
solr6.6配置IK中文分詞、IK擴充套件詞、同義詞、pinyin4j拼音分詞
<fieldType name="text_pinyin" class="solr.TextField" positionIncrementGap="0"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" /> <filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" /> <filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" /> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory"/> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" /> <filter class="solr.LowerCaseFilterFactory" /> </analyzer> </fieldType> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" useSmart="false" > <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory"/> <filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> </analyzer> <analyzer type="query" useSmart="true" > <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory"/> <filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> </analyzer> </fieldType>
6、重啟solr,訪問http://localhost:8983/solr/#/【corehotel】/analysis Analyse Fieldname / FieldType選擇text_ik, 6.1、中文分詞:

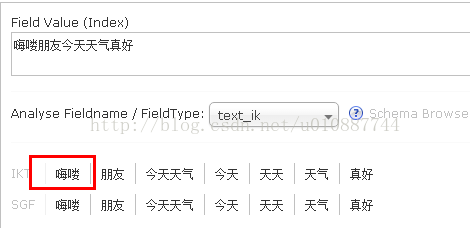
6.2、IK擴充套件詞 “嗨咯”這個詞語我不想拆分怎麼辦呢,只需在server\solr-webapp\webapp\WEB-INF\classes目錄配置擴充套件詞即可。配置檔案包含:IKAnalyzer.cfg.xml、以及ext.dic,相關檔案可直接在附件下載。 在ext.dic內容中新增一行資料“嗨咯”,然後重啟solr,再次查詢“嗨嘍朋友今天天氣真好”,就會發現“嗨嘍”並未被分詞了。
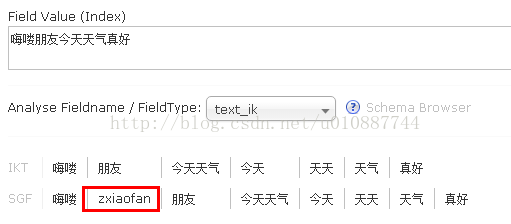
6.3、同義詞 如果我想查詢“朋友”的時候也能搜尋到“zxiaofan”怎麼操作呢,只需在server\solr\【coreName】\conf\synonyms.txt檔案中新增一行資料(朋友,zxiaofan)即可。重啟solr,再次查詢“嗨嘍朋友今天天氣真好”,你就會發現分詞器結果中包含了“zxiaofan”這個詞語了。
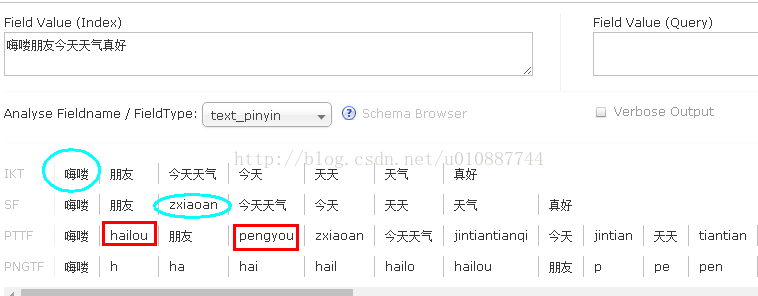
6.4、pinyin4j拼音分詞 Analyse Fieldname / FieldType選擇text_pinyin,你會發現分詞結果中包含了拼音,並且前面配置的擴充套件詞、同義詞依然有效(因為text_pinyin依舊使用了IK分詞器)。
歡迎個人轉載,但須在文章頁面明顯位置給出原文連線;
未經作者同意必須保留此段宣告、不得隨意修改原文、不得用於商業用途,否則保留追究法律責任的權利。
【 CSDN 】:csdn.zxiaofan.com
【GitHub】:github.zxiaofan.com
如有任何問題,歡迎留言。祝君好運!
Life is all about choices!
將來的你一定會感激現在拼命的自己!相關推薦
solr6.6配置IK中文分詞、IK擴充套件詞、同義詞、pinyin4j拼音分詞
solr基本指令: jetty部署【推薦】:Linux: $ bin/solr start;Windows: bin\solr.cmd start 建立core: Linux: $ bin/solr create -c corehotel;Windows: bin\so
iOS 分類(category)、類擴充套件(extension)、協議(protocol)
分類 category 使用場景分析 1.擴充套件已有的類 有大量的子類,需要新增公用方法,但又無法修改它們的父類的情形(如系統類)。 一般是大量的功能程式碼已經形成,使用子類需要新增新類的標頭檔案等。分類只能新增方法,不能新增屬性。(下文會提到如何新增屬性)2.使用父類私有方法 已經存在了
solr 6.2.0系列教程(二)IK中文分詞器配置及新增擴充套件詞、停止詞、同義詞
前言 2、solr的不同版本,對應不同版本的IK分詞器。由於IK 2012年停止更新了。所以以前的版本不適合新版的solr。 有幸在網上扒到了IK原始碼自己稍微做了調整,用來相容solr6.2.0版本。IK原始碼下載地址 步驟 1、解壓下載的src.rar壓縮包,這是我建
Solr6.6.0添加IK中文分詞器
其中 開發 其余 下載鏈接 classes 項目 實現 .com 擴展 IK分詞器就是一款中國人開發的,擴展性很好的中文分詞器,它支持擴展詞庫,可以自己定制分詞項,這對中文分詞無疑是友好的。 jar包下載鏈接:http://pan.baidu.com/s/1o85I15o
Solr6.2搭建和配置ik中文分詞器
首先需要的準備好ik分詞器,因為Solr6.0版本比較高,所以ik分詞器的版本最好高一點,我是用ikanalyzer-solr5來搭建的. 第一步 解壓ikanalyzer-solr5. 第二步 複製ik-analyzer-solr5-5.x.jar並將其放在solr-6.2.1\se
Linux下ElasticSearch6.4.x、ElasticSearch-Head、Kibana以及中文分詞器IK的安裝配置
ElasticSearch 安裝配置 下載 # 官網下載壓縮包 [[email protected] /home]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.
