
innodb儲存引擎筆記(下)
mysql 5.6 optimizer_trace 檢視執行計劃選擇的過程
MVCC
innodb的多版本使用undo&回滾段來構建
innodb是聚集索引組織表,每個行記錄有3個額外屬性:ROW_ID、TRX_ID、ROLL_PTR
undo記錄了更改前的資料映象,若事務未提交,對隔離級別大於等於read commit的其他事務,它們不應該看到已修改(未提交)的資料,而應一致讀取老版本的資料
在修改聚集索引記錄時,總是同時儲存了ROLL_PTR和TRX_ID,可通過該ROLL_PTR找到對應的undo記錄,通過TRX_ID來判斷該記錄的可見性
當舊版本記錄中的TRX_ID指示對當前事務不可見時,則繼續向前(更新的TRX_ID)構建,知道找到一個可見的記錄。
innodb在表空間中儲存行的舊版本資訊,這些資訊被儲存在回滾段中
事務識別符號(TRX_ID)指示最後插入或更新這個行的事務識別符號,刪除標誌也被認為是一個更新,因為它在提交前指示在杭商做了一個標記。
回滾指標(DB_ROLL_PTR)指向一個由回滾段寫入的undo日誌記錄。如果一個行被更新了,undo日誌記錄包含了重建這行更新前的資訊的一些必要資料
回滾段中的undo日誌分為插入日誌(主要是insert操作)和更新日誌(包含update和delete)。插入日誌僅在事務回滾的時候有用,事務提交之後就可以馬上刪除掉。更新日誌在一致性讀的時候需要使用,如果當前沒有事務再可能使用回滾段中的記錄的時候,這些記錄就可以刪除掉了。因此,最好以適當頻率提交事務,否則innodb不能刪除掉過期更新日誌,回滾段越來越大。
回滾段中undo日誌記錄的物理大小要比其對應的插入或者更新的行要小(只記錄修改的列,不記錄完成的列)
當刪除某一行時,改行並不會馬上從資料庫的物理檔案上移除,只有當innodb可以清除更新日誌記錄的時候,那些行機器對應的索引記錄才會真正從物理上刪除掉,這個清楚操作成為purge。purge以前需要由主執行緒來掉地,現在5.6版本已經分離出來了
redo
ib_logfile檔案個數由innodb_log_files_in_group配置決定(至少>=2),檔名序號從0開始,從ib_logfile0到ib_logfileN
檔案為順序寫入,迴圈使用,當達到最後一個檔案末尾時,會從第一個檔案開始順序複用,redo檔案切換時,會執行一次checkpoint(刷redo log,刷dirty page)
例項重啟的過程中,例項關閉以後(正常關閉,不是崩潰),redo是可以刪掉的,例項開啟之後會重新初始化redo,但是undo不能刪
redo log用於記錄事務操作變化,記錄的是資料被修改之後的值(undo記錄的是資料被修改之前的值)
不會記錄臨時表空間上的變化(mysql 5.7起開始有獨立的臨時表空間)
redo記錄的是邏輯操作,類似binglog,不像oracle是塊記錄。它需要應用到一個正確的page上面,如果該page本身被破壞了,則無法恢復出正確的資料,所以需要用到double write buffer
會先放在log buffer(innodb_log_buffer_size)中,而不是立即寫磁碟
LSN:log sequence number,遞增的證書,表示redo總位元組數
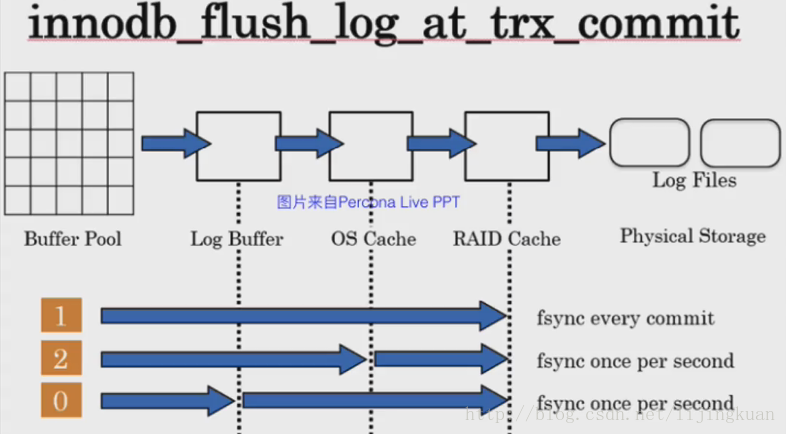
每次寫盤後是否flush,由引數innodb_flush_log_at_trx_commit控制
從5.5開始,redo的大小不再影響crash recovery的耗時,隻影響checkpoint頻率,設定較大值可減少IO消耗
redo log buffer重新整理條件
master thread每秒進行重新整理
redo log buffer使用大於1/2進行重新整理
事務提交時進行重新整理
innodb_flush_log_at_trx_commit={0|1|2}
設定innodb_flush_log_at_timeout(預設1秒)
innodb_flush_log_at_trx_commit
0,事務提交時不將redo log buffer寫入磁碟
1,事務提交時將redo log buffer寫入磁碟
2,事務提交時將redo log buffer些人作業系統快取
通常建議設定為1,並且設定sync_binlog=1,以保證資料可靠性(雙1)
innodb_log_buffer
通常8-32M就足夠了
innodb_log_file_size
一般設定為512M-4G
innodb_log_files_in_group
至少兩個檔案
redo log和binlog的區別
redo是物理邏輯日誌,binlog是邏輯日誌
redo是發起時間順序儲存,而binlog是按事務提交時間順序儲存
redo log file迴圈使用,binlog每次新增一個檔案
binlog更像oracle裡的redo歸檔
undo
用於實現MVCC以及回滾
當我們對記錄做了變更操作時就會產生undo記錄,記錄變更前的舊資料
undo記錄中儲存的是老版本的資料,當一箇舊的事務需要讀取老版本資料時,為了能讀到老版本的資料,需要順著undo鏈找到滿足可見性的記錄。當版本鏈很長時,通常可以認為這個是比較耗時的操作。
undo記錄預設被記錄到系統表空間(ibdata*)中,但是從5.6開始,也可以使用獨立的undo表空間
