例。例如,如果 的步幅為16,則為0.0625。group_size_為池化輸出 的高度(寬度)。output_dim_為池化輸出的通道數,可能是用於分類的類數,如果用於類不可知邊界框迴歸,則為4。
沒有CPU實現。
template <typename T, class Context>
class PSRoIPoolOp final : public Operator<Context> {
public:
PSRoIPoolOp(const OperatorDef& operator_def, Workspace* ws)
: Operator<Context>(operator_def, ws),
spatial_scale_(OperatorBase::GetSingleArgument<float>(
"spatial_scale", 1.)),
group_size_(OperatorBase::GetSingleArgument<int>("group_size", 1)),
output_dim_(OperatorBase::GetSingleArgument<int>("output_dim", 1)) {
DCHECK_GT(spatial_scale_, 0);
DCHECK_GT(group_size_, 0);
pooled_height_ = group_size_;
pooled_width_ = group_size_;
}
USE_OPERATOR_CONTEXT_FUNCTIONS;
bool RunOnDevice() override {
// No CPU implementation for now
CAFFE_NOT_IMPLEMENTED;
}
protected:
float spatial_scale_;
int group_size_;
int output_dim_;
int pooled_height_;
int pooled_width_;
int channels_;
int height_;
int width_;
};
spatial_scale_和output_dim_兩個引數。
template <typename T, class Context>
class PSRoIPoolGradientOp final : public Operator<Context> {
public:
PSRoIPoolGradientOp(const OperatorDef& def, Workspace* ws)
: Operator<Context>(def, ws),
spatial_scale_(OperatorBase::GetSingleArgument<float>(
"spatial_scale", 1.)),
group_size_(OperatorBase::GetSingleArgument<int>("group_size", 1)),
output_dim_(OperatorBase::GetSingleArgument<int>("output_dim", 1)) {
DCHECK_GT(spatial_scale_, 0);
DCHECK_GT(group_size_, 0);
pooled_height_ = group_size_;
pooled_width_ = group_size_;
}
USE_OPERATOR_CONTEXT_FUNCTIONS;
bool RunOnDevice() override {
// No CPU implementation for now
CAFFE_NOT_IMPLEMENTED;
}
protected:
float spatial_scale_;
int group_size_;
int output_dim_;
int pooled_height_;
int pooled_width_;
int channels_;
int height_;
int width_;
};
輸入:X,RoIs。 輸出:Y,mapping_channel。
auto& X = Input(0); //