
solr與ik中文分詞的配置,以及新增Core(Add Core)的方式
在下用的版本是solr7.2.1與ikanalyzer-solr6.5:
說明:在solr版本5之後就可以不用依賴tomcat進行啟動,可以自行啟動,啟動方式下面會進行講解。
需要注意的是:對於solr6以下的版本可用jdk7,從solr6開始只能使用jdk8了。
solr下載完成之後,找到bin目錄,如圖:
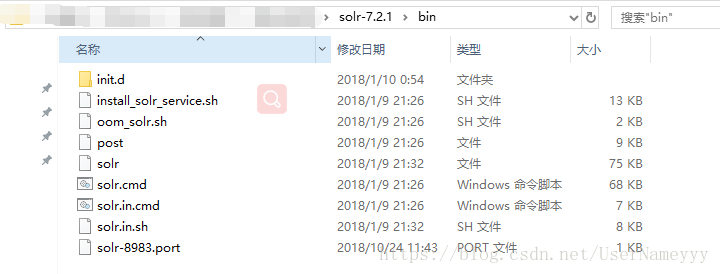
在此目錄下,Shift+右鍵開啟cmd命令視窗或者powershell視窗(windows10系統下有的),cmd命令視窗輸入solr start即可執行,輸入solr stop -all即可停止,注意:powershell視窗須在前加“./”,如啟動./solr start,停止./solr stop -all,本人是用powershell開啟的,如圖:

啟動成功之後,訪問localshot:8983即可
新增Core時,需注意以下步驟:
在solr目錄下新建資料夾,名為Blogs_Core(自取),我這裡取名為(Blogs_Core)
找到solr/configsets/_default目錄,如圖:

在此目錄下將conf資料夾複製到Blogs_Core資料夾下。如圖:

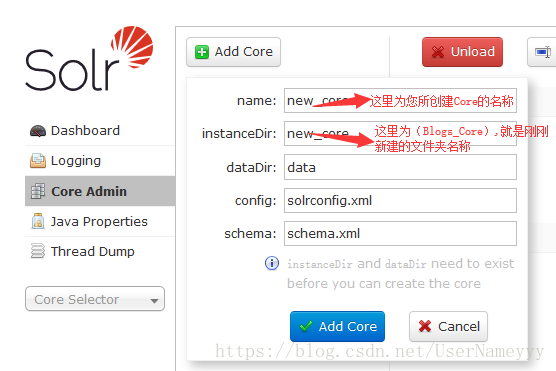
此時可以新增Core了,如圖,注意:
1、name時Core的名稱可以任取,建議使用與instanceDir一樣的名稱
2、instanceDir的名稱就為Blogs_Core,就是剛剛在solr目錄下建立的資料夾的名稱
3、其他的可以保持不變
ik分詞器下載好之後,如圖:

將兩個jar檔案拷貝到solr-7.2.1\server\solr-webapp\webapp\WEB-INF\lib目錄下,如圖
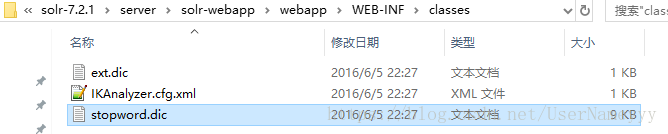
在目錄WEB-INF下新建名稱為classes的資料夾,將其他三個檔案ext.dic,IKAnalyzer.cfg.xml,stopword.dic拷貝到此目錄下,完成之後如圖:
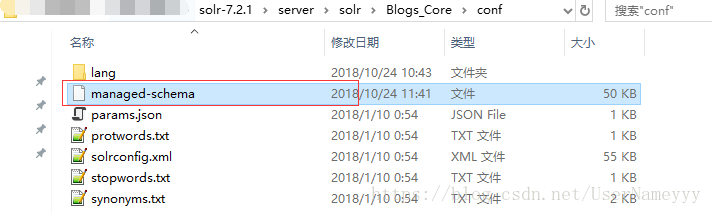
下一步:在solr-7.2.1\server\solr\Blogs_Core\conf目錄下,記事本開啟managed-schema檔案,如圖:
新增其以下節點:
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false"/> </analyzer>
</fieldType>
以上也是屬於自己在配置過程中的拙見,如有錯誤,還望指正。
互相學習,每天進步