
innodb儲存引擎筆記(上)
MySQL發展路線圖:
MySQL體系結構
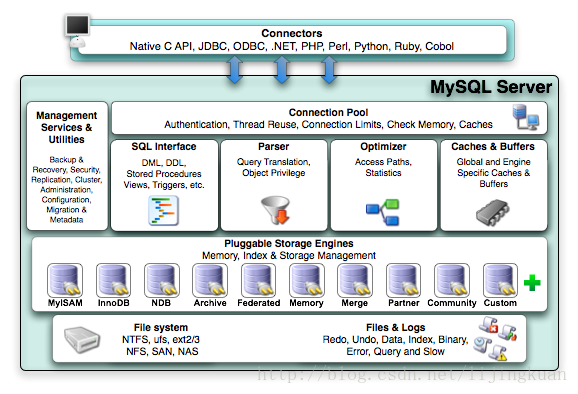
InnoDB體系架構圖
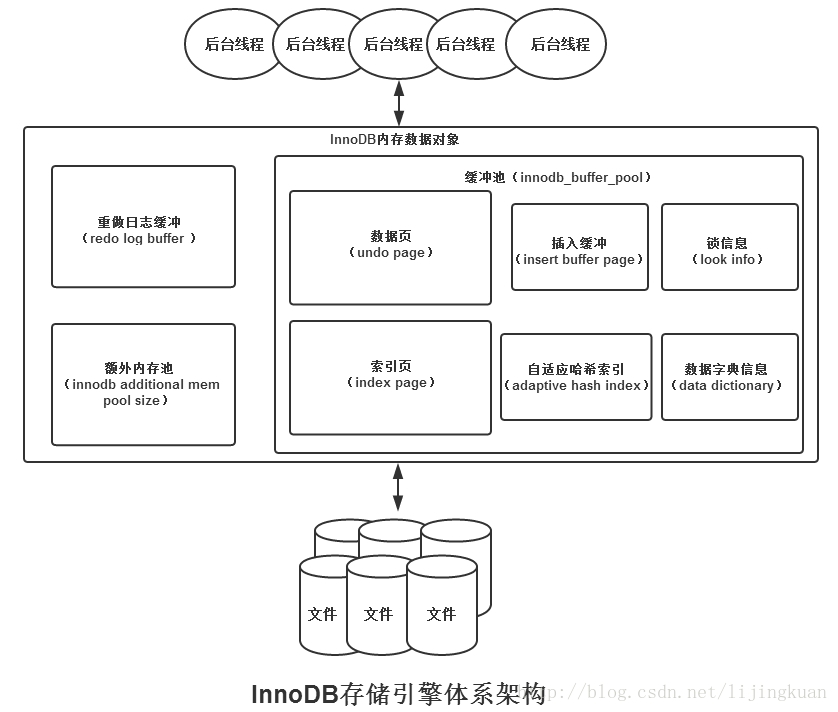
總體架構圖:
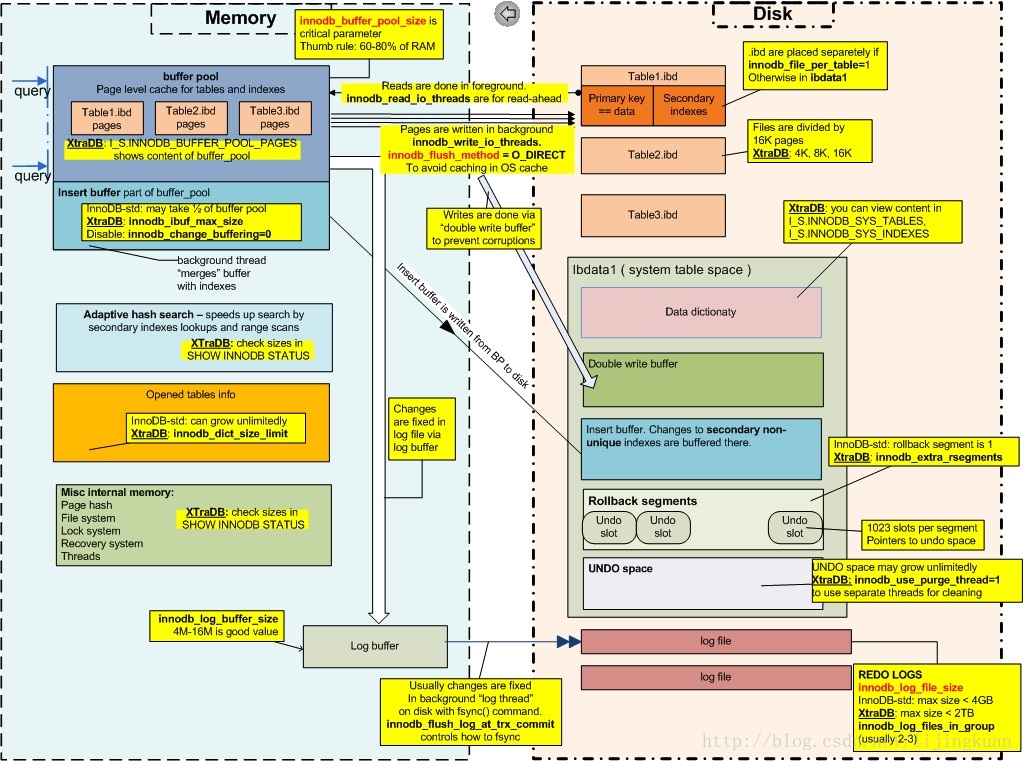
儲存結構:
表空間
所有的資料都需要儲存在表空間中
表空間分類
系統表空間(ibdata1)
獨立表空間(innodb_file_per_table)
undo tablespace,MySQL5.6+
temporary tablespace,MySQL5.7+
general tablespace,MySQL5.7+(類似於oracle的)
問:資料庫建立後,還能建立undo 表空間不?
答:目前不能,undo表空間是在資料庫初始化的時候建立的。
問:undo有預設的過期時間嗎?
答:undo沒有預設的過期時間。等這個事務提交完以後,沒有更多的事務需要這份undo log的時候,它就可以被清除。也就是MVCC裡面沒有事務再需要這份舊的undo log的時候,就可以purge掉;
系統表空間
總是必須的
檔名ibdata1
innodb_data_file_path定義路徑、初始化大小、自動擴充套件策略
主要儲存物件
data dictionary
double write buffer
insert buffer/change buffer
rollback segments
undo space(新版本可以獨立出去)
foreign key constraint system tables
user data,if innodb_file_per_table=0
建議大小:
innodb_data_file_path = ibdata1:1G:autoextend
