深度學習(六)——CNN進化史
CNN進化史
計算機視覺

6大關鍵技術:

影象分類:根據影象的主要內容進行分類。資料集:MNIST, CIFAR, ImageNet
物體定位:預測包含主要物體的影象區域,以便識別區域中的物體。資料集:ImageNet
物體識別:定位並分類影象中出現的所有物體。這一過程通常包括:劃出區域然後對其中的物體進行分類。資料集:PASCAL, COCO
語義分割:把影象中的每一個畫素分到其所屬物體類別,在樣例中如人類、綿羊和草地。資料集:PASCAL, COCO
例項分割:把影象中的每一個畫素分到其所屬物體例項。資料集:PASCAL, COCO
關鍵點檢測:檢測物體上一組預定義關鍵點的位置,例如人體上或者人臉上的關鍵點。資料集:COCO
CNN簡史


AlexNet
2012年,ILSVRC比賽冠軍的model——Alexnet(以第一作者Alex命名)的結構圖如下:
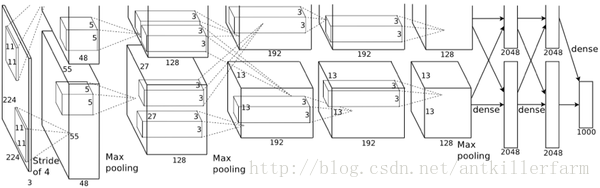
換個視角:
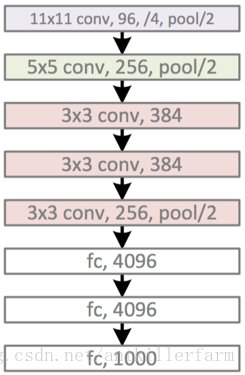
AlexNet的caffe模板:
其中的LRN(Local Response Normalization)層也是當年的遺蹟,被後來的實踐證明,對於最終效果和運算量沒有太大幫助,因此也就慢慢廢棄了。
雖然,LeNet-5是CNN的開山之作(它不是最早的CNN,但卻是奠定了現代CNN理論基礎的模型),但是畢竟年代久遠,和現代實用的CNN相比,結構實在過於原始。
AlexNet作為第一個現代意義上的CNN,它的意義主要包括:
1.Data Augmentation。包括水平翻轉、隨機裁剪、平移變換、顏色、光照變換等。
2.Dropout。
3.ReLU啟用函式。
4.多GPU平行計算。
5.當然最應該感謝的是李飛飛團隊搞出來的標註資料集合ImageNet。
注:ILSVRC(Large Scale Visual Recognition Challenge)大賽,在2016年以前,一直是CV界的頂級賽事。但隨著技術的成熟,目前的科研重點已經從物體識別轉移到了物體理解領域。2017年將是該賽事的最後一屆。WebVision有望接替該賽事,成為下一個目標。
VGG
Visual Geometry Group是牛津大學的一個科研團隊。他們推出的一系列深度模型,被稱作VGG模型。
VGG的結構圖如下:
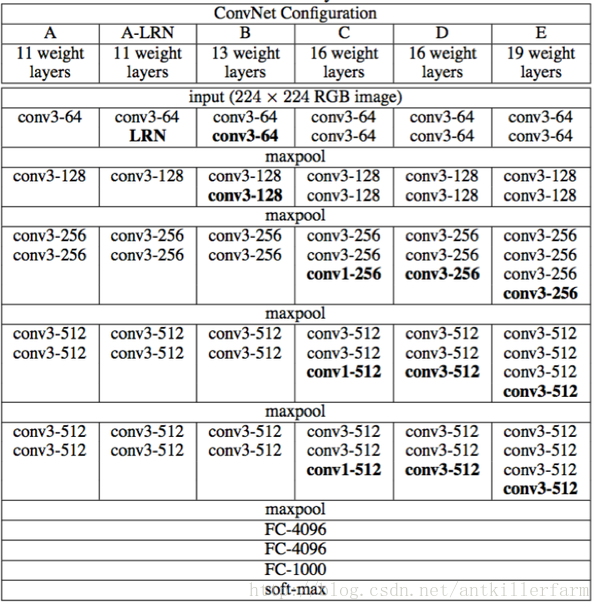
該系列包括A/A-LRN/B/C/D/E等6個不同的型號。其中的D/E,根據其神經網路的層數,也被稱為VGG16/VGG19。