大多數對資料的變更操作包括insert/delete/update
其中insert操作在事務提交前只對當前事務可見,因此產生的undo日誌可以在事務提交後直接刪除,歸類為insert_undo
而對於update/delete則需要維護多版本資訊,在innodb裡,update和delete操作產生的undo日誌被歸為一類,即update_undo
MySQL5.7在undo上面的變化
innodb_undo_logs,rollback seg數量,比如將2G的undo tablespace,切分成多少分rollback seg。預設128個,例項初始化後不可再修改。每個undo log seg可以最多存放1024個事務
innodb_undo_tablespaces,undo log檔案數,每個檔案預設10MB,數量預設0,最大95個,最小2個,因為在truncate一個undo log檔案時,需要保證另外一個是可用的,這樣就無需停止業務了
innodb_max_undo_log_size,控制最大undo tablespace檔案的大小,超過這個值嘗試truncate undo logs,truncate後的undo logs大小預設恢復為10M
innodb_purge_rseg_truncate_frequency,用於控制purge回滾段的頻率,預設128,表示purge undo輪詢128次後,進行一次undo的truncate
innodb_max_purge_lag = 10000 (如果值不為0,當目前所有未purge的undo,如果超過10000,那麼新發生的DML都會被阻塞一小段時間)innodb_max_purge_lag 最好設定為0(即預設值)
innodb_max_purge_lag_delay = 10000(每10秒至少做一次purge)
以上兩個引數的案例,可以參考老葉茶館的文章《是誰,把innodb表上的DML搞慢的?》
MySQL5.7之後
支援線上truncate不用的undo logs
set global innodb_undo_log_truncate = 1,手工truncate undo log
當undo超過innodb_max_undo_log_size時進行truncate
總結:三種truncate操作:手工,128次,超過max size
show engine innodb status 裡的history list length
已提交事務,但未purge的update undo log,也就是等待purge的undo log的大小
事務在redo log、binlog中的邏輯過程
a)事務寫入redo log buffer
b)將log buffer重新整理到redo log,不過會先寫TRX prepare標記
c)寫binlog
d)在redo log寫入TRX commit標記
e)將寫binlog成功的標記寫入redo log
若binlog寫入完成,則主從庫都會正常完成事務;binlog沒有寫入,則主從庫都不會完成事務。不會出現主從不一致的問題,除非trx_commit=0/2才有這個風險
slave上master&relay info repository必須是TABLE,且設定relay_log_recovery=1,另外master那邊設定雙1,才能保證主從資料一致性。
innodb後臺執行緒
預設有15個
- master thread(1個)
- IO thread
- read/write thread(8個,讀寫預設各4個)
- insert buffer thread(1個)
- log io thread(1個)
- lock monitor thread(1個)
- error monitor thread(1個)
- purge thread(1個)
- page cleaner(flushing) thread(1個)
- MySQL5.6起,master thread的工作已被大大減輕,purge,page clean等成獨立執行緒了
後臺執行緒
master thread(主執行緒)的執行緒優先級別最高
其內部幾個迴圈(loop)組成:主迴圈(loop),後臺迴圈(background loop),重新整理迴圈(flush loop),暫停迴圈(suspend loop)
會根據資料執行的狀態在loop,background loop,flush loop和suspend loop中進行切換
loop成為主迴圈,因為大多數的操作都在這個迴圈中
loop迴圈通過thread sleep來實現,這意味著所謂的每秒一次或10秒一次的操作時不精確的
在負載很大的情況下可能會有延遲
master thread
master thread
2個迴圈
每秒要做的事
每10秒要做的事
如何檢視:
5.6以後select * from performance_schema.threads limit 10;
5.6以前show engine innodb status,從background thread裡面檢視

每秒要做的事
重新整理dirty page到磁碟
執行insert buffer merge(change buffer)
刷redo log buffer到磁碟
checkpoint
檢查dict table cache,判斷有無需要刪除table cache物件
每10秒要做的事
