
2018秋招面試問題(十一、資料結構基礎問題)
注:面試過程中整理的學習資料,如有侵權聯絡我即刻刪除。
目錄
資料結構中連結串列和陣列的異同?
陣列的元素在記憶體中是連續存放的,我們可以通過下標快速訪問到某個元素,而如果要對陣列進行增加或者刪除元素,就要移動大量的元素,插入刪除的效率低。並且陣列的大小是固定的,不能動態擴充套件。可能浪費記憶體。
連結串列的元素在記憶體中是不連續的,由結點組成,每個結點都包含一個指標域(儲存下一個結點的指標)一個數據域。訪問連結串列元素需要從第一個結點開始,遍歷找到該結點元素,查詢效率低,但是增加和刪除元素就很方便,只需要修改結點指標的指向,連結串列記憶體利用率很高,大小不固定,擴充套件很靈活。
<在a、c節點中插入b結點:a->next = b; b->next = c;如果沒給出c,那就是b->next = a->next; a->next = b;
刪除a的下一個結點:a->next = a->next->next;
delete item;>
所以如果是要快速訪問元素,那就使用陣列,如果是需要經常刪除增加元素,那就使用連結串列。
佇列的資料結構,以及迴圈(環形)佇列如何實現

入佇列的時候是隊頭保持不變,隊尾++;
出佇列的時候是隊尾保持不變,隊頭++;
迴圈(環形)佇列只要在插入資料的時候對佇列容量取餘就好了,代表隊尾的下一個指向了隊頭。
佇列和棧的使用場景
棧是先進後出,佇列是先進先出。
<從左到右列印二叉樹的結點是用佇列。>
佇列:計算機各種資源的管理、訊息緩衝器的管理。
棧:匹配表示式的括號(遇到左括號就壓棧,遇到右括號就出棧)
以及函式的遞迴實現。
資料結構中陣列、連結串列、堆疊有些什麼區別?
陣列是一塊連續的記憶體空間,資料個數是在分配記憶體時就確定了的。陣列的訪問的時間複雜度是O(1),查詢的時間複雜度是O(N),刪除和插入的時間複雜度也是O(N)。
連結串列是非連續的記憶體單元,通過指標將各個單元連在一起,連結串列不需要提前分配固定大小的儲存空間,當需要分配記憶體的時候分配一塊記憶體並把這塊記憶體插入連結串列中。連結串列的查詢和訪問資料的時間複雜度都是O(N),插入和刪除資料的時間複雜度都是O(1)。
堆是樹形資料結構,每個節點都有一個值,可以說就是一棵樹。有二叉樹和K叉樹堆。堆分為大頂堆和小頂堆<大頂堆的子樹也都是大頂堆>。根節點的兩個子樹也是堆。我們平時常用的堆都是二叉堆,是一個完全二叉樹。應用場景包括堆排序、優先佇列。
棧是先進後出的結構,對棧的資料操作都只能在頂部,只可以檢視、插入、刪除棧頂部的資料。(push\pop\top)
佇列是先入先出的結構,佇列只允許在隊頭刪除資料,在隊尾增加資料,但是都可以檢視隊頭隊尾的資料。
如何實現雜湊表?向後定址好嗎?
<雜湊表和陣列的查詢都是O(1),雜湊和陣列一樣都很耗空間>
雜湊表解決衝突有幾種方法:開放定址法、鏈地址法、再雜湊法。平時主要用開放定址法。
開放定址法的優缺點:
缺點:a儲存記錄的數目不能超過桶陣列的長度,如果超過了就需要擴容,而擴容會導致時間成本飆升。b使用探測序列,有可能計算key的時間成本很高。c刪除記錄時,比較麻煩,比如需要刪除記錄A,記錄B是在A之後插入桶陣列的,但是和記錄A有衝突,是通過探測序列再次跳轉找到的地址,所以如果直接刪除A,A的位置變為空槽,而空槽是查詢記錄失敗的終止條件,這樣會導致記錄B在A的位置重新插入資料前不可見,所以不能直接刪除A,而是設定刪除標記。這就需要額外的空間和操作。
優點:a記錄更容易進行序列化操作。b如果預知記錄總數,可以建立完美雜湊函式,此時的效率很高。
鏈地址法:
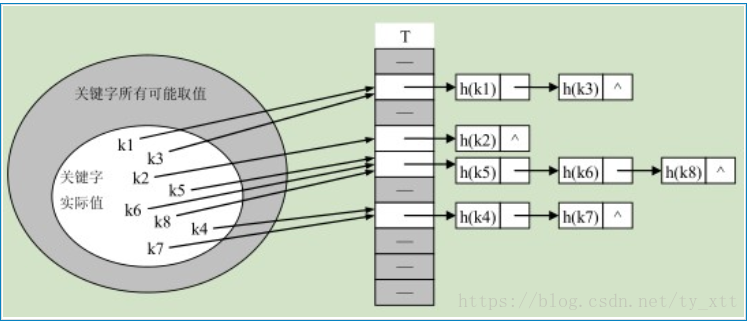
Hashtable
Hashtable是基於雜湊表實現的,每個元素是一個key-value對,其內部也是通過單鏈表解決衝突問題,容量不足(超過了閥值)時,會自動增長。Hashtable不允許key和value是NULL的。
Hashtable的put和get方法。
put方法:計算key的hash值,根據hash值獲得key在table陣列中的索引位置,然後迭代該key處的Entry連結串列(我們暫且理解為連結串列),若該連結串列中存在一個這個的key物件,那麼就直接替換其value值即可,否則在將該key-value節點插入該index索引位置處。插入元素時會首先進行容量校驗,如果容量已經達到了閾值,hashtable會進行擴容處理rehash()。得到key的hash值主要是通過hashcode函式值與hashseed位與得到的。hashSeed,這是一個例項有關的隨機值,主要用來解決雜湊衝突。
get方法:處理過程就是計算key的hash值,判斷在table陣列中的索引位置,然後迭代連結串列,匹配直到找到相對應key的value,若沒有找到返回null。
hashtabe和hashmap的不同
hashtable和hashmap都是STL容器。都是基於雜湊表結構的,都是用鏈地址法來處理的衝突。
- hashtable不允許key和value為null,而hashmap可以。
- 遍歷的話兩個都可以用迭代器,只是hashtable還可以使用Enumeration方法。
- 在計算hash值時,hashtable用的key的hashcode()來得到,hashmap則是重新計算hash值。
hashtable是執行緒安全的,hashmap是執行緒不安全的。
為什麼hashmap是執行緒不安全的?為什麼hashtabe是執行緒安全的?