從原理角度,VGG相比AlexNet並沒有太多的改進。其最主要的意義就是實踐了“神經網路越深越好”的理念。也是自那時起,神經網路逐漸有了“深度學習”這個別名。
GoogleNet
GoogleNet的進化道路和VGG有所不同。VGG實際上就是“大力出奇跡”的暴力模型,其他地方不足稱道。
而GoogleNet不僅繼承了VGG“越深越好”的理念,對於網路結構本身也作了大膽的創新。可以對比的是,AlexNet有60M個引數,而GoogleNet只有4M個引數。
因此,在ILSVRC 2014大賽中,GoogleNet獲得第一名,而VGG屈居第二。
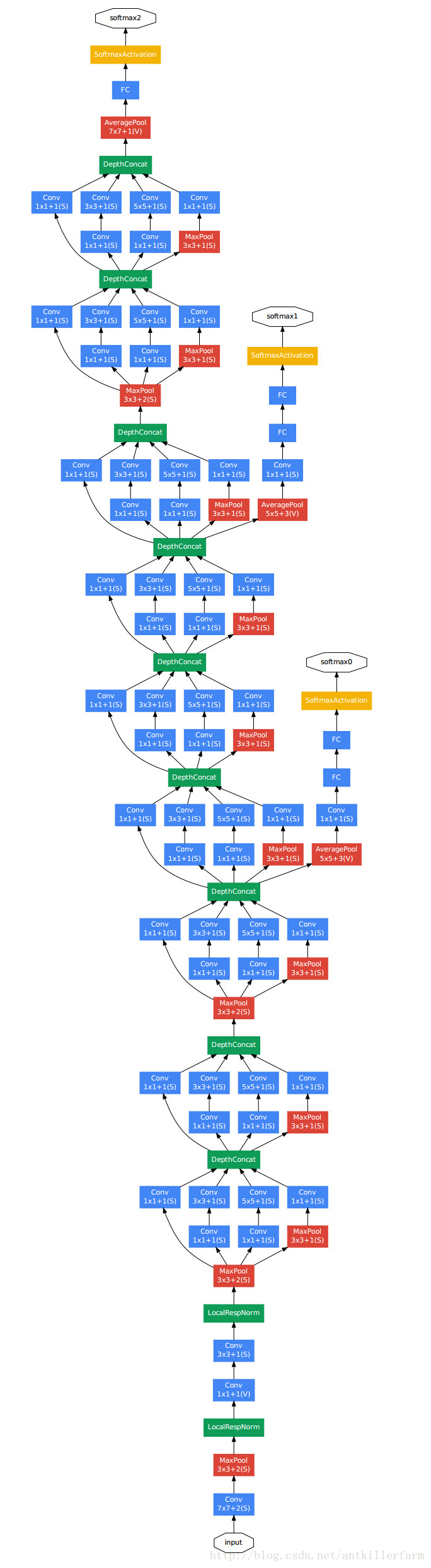
上圖是GoogleNet的結構圖。從中可以看出,GoogleNet除了AlexNet的基本要素之外,還有被稱作Inception的結構。
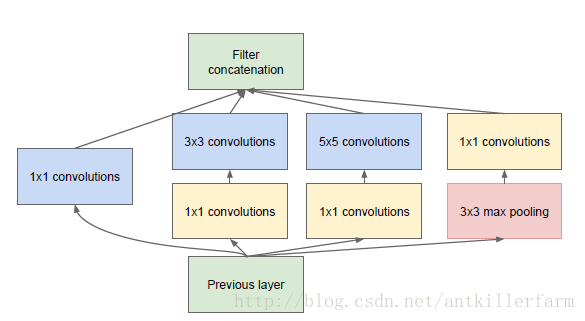
上圖是Inception的結構圖。它的原理實際上就是將不同尺寸的卷積組合起來,以提供不同尺寸的特徵。
原始的GoogleNet也被稱作Inception-v1。在後面的幾年,GoogleNet還提出了幾種改進的版本,最新的一個是Inception-v4(2016.8)。
論文:
《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》
Inception系列的改進方向基本都集中在構建不同的Inception模型上。
GoogleNet的另一個改進是減少了全連線層(Full Connection, FC),這是減少模型引數的一個重要改進。事實上,在稍後的實踐中,人們發現去掉VGG的第一個FC層,對於效果幾乎沒有任何影響。
SqueezeNet
GoogleNet之後,最有名的CNN模型當屬何愷明的Deep Residual Network。DRN在《深度學習(五)》中已有提及,這裡不再贅述。
DRN之後,學界的研究重點,由如何提升精度,轉變為如何用更少的引數和計算量來達到同樣的精度。SqueezeNet就是其中的代表。
論文:
《SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size》
程式碼:
Caffe版本
TensorFlow版本
SqueezeNet最大的創新點在於使用Fire Module替換大尺寸的卷積層。
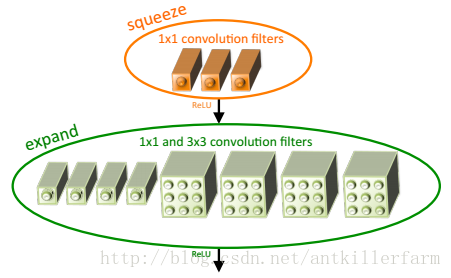
上圖是Fire Module的結構示意圖。它採用squeeze層+expand層兩個小卷積層,替換了AlexNet的大尺寸卷積層。其中,
這裡需要特別指出的是:expand層採用了2種不同尺寸的卷積,這也是當前設計的一個趨勢。
