
【Tensorflow】資料及模型的儲存和恢復
如果你是一個深度學習的初學者,那麼我相信你應該會跟著教材或者視訊敲上那麼一遍程式碼,搭建最簡單的神經網路去完成針對 MNIST 資料庫的數字識別任務。通常,隨意構建 3 層神經網路就可以很快地完成任務,得到比較高的準確率。這時候,你信心大增,準備挑戰更難的任務。
你準備進行鍼對彩色圖片做型別識別,那麼選 CIFAR-10 就好了。於是,你也基於自己的理解,搭建了一個較為複雜的神經網路,於是,問題可能來了。你自行搭建的神經網路的準確率實在是太低了,有可能 30% 都達不到,沒有辦法,你只能做各種除錯,加深網路,增大卷積核的數量,降低學習率等等,你會發現識別效果會得到改善,但是,訓練時間卻被拉長了,如果你自己學習的電腦沒有 GPU 或者是 GPU 效能不好,那麼訓練的時間會讓你絕望,因此,你渴望神經網路訓練的過程可以儲存和過載,就像下載軟體斷點續傳一般,這樣你就可以在晚上睡覺的時候,讓機器訓練,早上的時候儲存結果,然後下次訓練時又在上一次基礎上進行。
Tensorflow 是當前最流行的機器學習框架,它自然支援這種需求。
Tensorflow 通過 tf.train.Saver 這個模組進行資料的儲存和恢復。它有 2 個核心方法。
save()
restore()
顧名思義,save() 就是用來儲存變數,restore() 就是用來恢復的。
它們的用法非常簡單。下面,我們用示例來說明。
假設我們程式的計算圖是 a * b + c
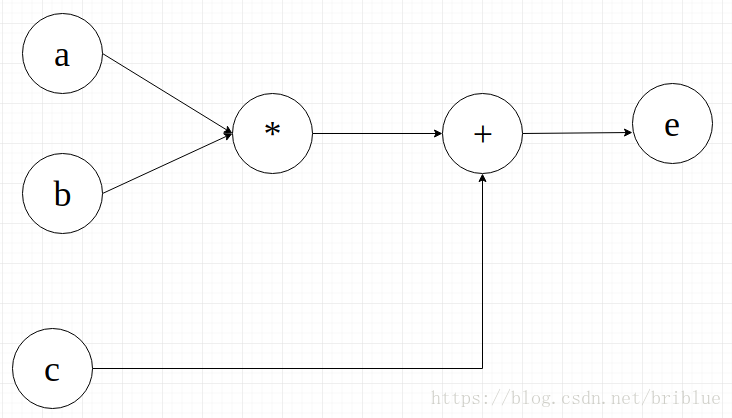
a、b、d、e 都是變數,現在要儲存它們的值,怎麼用 Tensorflow 的程式碼實現呢?
資料的儲存
import tensorflow as tf
a = tf.get_variable("a", 建立標量,然後建立 Saver() 物件就好了。
接下來怎麼儲存這些變數呢?
def test_save(saver):
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver. 先初始化變數,然後呼叫 Saver.save() 方法就好了,第一個引數是 session 物件,第二個引數是變數存放的路徑。
執行程式後,當前目錄下會生成儲存檔案。
並且,程式程式碼有列印變數儲存時本身的值。
a -1.723781
b 0.387082
c -1.321383
e -1.988627
現在編寫程式程式碼讓它恢復這些值。
資料的恢復
同樣很簡單。
def test_restore(saver):
with tf.Session() as sess:
saver.restore(sess, "model/weights")
print("a %f" % a.eval())
print("b %f" % b.eval())
print("c %f" % c.eval())
print("e %f" % e.eval())
test_restore(saver)
呼叫 Saver.restore() 方法就可以了,同樣需要傳遞一個 session 物件,第二個引數是被儲存的模型資料的路徑。
當呼叫 Saver.restore() 時,不需要初始化所需要的變數。
大家可以仔細比較儲存時的程式碼,和恢復時的程式碼。
執行程式後,會在控制檯列印恢復過來的變數。
a -1.723781
b 0.387082
c -1.321383
e -1.988627
這和之前的值,一模一樣,這說明程式程式碼有正確儲存和恢復變數。
上面是最簡單的變數儲存例子,在實際工作當中,模型當中的變數會更多,但基本上的流程不會脫離這個最簡化的流程。