除去佔用空間最大的undo space之後,剩下的就很小了,不需要太大空間。
獨立表空間
設定innodb_file_per_tables = 1
每個table都有各自的xx.ibd檔案
rollback segments,double write buffer等仍然存放在共享表空間檔案裡
主要儲存聚集索引B+樹以及其他普通索引資料
日誌檔案
undo log
redo log
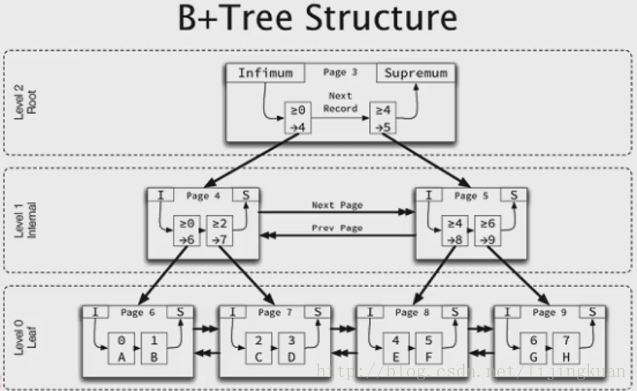
Innodb是聚集索引組織表
基於B+樹
資料以聚集索引邏輯順序儲存
聚集索引有限選擇顯示定義的主鍵
其次選擇第一個非null的唯一索引
再次使用隱藏的rowid
聚集索引葉子節點儲存整行資料
普通索引同時儲存主鍵索引鍵值
所有的索引都由兩個segment組成
leaf page segment
non-leaf page segment
表空間
獨立表空間優勢
表空間可更方便回收
透明表空間檔案遷移
共享表空間優勢
刪除大表或刪除大量資料時開銷更小,drop table/truncate table
可以使用裸裝置,據稱效能可能有提升。
表空間管理
消除碎片
alter table xx engine=innodb;
或者optimize table xx;
儘量用pt-osc來操作
回收表空間
獨立表空間:alter table xx engine = innodb;
共享表空間:重新匯入匯出
儘量用pt-osc來操作
表空間檔案遷移
目標伺服器上:alter table xx discard tablespace;
源伺服器上:flush table xx for export,備份過去,修改許可權
目標伺服器上:alter table xx import tablespace;
表結構務必一致
innodb_page_size也要一致
問:如何看innodb表的碎片?