重新整理dirty page到磁碟
執行insert buffer merge
刷redo log buffer到磁碟
undo purge
checkpoint
例項關閉時
刷redo log到磁碟
insert buffer merge
刷redo log buffer 到磁碟
執行checkpoint
優化建議
避免dirty page堆積,適當調整innodb_max_dirty_pages_pct(<=50)
避免undo堆積,調整innodb_max_purge_lag/innodb_max_purge_lag_delay/innodb_purge_batch_size
及時checkpoint,調整innodb_flush_log_at_trx_commit/innodb_adaptive_flushing/innodb_adaptive_flush_lwm/innodb_flush_neighbors/innodb_flush_avg_loops
保持事務持續平穩提交,不要瞬間大事務,或者高頻率小事務
checkpiont
定期確認redo log落盤,避免資料丟失,並提高crash recovery效率
buffer pool髒資料太多,把髒頁重新整理到磁碟,釋放記憶體
redo log快用完了,把髒頁重新整理到磁碟
redo log切換時,需要執行checkpoint
---
LOG
---
Log sequence number 693064238
Log flushed up to 693064238
Pages flushed up to 693064238
Last checkpoint at 693064238
Max checkpoint age 651585393
Checkpoint age target 631223350
Modified age 0
Checkpoint age 0
0 pending log writes, 0 pending chkp writes
8 log i/o's done, 0.00 log i/o's/second12345678910111213
checkpoint兩種方式
sharp checkpoint
將所有髒頁都重新整理回磁碟
重新整理時系統hang住
比較暴力,只有在需要乾淨重啟是才需要
innodb_fast_shutdown = 0
0,slow,full purge,insert buffer merge(也就是不允許fast shutdown,要求做完整的關閉操作)
1,預設,fast,skip these operation
2,flush logs,cold status,like crashed
fuzzy checkpoint
持續將髒頁重新整理回磁碟
對系統影響較小,但可能重新整理較慢,會有遲滯
innodb_max_dirty_pages_pct = 75
innodb_max_dirty_pages_pct_lwm = 0
問:什麼情況下innodb_fast_shutdown要設為0(保證資料安全)
答:
1. 例項升級版本
2. 主從切換
3. 例項遷移
4. 物理關機
page cleaner(flushing)(髒頁的重新整理)
將髒頁重新整理落地到硬碟
有兩種方式
LRU Flushing,基於LRU_list(基於最後訪問時間的排序)的重新整理順序
Adaptive Flushing,基於Flush_list(嚴格按照最後修改時間的順序,LSN)的重新整理順序,innodb_adaptive_flushing = 1
掃描列表,並找到鄰居頁面(innodb_flush_neighbors = 1,機械盤適用,SSD盤可關閉),一起重新整理
重新整理過程
將髒頁拷貝到double write buffer
重新整理double write buffer到檔案
同步double write buffer到磁碟
寫資料檔案
同步刷資料檔案到磁碟,確保落地
undo purge
簡單說,就是GC(garabge collection)
purge都做啥
刪除輔助索引中不存在的記錄
刪除已被打了delete-mark標記的記錄
刪除不需要的undo log
從5.6開始,將purge thread獨立出來
–innodb_purge_threads = 1
–innodb_max_purge_lag = 0
–innodb_purge_batch_size = 300
案例:刪除大量舊資料後,統計min(pkid)很慢
insert buffer/change buffer
將非唯一輔助索引上的IUD操作從隨機變成順序IO,提高IO效率
官方測試號稱約提高15倍
工作機制
先判斷插入的非聚集索引頁是否在緩衝池中,若在,則直接插入
若不在,則先放入到一個change buffer物件中
change buffer也是棵樹,B+樹
每次最多快取2k的記錄
當讀取輔助索引頁到緩衝池,將insert buffer中該頁的記錄合併到輔助索引項
–innodb_change_buffer_max_size(這個是百分比,預設25%,表示最多有25%的buffer pool用來做change buffer)
–innodb_change-buffering(預設all,即包括insert update delete,none就是什麼都不做,此外還有insert,update,delete)