這個趨勢在GoogleNet中已經有所體現,在ResNet中也間接隱含。
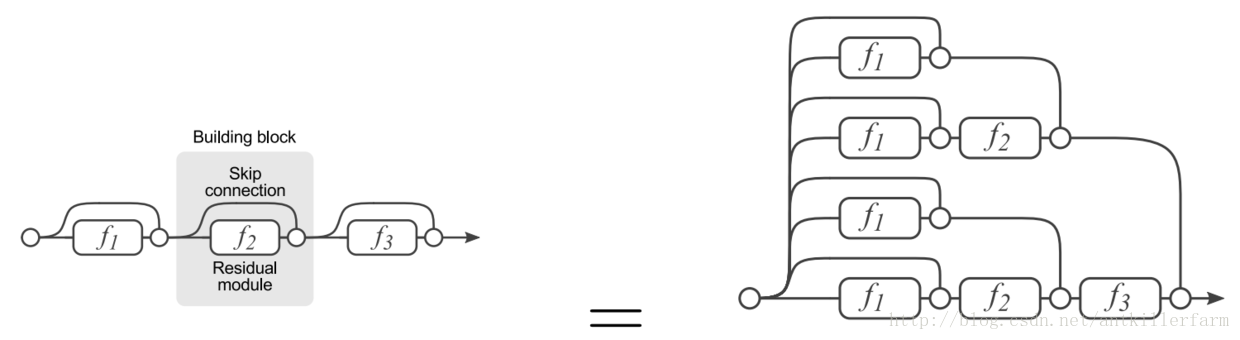
上圖是ResNet的展開圖,可見展開之後的ResNet,實際上等效於一個多尺寸交錯混編的複雜卷積網。其思路和GoogleNet實際上是一致的。
參見:
最新SqueezeNet模型詳解,CNN模型引數降低50倍,壓縮461倍!
神經網路瘦身:SqueezeNet
超輕量級網路SqueezeNet演算法詳解
參考
計算機視覺識別簡史:從AlexNet、ResNet到Mask RCNN
詳解CNN五大經典模型:Lenet,Alexnet,Googlenet,VGG,DRL
Deep Learning回顧之LeNet、AlexNet、GoogLeNet、VGG、ResNet
Google最新開源Inception-ResNet-v2,藉助殘差網路進一步提升影象分類水準
站在巨人的肩膀上,深度學習的9篇開山之作
解讀Keras在ImageNet中的應用:詳解5種主要的影象識別模型
YJango的卷積神經網路——介紹
ImageNet Classification with Deep Convolutional Neural Networks
AlexNet簡介
CNN簡介
GoogLeNet學習心得
無需數學背景,讀懂ResNet、Inception和Xception三大變革性架構
變形卷積核、可分離卷積?CNN中十大拍案叫絕的操作!
沒看過這5個模型,不要說你玩過CNN!
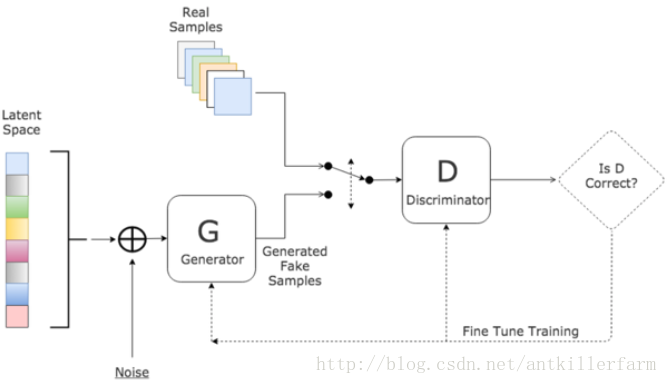
GAN
概況
GAN是“生成對抗網路”(Generative Adversarial Networks)的簡稱,由2014年還在蒙特利爾讀博士的Ian Goodfellow引入深度學習領域。
注:Ian J. Goodfellow,斯坦福大學本碩+蒙特利爾大學博士。導師是Yoshua Bengio。現為Google研究員。
個人主頁:
http://www.iangoodfellow.com/
論文:
《Generative Adversarial Nets》
教程:
通俗解釋
對於GAN來說,最通俗的解釋就是“偽造者-鑑別者”的解釋,如藝術畫的偽造者和鑑別者。一開始偽造者和鑑別者的水平都不高,但是鑑別者還是比較容易鑑別出偽造者偽造出來的藝術畫。但隨著偽造者對偽造技術的學習後,其偽造的藝術畫會讓鑑別者識別錯誤;或者隨著鑑別者對鑑別技術的學習後,能夠很簡單的鑑別出偽造者偽造的藝術畫。這是一個雙方不斷學習技術,以達到最高的偽造和鑑別水平的過程。
從上面的解釋可以看出,GAN實際上一種零和遊戲上的無監督演算法。