答:show table status like ‘tab_name’,看data_length+index_length 然後看idb檔案,對比大小。
問:有表 查是400M 物理檔案9G,原因是什麼?
答:各種大欄位 varchar(4000)啊 text什麼的。。。
表空間檔案遷移步驟:(5.6以後)
1.在目標例項上建立一張和源例項表結構相同的表(表名可以不同)。
2.在目標例項上將表空間discard。 刪除舊錶空間檔案。
alter table xx discard tablespace(執行完這個命令之後,ibd檔案就沒有了,只剩frm檔案了)
3.在源例項上執行FLUSH TABLE xx FOR EXPORT。(執行完這個命令之後,表可以讀取,但無法修改,metadata lock。目錄下多了個.cfg檔案)
將檔案cp到目標例項上。並且修改檔案許可權。
4.在目標例項上執行import tablespace。源例項上unlock tables。
alter table xx import tablespace。
問:表空間遷移到目標例項後,有資料,但是資料行數、大小統計不到了。。。
答:anaylze table
通用表空間(general tablespace)(現在用的不多)
5.7+
類似oracle的做法
多個table放在同一個表空間中
可以定義多個通用表空間,並且分別放在不同的磁碟上
可以減少metadata的儲存開銷
和系統表空間類似,已分配佔有的表空間無法收縮歸還給作業系統(全部需重建)
臨時表空間,temporary tablespace
5.7+
獨立表空間檔案ibtmp1,預設12MB
例項關閉後,檔案也會刪除
例項啟動後,檔案新建立
無需參與crash recovery,因此也不記錄redo log
不支援壓縮
由innodb_temp_data_file_path定義
問:排序會用到臨時表空間嗎?
答:不會,只有create temporary table xxx;這種才會用到。
通用臨時表會用到。內部臨時表不會用到。
select * from x order by y; 由於沒有索引,產生的排序臨時表,稱為內部臨時表,如果session記憶體排序空間不足,會放到internal_tmp_disk_storage_engine指定的問題,磁碟臨時檔案。
create temporary table xxx; 通用臨時表
undo表空間,undo tablespace
5.6+獨立的undo表空間
儲存事務中的舊資料
innodb_undo_logs設定undo表空間個數
系統表空間總是需要1個undo表空間
臨時表空間總是需要32個undo表空間(5.7+)
因此,undo表空間總是必須大於33個,並且迴圈輪流使用
可以被線上truncate(5.7+)
當所有的undo加起來超過innodb_max_undo_log_size時,會觸發truncate工作
purge 執行innodb_purge_rseg_truncate_frequency次後,也會觸發truncate工作(預設128次)
建議使用獨立undo表空間
innodb是聚集索引組織表
基於B+樹
資料以聚集索引邏輯順序儲存
聚集索引優先選擇顯示定義的主鍵
其次選擇第一個非null的唯一索引
再次使用隱藏的rowid
聚集索引葉子節點儲存整行資料
普通索引同時儲存主鍵索引鍵值
所有的索引都由2個segment組成
leaf page segment
non-leaf page segment
儲存結構
tablespace -> segment -> extent(64個page,1M) -> page
page,頁
最小IO單位,16kB,5.6版本起可以自定義page size
每個page最少儲存兩行記錄(因為是B+tree結構,是雙向連結串列。因此必須儲存至少兩行記錄,才能前後互相連線起來。)
extent,區
空間管理單位
每個extent總是1MB,由64個page組成
如果page size是8kB的話,則由128個page組成
segment,段
物件單位,例如rollback seg,undo seg,data seg,index seg等
每個segment由N個extent以及32個零散page組成
segment最小以extent為單位擴充套件
tablespace,表空間
表儲存物件
每個tablespace都至少包含2個segment(葉子/非葉子 page file segment)
問:每個page至少兩行記錄,那如果是空表,怎麼辦?