1.fast shutdown不進行insert buffer合併
2.insert buffer進行合併插入時,tps會受影響
3.insert buffer佔用一部分buffer pool,如果輔助索引不多,可以考慮關閉或調低insert buffer
show engine innodb status檢視insert buffer相關內容
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 1289, seg size 1291, 316623 merges
merged operations:
insert 249806, delete mark 1123127, delete 85482
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 2365399, node heap has 3863 buffer(s)
Hash table size 2365399, node heap has 2606 buffer(s)
Hash table size 2365399, node heap has 3849 buffer(s)
Hash table size 2365399, node heap has 2100 buffer(s)
Hash table size 2365399, node heap has 2409 buffer(s)
Hash table size 2365399, node heap has 6709 buffer(s)
Hash table size 2365399, node heap has 1118 buffer(s)
Hash table size 2365399, node heap has 3659 buffer(s)
37515.35 hash searches/s, 4553.64 non-hash searches/s1234567891011121314151617
註釋:
size 1 =>正在使用的page
free list len => 空閒的page
seg size =>總的insert buffer page數量size + free list len + 1
insert buffer的效果 = merges / (insert + delete mark + delete)
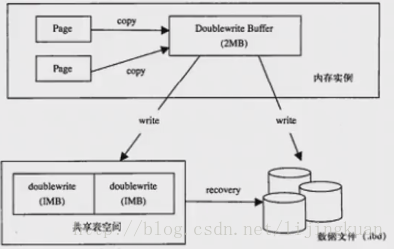
double write,雙寫
目的/作用:保證資料寫入的可靠性(防止資料頁損壞,又無從修復)
因為innodb有partial write問題
16k的頁只寫入了部分資料時發生crash
redo裡記錄的是邏輯操作,不是物理塊,無法通過redo恢復
怎麼解決partial write問題
雙寫,double write
2個1M的空間,共2M(既有磁碟檔案,也有記憶體空間)
頁在重新整理時首先順序的寫入到double write buffer
然後再重新整理回磁碟
在可以保證原子寫的硬體裝置或檔案系統下,可以被關閉
slave上也可以關閉
double write寫入是順序的,效能損失很小(SSD裝置上損失則比較大)
MySQL5.7起,採用PCIe SSD裝置是會自動判斷,是否要關閉double write buffer
先寫double buffer,再寫磁碟,如果double write寫失敗了,那麼肯定沒寫入磁碟
double write的狀態統計(mysqladmin ext | grep -i dbl)
innodb_dblwr_pages_written(發起多少次寫的請求)
innodb_dblwl_writes(實際寫了多少次)
理想比例是64:1,因為1M包含64個page,但是很難達到這高比例
效能損失
–innodb_double = 0關閉,1開啟
status
innodb_dblwr_pages_written
innodb_dblwr_writes
預熱
buffer pool dump& restor 啟動預熱
innodb_buffer_pool_filename
innodb_buffer_pool_dump_now
innodb_buffer_pool_dump_at_shutdown
innodb_buffer_pool_load_now
innodb_buffer_pool_load_at_startup
手工預熱
select count(*) from t force index(primary)
select count(*) from t
select * from t
可以防止資料庫剛開起來因為承受不了瞬間到來的物理讀請求而秒崩,強烈建議開啟(5.6以後才有的功能,且可以線上動態開啟)。
adaptive hash index
對buffer pool中熱點索引頁資料再次進行索引
目的:快取索引中的熱點資料,提高檢索效率,O(1) VS O(N)(從對B+樹的搜尋變為對hash的搜尋)
對熱點buffer pool建立AHI,非持久化
只支援等值查詢
idx_a_b(a,b)
where a = xx
where a = xx and b = xx
AHI很可能是部分長度索引,並非所有查詢都能有效果
設定innodb_adaptive_hash_index = 0 關閉
