
深度學習(一)-CNN原理研究
https://blog.csdn.net/xiake001/article/details/78403482
基本概念
協方差矩陣
線性與非線性
“線性”=”齊次性”+”可加性”, “齊次性”是指類似於: f(ax)=af(x), “可加性”是指類似於: f(x+y)=f(x)+f(y), 這裡沒有太多特別的原因, 就是一個名字. “非線性”當然就是這兩條至少之一不成立.
似然函式
凹凸函式
定義 若這裡凸集C即某個區間I,那麼就是:設f為定義在區間I上的函式,若對I上的任意兩點 和任意的實數 ,總有

則f稱為I上的凸函式,當且僅當其上境圖(在函式影象上方的點集)為一個凸集。
判定 對於實數集上的凸函式,一般的判別方法是求它的二階導數,如果其二階導數在區間上非負,就稱為凸函式。(向下凸) 如果其二階導數在區間上恆大於0,就稱為嚴格凸函式。
梯度下降法
啟用函式
反向傳播演算法
監督與非監督學習
主成分分析(Principal Components Analysis,PCA)
PCA是用來資料降維的。思想是:假設nxn的矩陣A,有協方差矩陣B,計算B的n個特徵值和特徵向量 U = [u1 u2….un]。U就構成了n維空間的新基,將特徵值按從大到小排列,取前K個特徵向量。
資料旋轉 對矩陣A進行在U基上進行旋轉,即
Arot=UT∗AArot=UT∗A
降維 將矩陣A從n維降到k維,只需取 ArotArot的前K個成分。
選擇主成分個數 一般採用經驗法,計算方差百分比大於99%,即從n個特徵值(從大到小排序)取前k個特徵值,使得:
K=∑ki=0λi∑ni=0λi>=0.99K=∑i=0kλi∑i=0nλi>=0.99
CNN的整體網路結構
卷積神經網路( Convolutional Neural Network,簡稱CNN)是深度學習的一種重要演算法。卷積神經網路是在BP神經網路的改進,與BP類似,都採用了前向傳播計算輸出值,反向傳播調整權重和偏置;CNN與標準的BP最大的不同是:CNN中相鄰層之間的神經單元並不是全連線,而是部分連線,也就是某個神經單元的感知區域來自於上層的部分神經單元,而不是像BP那樣與所有的神經單元相連線。
CNN的有三個重要的思想架構:
1.區域性區域感知
每一個神經元都不需要對全域性影象做感受,每個神經元只感受區域性的影象區域,然後在更高層,將這些感受不同區域性的神經元綜合起來就可以得到全域性的資訊了。
隱含層每個神經元負責影象的一部分割槽域,綜合起來就是整個影象。例如:影象是1000x1000畫素,而濾波器大小是10x10,假設濾波器沒有重疊,也就是步長為10,這樣隱層的神經元個數就是(1000x1000 )/ (10x10)=100x100個神經元了。這只是一種濾波器,也就是一個Feature Map的神經元個數,如果100個Feature Map就是100倍了。需要注意的一點是,上面的討論都沒有考慮每個神經元的偏置部分。所以權值個數需要加1 。這個也是同一種濾波器共享的。