(四)Solr6.4.1配置中文分詞器IK Analyzer詳解
Solr6.4.1配置中文分詞器IK Analyzer詳解 2.把IKAnalyzer.cfg.xml,mydict.dic,stopword.dic這三個檔案複製放入tomcat/solr專案web-info的classes下 3.把ik-analyz
es5.4安裝head、ik中文分詞插件
es安裝maven打包工具wget http://mirror.bit.edu.cn/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz tar -xf apache-maven-3.3.9-bin.tar.gz mv apach
solrcloud配置中文分詞器ik
lte config server field per str load fonts textfield 無論是solr還是luncene,都對中文分詞不太好,所以我們一般索引中文的話需要使用ik中文分詞器。 三臺機器(192.168.1.236,192.168.1.237
Solr 配置中文分詞器 IK
host dex text class get mar con png 網址 1. 下載或者編譯 IK 分詞器的 jar 包文件,然後放入 ...\apache-tomcat-8.5.16\webapps\solr\WEB-INF\lib\ 這個 lib 文件目錄下;
ElasticSearch搜索引擎安裝配置中文分詞器IK插件
art linux系統 nal smart 分享 內容 分詞 search dcl 一、IK簡介 ElasticSearch(以下簡稱ES)默認的分詞器是標準分詞器Standard,如果直接使用在處理中文內容的搜索時,中文詞語被分成了一個一個的漢字,因此引入中文分詞器IK就
solr與ik中文分詞的配置,以及新增Core(Add Core)的方式
在下用的版本是solr7.2.1與ikanalyzer-solr6.5: 說明:在solr版本5之後就可以不用依賴tomcat進行啟動,可以自行啟動,啟動方式下面會進行講解。 需要注意的是:對於solr6以下的版本可用jdk7,從solr6開始只能使用jdk8了。 so
Solr6.5配置中文分詞IKAnalyzer和拼音分詞pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安裝與配置 (一) 一文中介紹了solr6.5的安裝。這篇文章主要介紹建立Solr的Core並配置中文IKAnalyzer分詞和拼音檢索。 一、建立Core: 1、首先在solrhome(solrhome的路徑和配置見Solr6.5在Centos6上的安裝與配置
solr5.5版本中ik中文分詞配置
這裡我使用的是solr5.5進行匹配的 分詞器 首先需要先下載IKAnalyzer 分詞器 下載地址: IK分詞器jar 將下載好的jar 放到 webapps\solr\WEB-INF\lib
ElasticSearch 6.5.4 安裝中文分詞器 IK和pinyiin
ES的常用的中文分詞有基於漢字的ik和基於拼音的pinyin https://github.com/medcl/elasticsearch-analysis-ik/releases https://github.com/medcl/elasticsearch-analysis-pinyi
Solr配置中文分詞器IK Analyzer詳解
歡迎掃碼加入Java高知群交流 配置的過程中出現了一些小問題,一下將詳細講下IK Analyzer的配置過程,配置非常的簡單,但是首先主要你的Solr版本是哪個,如果是3.x版本的用IKAnalyzer2012_u6.zip如果是4.x版本的用IK Analyzer 20
【Elasticsearch】Elasticsearch 6.x 探索之路-中文分詞器IK
1.分詞機制 Elasticsearch對於查詢,是採取按分詞的結果進行查詢的,作為一款非國產的軟體,自然對於中文的查詢支援並不是很好,預設只會把中文拆分成單字,而通常使用都是以“詞”作為基準單位的。 我們可以使用外掛(plugins)機制去拓展Elasticsearch
Solr 5.0.0配置中文分詞器IK Analyzer
Solr版本和IK分詞版本一定對應 (ps我版本沒對應好弄了快倆小時了) 只適合Solr 5.0.0版本 1.下載IK分詞器包 連結: https://pan.baidu.com/s/1hrXovly 密碼: 7yhs 2.解壓並把IKAnalyzer-5.0.jar 、solr-analyzer-extra
Solr 7.2.1 配置中文分詞器 IK Analyzer
一、什麼是中文分詞器? 為什麼不來個英文分詞器呢? “嘿,小夥子,就是你,說的就是你,你那麼有才咋不上天呢!” 首先我們來拽一句英文:“He is my favorite NBA star”
solr6.4+拼音分詞與ik中文分詞
整理一下前端時間用的solr結合拼音分詞與ik中文分詞。solr比lucene封裝較好,可以直接在配置檔案中配置這些分詞就可以直接用。 主要工具包: pinyinAnalyzer.jar ik-analyzer-solr6.x.jar pinyin4j-2.5.0