設定innodb_adaptive_hash_index_parts 使用AHI分割槽/分片降低競爭提高併發
個別場景下,開了AHI後,可能導致spin_wait lock 比較大,可以關閉掉
評估自適應hash索引的作用(show engine innodb status)
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 1289, seg size 1291, 316623 merges
merged operations:
insert 249806, delete mark 1123127, delete 85482
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 2365399, node heap has 3863 buffer(s)
Hash table size 2365399, node heap has 2606 buffer(s)
Hash table size 2365399, node heap has 3849 buffer(s)
Hash table size 2365399, node heap has 2100 buffer(s)
Hash table size 2365399, node heap has 2409 buffer(s)
Hash table size 2365399, node heap has 6709 buffer(s)
Hash table size 2365399, node heap has 1118 buffer(s)
Hash table size 2365399, node heap has 3659 buffer(s)
37515.35 hash searches/s, 4553.64 non-hash searches/s1234567891011121314151617
注:AHI的作用 hash searches / (hash searches + non-hash searches)
crash recovery
redo,redo前滾結束後,server開始對外提供服務,後面的過程放在後臺執行緒繼續工作
當例項從崩潰中恢復,需要將活躍的事務從undo中提取出來,對於ACTIVE狀態的事務直接回滾,對於prepare狀態的事務,如果該事物對應的binlog已經記錄,則提交,否則回滾事務
change buffer merge
purge
xa recover
加快crash recovery速度
升級到5.5以後的版本
提高IO裝置效能
適當調低innodb_max_dirty_pages_pct,50以下
設定innodb_flush_log_at_trx_commit = 1,讓每個事務儘快提交,避免有其他事務等待,產生大量的undo,增加purge工作量
5.7又進一步改進,crash recovery時無需掃描所有資料檔案並建立記憶體物件(資料檔案巨多時會產生嚴重效能問題),而只檢查checkpoint+那些標記為被修改過的檔案,從一個checkpoint點開始,可以找到所有崩潰恢復需要開啟的檔案,從而避免掃描資料目錄
innodb引擎重點引數
innodb_buffer_pool_size
最大的記憶體塊,建議為實體記憶體的50-80%
innodb_max_dirty_pages_pct
buffer pool中dirty page最大佔比,建議不超過50%
innodb_old_blocks_pct
buffer pool中old block sublist最大佔比,預設3/8
innodb_change_buffering
change buffer 型別,ALL或其他
innodb_log_buffer_size
redo log buffer,能快取5秒左右產生的redo就夠,32MB基本管夠
innodb_sort_buffer_size???(後續研究)
innodb往表中批量載入資料更新索引。以及Online DDL時,將當前發生的DML記錄到臨時log中???。(不要只看字面意思)
innodb_data_file_path
共享表空間初始大小,建議至少1G以上
innodb_log_file_size
redo log大小,加大有助於減小checkpoint頻率,提高tps
innodb_flush_log_at_trx_commit
redo log重新整理機制,1最安全,0效能最好,2折中
innodb_io_capacity
innodb 後臺執行緒最大iops上限
innodb_flush_methon
重新整理innodb data file和log file使用方式,推薦O_DIRECT
innodb_stats_on metadat = 0
執行show table status / show index時是否更新統計資訊
innodb_autoinc_lock_mod = 1
auto-inc鎖模式,推薦1
innodb_file_per_table =1
是否啟用獨立表空間,推薦1。5.5開始可動態修改
innodb_fast_shutdown = 0/1
是否快速關閉,推薦1。需要版本升級或機器重啟是,要改為0。
innodb_force_recovery = 0
innodb恢復級別,可選0-6,從最小開始嘗試啟動。預設一定要設定為0。