2.權重共享
每個神經元與區域性區域的連線權值引數都是一樣的,也就是說它們共享一個過濾器(即卷積核),但是這隻能過濾一種特徵。如果需要關注多個特徵,就設計多個卷積核。
權值共享網路結構使之更類似於生物神經網路,降低了網路模型的複雜度,減少了權值的數量。該優點在網路的輸入是多維影象時表現的更為明顯,使影象可以直接作為網路的輸入,避免了傳統識別演算法中複雜的特徵提取和資料重建過程。卷積網路是為識別二維形狀而特殊設計的一個多層感知器,這種網路結構對平移、比例縮放、傾斜或者共他形式的變形具有高度不變性。
3.空間或時間上的降取樣
為什麼是下采樣?利用影象區域性相關性的原理,對影象進行子抽樣,可以減少資料處理量同時保留有用資訊。
對於一個 96X96 畫素的影象,假設我們已經學習得到了400個定義在8X8輸入上的特徵,每一個特徵和影象卷積都會得到一個 (96 − 8 + 1) × (96 − 8 + 1) = 7921 維的卷積特徵,由於有 400 個特徵,所以每個樣例 (example) 都會得到一個 7921 × 400 = 3,168,400 維的卷積特徵向量。學習一個擁有超過 3 百萬特徵輸入的分類器十分不便,並且容易出現過擬合 (over-fitting)。
為了解決這個問題,首先回憶一下,我們之所以決定使用卷積後的特徵是因為影象具有一種“靜態性”的屬性,這也就意味著在一個影象區域有用的特徵極有可能在另一個區域同樣適用。因此,為了描述大的影象,一個很自然的想法就是對不同位置的特徵進行聚合統計,例如,人們可以計算影象一個區域上的某個特定特徵的平均值 (或最大值)。這些概要統計特徵不僅具有低得多的維度 (相比使用所有提取得到的特徵),同時還會改善結果(不容易過擬合)。這種聚合的操作就叫做池化 (pooling),有時也稱為平均池化或者最大池化 (取決於計算池化的方法)。
CNN整體網路結構

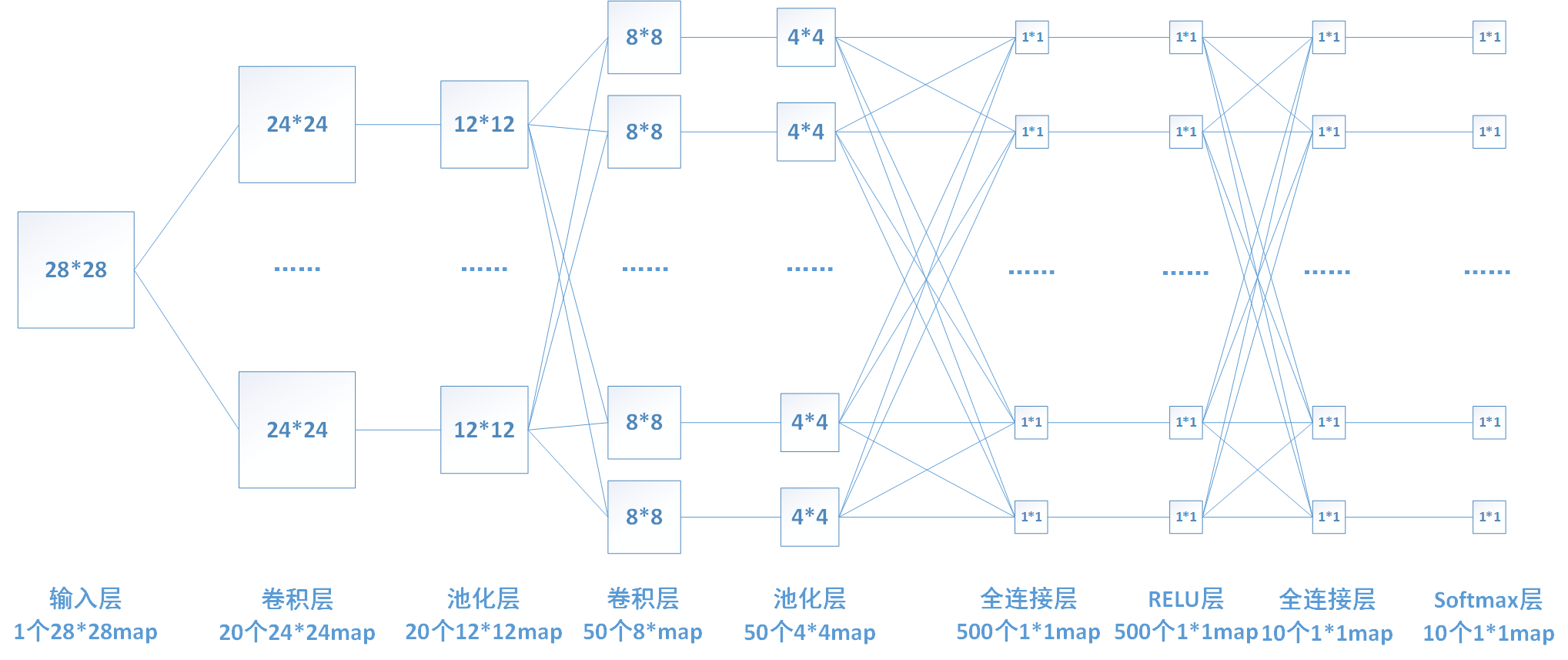
下面我來推導一下每層的神經元數目和引數的個數。 1、輸入層:輸入層輸入一個28*28的圖片。 2、卷積層1:該層使用20個5*5的卷積核分別對輸入層圖片進行卷積,所以包含20*5*5=500個引數權值引數。卷積後圖片邊長為(28-5+1)/1 = 24,故產生20個24*24個map,包含20*24*24 = 11520個神經元。 3、池化(pooling)層1:對上一層每個2*2區域進行降取樣,選取每個區域最大值,這一層沒有引數。降取樣過後每個map的長和寬變為原來的一半。 4、卷積層2:該層使用50個5*5的卷積核分別對上一層的20個map進行卷積(每個卷積核一次同時對20個map進行卷積),所以包含50*5*5=1250個引數權值引數。卷積後圖片邊長為(12-5+1)/1 = 8,故產生50個8*8個map,包含50*8*8 = 3200個神經元。 