答:每個page都至少有兩個虛擬記錄,這兩個虛擬記錄指向的是虛擬最小記錄和虛擬最大記錄,確保了每個page至少儲存兩行記錄。infimum, supermum
innodb主鍵
最好是自增屬性,INT/BIGINT最佳
資料型別長度小,效能更佳
資料順序寫入也是順序的,不會離散
也更有利於將更多普通索引放到buffer page中
主鍵儘量不要更新,否則更新主鍵時,輔助索引也要跟著更新。(想想為啥?輔助索引記錄主鍵值)
row,行記錄
row-format
redundant,最早的行格式
compat,5.0.3以後的預設行格式
dynamic,將長欄位完全off-page儲存
compressed,將data,index pages進行壓縮,但buffer pool中的page則不壓縮。壓縮比約1/2,但tps能下降到原來的1/10,不建議使用。
檢視行格式:select * from I_S.innodb_sys_tables where name like ‘%tab_name%’;
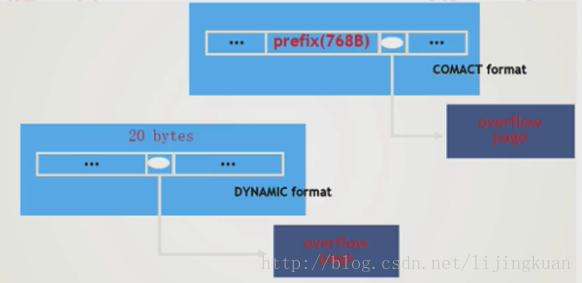
行溢位,overflow
行記錄長度大約超過page一半時,一次將最長的列拆分到多個page儲存,知道不在超過page的一般為止。
溢位的列放在一個page中不夠的話,還會繼續放在新的page中
compat格式下,溢位的列只儲存前768個位元組
dynamic格式下,溢位的列只儲存前20個位元組(指標)
select * 會同時讀取這些溢位的列,因此代價很高
出現filesort或temporary table時,一般都無法放在記憶體中,需要變成disk tmp table,IO代價更高。
每row中至少儲存幾個基本資訊
DB_ROW_ID,6byte,指向對應行記錄,每次寫新資料該ID自增,如果已有顯示宣告的主鍵,則不需要儲存DB_ROW_ID
DB_TRX_ID,6byte,每個事務的唯一識別符號
DB_ROLL_PTR,7bytes,指向undo的回滾指標
用於實現MVCC
注意:現在預設的資料檔案型別已經是Barracuda了,不是Antelope了,兩種最大區別是對於超長列的儲存。Antelope前768個位元組儲存在行裡,Barracuda只儲存20個位元組的指標。(只針對單行長度超過page大小一半的時候,才會overflow page,並不是只要出現blob或者text就一定會overflow的,單行長度不超過page大小一半,即使行中有blob列,也不overflow page)
記憶體管理
innodb buffer pool一般設定實體記憶體的50%-70%(5.7可以線上調整)
設定太大可能導致SWAP
使用多個buffer pool instance降低併發記憶體爭用(一般建議每個instance管理8-16G記憶體)
page採用hash演算法分配到多個instance中讀寫
每個緩衝區池管理自己的資料
innodb_buffer_pool_instances
每個instance管理自己的free list,flush list,LRU list及其他,並由各自的buffer pool mutex負責併發控制
可以線上修改buffer pool size
在啟動時預裝入buffer pool
innodb_buffer_pool_load_at_startup
innodb_buffer_pool_dump_at_shutdown
設定buffer pool重新整理機制
innodb_flush_method = O_DIRECT(繞過作業系統快取,直接寫陣列卡)
buffer pool管理
LRU機制
兩個列表,young ,old
優先放在young佇列
超過innodb_old_blocks_time後移入old佇列
old佇列預設佔比innodb_old_blocks_pct = 37
提問:在主從複製中,一張表若是除了一個非唯一的二級索引外並無其他索引,為什麼根據二級索引的索引列來更新,也需要校驗整行記錄的值,並且所有的值一致才能正常在slave上重放? 不是根據二級索引,得到一個內部的隱藏rowid就可以進行更新了嗎?
答:因為同一行的rowid在主從上不一定一致。
為什麼ROW格式日誌一定要用主鍵定位記錄,如果用二級索引行不行?雖然沒有主鍵那麼精準,但至少可以避免全表掃描。
根據主鍵做的更新,不會校驗行資料。