
【風控建模】風控模型崗基本要求及面試問題總結
阿新 • • 發佈:2018-12-17
一 準備工作
根據核心職業CD法則,找這份工作前,你先得知道自己有什麼,自己要什麼;面試單位有什麼,面試單位要什麼。
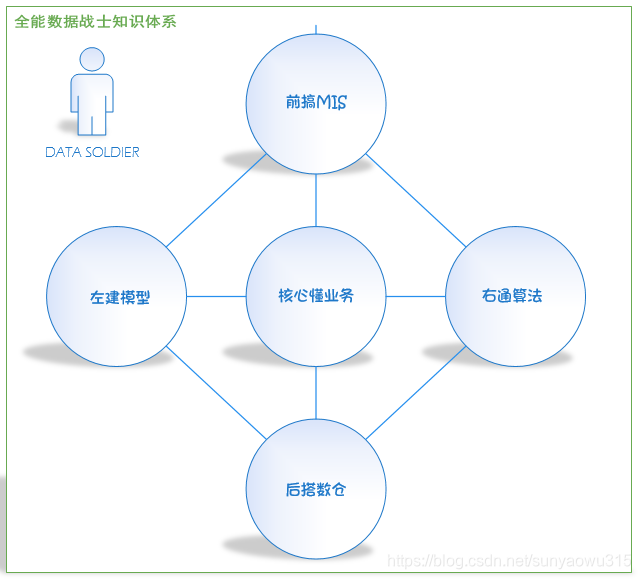
就筆者這將近一年的學習及工作經驗總結而言,頂頭到建模這塊兒,整個知識版塊可以分為五大塊兒,總結如下:
- 前搞MIS:業務資料報告及報表的開發。
- 後搭數倉:資料倉庫知識,包括資料庫、資料表的開發維護,etl的流程,sql語言的編寫。
- 左建模型:預測模型,這裡特指信用評分卡模型。
- 右通演算法:logistic、SVM、randomforest、ann、dnn等核心演算法。
- 核心懂業務:網際網路金融、信用迴圈等。
畫個VISIO:
每一塊兒知識點都掌握,並且能夠熟練運用,就已經可以稱為一個合格的全能資料戰士了。
那我們的面試準備工作,就可以從以上幾點出發,重點從模型著手。
1 工作經驗
- 網際網路金融風控崗位的業務理解,比如:信用迴圈體系;核撥率、遞延率、壞賬率等運營指標;滾動率、賬齡分析等分析指標。
- 風控模型的開發流程,比如:信用模型評分卡的開發、上線、優化等過程及方法。
2 基礎知識
(以下詳細內容請看筆者其他相關文章)
- 資料存取與處理:基礎能力,這是資料分析類工作的技能基礎,也是任何一個數據類工種都需要的基礎能力,不熟練的話就再學一段時間。
- 統計學習:機器學習的基礎是概率論與統計學習,這塊兒你可以不必特別紮實,但像五位數、方差、正態分佈、相關係數、假設檢驗常用知識點得了解並掌握。
- 機器學習:用於特徵工程及建模工作,同樣不必全懂,但一到兩種常用演算法的推導及一到兩種融合演算法的原理必須掌握,常用的元模型為邏輯迴歸、決策樹;常用的融合模型有隨機森林;神經網路則有ANN。
- 特徵工程:不論是規則還是評分卡,風控建模類工作的大量工作內容就是對使用者特徵的挖掘、定義、擴充套件、轉換、處理、分析、運用,以產生對業務有幫助的決策資料。所以特徵工程來龍去脈需要懂,並且會熟練使用。
3 程式碼能力
- python or R or sas,把一門程式碼類工具運用熟練即可。就python而言,像pymysql、pandas、numpy、xlwt、statsmodels、sklearn,也就這幾個包學紮實就行。
二 模型開發
1 模型開發
- 談談你對模型的理解?
- 模型如何設計?
可以從滾動率、遷徙率來回答。 - 對客群進行細分建模的本質是什麼?
其實分客群進行建模,實質也是一種交叉特徵,能提高模型穩定性。 - 拒絕推斷應該怎麼做,作用是什麼?效果怎麼樣?
2 模型評估
- 模型評估的常用方法?
- 從三方面回答:
- 區分度:主要有KS和GINI指標,理解KS的定義及用法
- 準確性:主要有roc曲線和AUC指標,理解AUC的定義及用法
- 穩定性:主要有PSI指標,理解PSI的定義及用法
- auc和ks的關係?
有人說auc是衡量整個模型的排序能力,KS是衡量某個分段的區分能力。直接上程式碼吧,看完就都明白了:
def yq_KS(y_label,y_pred,quantile=0):
fpr,tpr,threshold=metrics.roc_curve(y_label,y_pred[:,1])
if quantile>2:
quantilelist=100*np.arange(quantile+1)/float(quantile)
fpr=np.percentile(fpr,quantilelist)
tpr=np.percentile(tpr,quantilelist)
KS=max(tpr-fpr)
return KS
3 模型部署
- 模型的部署上線應用類似的問題,主要就是app介面測試、等級劃分、額度設計、風險定價、ABtest的設計等等。
4 模型監測
- 一些運營資料和風控指標的關注
三 特徵工程
- 如何對資料做質量檢驗?
在完成資料匹配工作之後,建模之前,我們需要對資料進行整體的質量檢測,主要有兩個方面:
- 資料分佈。
- 資料集中度檢測。
- 資料髒亂情況。缺失值(是否隱藏風險)、離群值、錯誤值、重複值,根據其是否符合業務邏輯,判斷資料是否存在異常。
-
特徵工程流程
關鍵詞:特徵預處理、特徵選擇、特徵衍生、特徵提取等。用到的技術主要有連續變數離散化、分類變數啞編碼、卡方分箱、特徵編碼、共線性檢驗、PCA降維、交叉驗證等。 -
篩選變數的常用方法
篩選變數有很多種方法,隨機森林、GBDT、邏輯迴歸顯著性、VIF共線性、相關性圖譜等、隨機邏輯迴歸篩選、遞迴法篩選等。 -
好的特徵需要具備哪些優勢:
- 穩定性高
- 區分度高
- 差異性大
- 符合業務邏輯
- 如何衍生特徵?
變數的衍生並不複雜,通常我們會從三種角度出發:
- 數學運算。求和、比例、頻率、平均等。
- 時間視窗。有些變數的意義只有在一段時間內才有效,所以針對時間比如說註冊如期、交易日期等變數,需要計算其到現在的時間段,完成變數的衍生。
- 交叉組合。GBDT\XGBoost、LDA主題模型、使用者畫像分等等都可以做特徵衍生。
衍生出來的特徵要符合實際業務含義,並且要保持穩定。
GBDT/XGBooting 及神經網路中間層做衍生。
四 機器演算法
簡單介紹你熟悉的幾種演算法及其在應用場景中的差別!
一些基本公式的推導,比如LR、xgb之類的,這些可以自己推導一下。
簡單評價幾種常用演算法的優缺點:
- 邏輯迴歸:
優點:簡單、穩定、可解釋、技術成熟、易於監測和部署
缺點:一定不能有缺失資料;必須是數值型特徵,需要編碼;準確度不高 - 決策樹:
優點:對資料質量要求不高,易解釋
缺點:準確度不高 - 其他元模型 :
- 組合模型:
優點:準確度高,穩定性強,泛化能力強,不易過擬合
缺點:不易解釋,部署困難,計算量大
番外篇:
筆者面試經歷:
和信貸:分析師
宜信:分析師
信徵科技:模型師
北京有跡:模型師