5、池化層2:和上一個池化層功能類似,將8*8的map降取樣為4*4的map。該層無引數。 6、全連線層1:將上一層的所有神經元進行連線,該層含有500個神經元,故一共有50*4*4*500 = 400000個權值引數。 7、relu層:啟用函式層,實現x=max[0,x],該層神經元數目和上一層相同,無權值引數。 8、全連線層2:功能和上一個全連線層類似,該層共有10個神經元,包含500*10=5000個引數。 9、softmax層:實現分類和歸一化。
卷積層
卷積輸出大小計算 輸入圖片大小:nxn 卷積核大小:fxf 步長:s Padding大小:p,假設上下補齊一樣大 則卷積輸出大小為:[(n+2p-f)/s + 1],向下取整。
卷積層的前向計算
輸入為28*28的影象,經過5*5的卷積之後,得到一個(28-5+1)*(28-5+1) = 24*24、的map。卷積層2的每個map是不同卷積核在前一層每個map上進行卷積,並將每個對應位置上的值相加然後再加上一個偏置項。
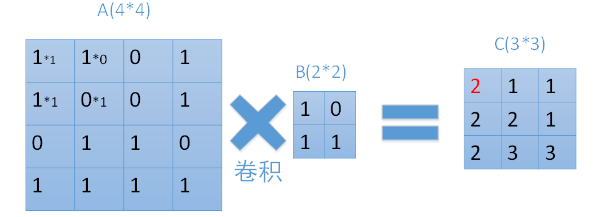
每次用卷積核與map中對應元素相乘,然後移動卷積核進行下一個神經元的計算。如圖中矩陣C的第一行第一列的元素2,就是卷積核在輸入map左上角時的計算結果。在圖中也很容易看到,輸入為一個4*4的map,經過2*2的卷積核卷積之後,結果為一個(4-2+1) *(4-2+1) = 3*3的map。
卷積層的後向計算
在反向傳播過程中,若第x層的a節點通過權值W對x+1層的b節點有貢獻,則在反向傳播過程中,梯度通過權值W從b節點傳播回a節點。 在上圖中,我們的矩陣A11通過權重B11與C11關聯。而A12與2個矩陣C中2個元素相關聯,分別是通過權重B12和C11關聯,和通過權重B11和C12相關聯。矩陣A中其他元素也類似。
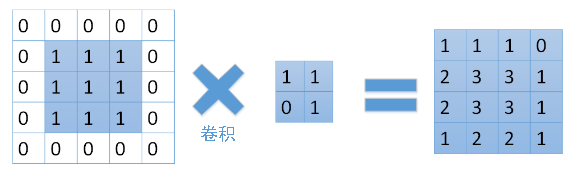
那麼,我們有沒有簡單的方法來實現這樣的關聯呢。答案是有的。可以通過將卷積核旋轉180度,再與擴充後的梯度矩陣進行卷積。擴充的過程如下:如果卷積核為k*k,待卷積矩陣為n*n,需要以n*n原矩陣為中心擴充套件到(n+2(k-1))*(n+2(k-1))。具體過程如下: 假設D為反向傳播到卷積層的梯度矩陣,則D應該與矩陣C的大小相等,在這裡為3*3。我們首先需要將它擴充到(3+2*(2-1))* (3+2*(2-1)) = 5*5大小的矩陣。
同時將卷積核B旋轉180度:
將旋轉後的卷積核與擴充後的梯度矩陣進行卷積:
實際上convn內部是否旋轉對網路訓練沒有影響。計算出的梯度矩陣就可以用來更新權值與偏置了。
池化層