hashmap不安全:主要是addEntry()函式,多個執行緒都可以得到當前雜湊表位置的頭結點,並修改頭結點。這樣別的執行緒就會覆蓋之前執行緒的操作。
hashtable安全:是加了鎖的,synchronized。
STL之認識hash_set和hash_map
hash_set是限制了功能的hash_map,底層是由hash_map來實現的。對於重複的資料不會再插入。
雜湊表的資料檢索
雜湊表是根據Key---value來直接進行訪問的資料結構,以加快查詢的速度。是一種定址容易,插入和刪除也容易的資料結構。
雜湊表的資料檢索,是通過雜湊函式。計算出資料所存放的雜湊地址。即算出資料在哪個桶的單鏈中,然後對單鏈中的每一個數據進行比較,檢索出所要的資料。為了使每一個桶中的元素儘可能地少,使用大質數作為表長,並且使用表長作為求餘運算的模。
雜湊表有多種實現方法,以下是拉鍊法:
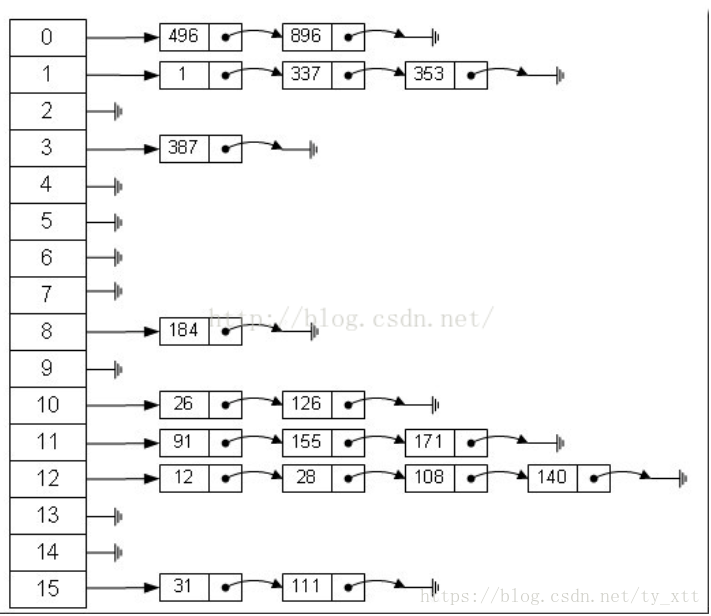
左邊是個陣列,陣列中都是指標,指向一個連結串列的頭,我們根據元素的一些特徵把元素分配到不同的連結串列中去,也是根據這些特徵,找到正確的連結串列,再從連結串列中找出這個元素。
雜湊表是如何存字串的?
首先將字串通過雜湊演算法hash(key)算出對應的雜湊值,再取一個大質數取餘%,來得到這個字串所在的key值對應。
雜湊演算法有非常多,如果是單字元,就可以直接用字元所代表的ASIC碼來作為key,字串abcde可以用97*1+98*E^1+99*E^2+100*E^3+101*E^4來表示這個字串的key。
什麼時候用雜湊map,什麼時候用map?
兩個都是map容器,不同的是key的結構不同。
map的key是紅黑樹結構(二叉平衡排序樹),雜湊map的key是雜湊表的結構。Hash_map檢索出來的元素是無序的,map用迭代器遍歷出來的元素是有序的。樹結構的查詢是O(nlog2n),雜湊表結構的查詢很快,是O(1)。但是樹結構比較有利於插入和刪除,所以刪除和插入比較多的時候,用map比較好;資料量很大,查詢頻繁的時候用雜湊map比較好。
XML中的節點是什麼資料結構
是連結串列和樹,next和pre指標組成連結串列,children和parent指標組成樹。
XML文件的操作其根本原理就是在節點之間移動、查詢節點的各項資訊,並進行增加、刪除、修改等操作。