池化層的輸入一般來源於上一個卷積層,主要作用是提供了很強的魯棒性(例如max-pooling是取一小塊區域中的最大值,此時若此區域中的其他值略有變化,或者影象稍有平移,pooling後的結果仍不變),並且減少了引數的數量,防止過擬合現象的發生。池化層一般沒有引數,所以反向傳播的時候,只需對輸入引數求導,不需要進行權值更新。
池化輸出大小計算 採用卷積一樣的公式,則卷積輸出大小為:[(n+2p-f)/s + 1],向下取整。
前向計算
前向計算過程中,我們對卷積層輸出map的每個不重疊(有時也可以使用重疊的區域進行池化)的n*n區域(我這裡為2*2,其他大小的pooling過程類似)進行降取樣,選取每個區域中的最大值(max-pooling)或是平均值(mean-pooling),也有最小值的降取樣,計算過程和最大值的計算類似。
後向計算
對於max-pooling,在前向計算時,是選取的每個2*2區域中的最大值,這裡需要記錄下最大值在每個小區域中的位置。在反向傳播時,只有那個最大值對下一層有貢獻,所以將殘差傳遞到該最大值的位置,區域內其他2*2-1=3個位置置零。具體過程如下圖,其中4*4矩陣中非零的位置即為前邊計算出來的每個小區域的最大值的位置。
對於mean-pooling,我們需要把殘差平均分成2*2=4份,傳遞到前邊小區域的4個單元即可。
區域性響應歸一化LRN(Local Response Normalization)
全連線層
全連線層的每一個結點都與上一層的所有結點相連,用來把前邊提取到的特徵綜合起來。由於其全相連的特性,一般全連線層的引數也是最多的。
正則化及Dropout層
正則化及Dropout都能很好的防止過擬合。
正則化 P-範數公式
∥x∥p=(∑i=0∞|xpi|)1p‖x‖p=(∑i=0∞|xip|)1p
L1範數:
λ∥x∥1λ‖x‖1
L2範數:
λ2∥x∥2λ2‖x‖2
softmax層
Softmax迴歸模型是logistic迴歸模型在多分類問題上的推廣,在多分類問題中,待分類的類別數量大於2,且類別之間互斥。比如我們的網路要完成的功能是識別0-9這10個手寫數字,若最後一層的輸出為[0,1,0, 0, 0, 0, 0, 0, 0, 0],則表明我們網路的識別結果為數字1。 Softmax的公式為
,可以直觀看出如果某一個zj大過其他z,那這個對映的分量就逼近於1,其他就逼近於0,並且對所有輸入資料進行歸一化。
引數初始化、更新、調優
權值初始化
權值更新
引數調優
Paper Reading
AlexNet
VGGNet
LeNet-5(難懂)
精讀第2段,泛讀第3段
疑問
1.對一張圖片進行卷積,邊緣特徵如何保證檢測到?例如在一張 32 x 32 的輸入影象上,5 x 5 的過濾器能夠覆蓋到 784 個不同的位置。這 784 個位置可對映為一個 28 x 28 的陣列 A:Zero Padding。就是在32x32周圍增加兩層0變成36x36,這樣就達到了卷積後仍保持32x32
2.每層卷積核大小3x3/5x5是經驗選擇?每層卷積核數量如何確定? A: