
使用scikit-learn訓練可用於iOS上的coreML模型
為什麼不想再用turicreate?
在之前的學習中,主要使用的是python的turicreate框架來生成iOS上的機器學習模型.mlmodel檔案。蘋果從WWDC2017年開始就致力於不斷降低iOS開發者使用機器學習技術的難度,降低開發者們學習機器學習知識的學習成本,因此推出了python上的turicreate框架,可以幾行程式碼之內就可以完成訓練、測試、生成模型,還有用在xcode上的createML,直接用視覺化UI訓練模型。這樣做的好處確實極大減輕了開發者們的學習負擔,但壞處也顯而易見,除了讓人們對機器學習內在知識一無所知,更因為其封裝的很多引數和演算法既定,不能給我們提供很大的選擇空間,故而在很多場景下不能最大化發揮機器學習的演算法優勢,導致效能達不到我們預想的標準。因此,turicreate作為一個很方便的工具,但終究要再學習的過程中被拋棄。
為什麼使用Scikit-learn
sklearn中包含了大量的優質的資料集和大量的演算法選擇,在你學習機器學習的過程中,你可以通過使用這些資料集和演算法實現出不同的模型,從而提高你的動手實踐能力,同時這個過程也可以加深你對理論知識的理解和把握。(另一點是因為再實驗室時學長學姐在發cv論文的時候都是用到了這個,也是不明覺厲。。。。)
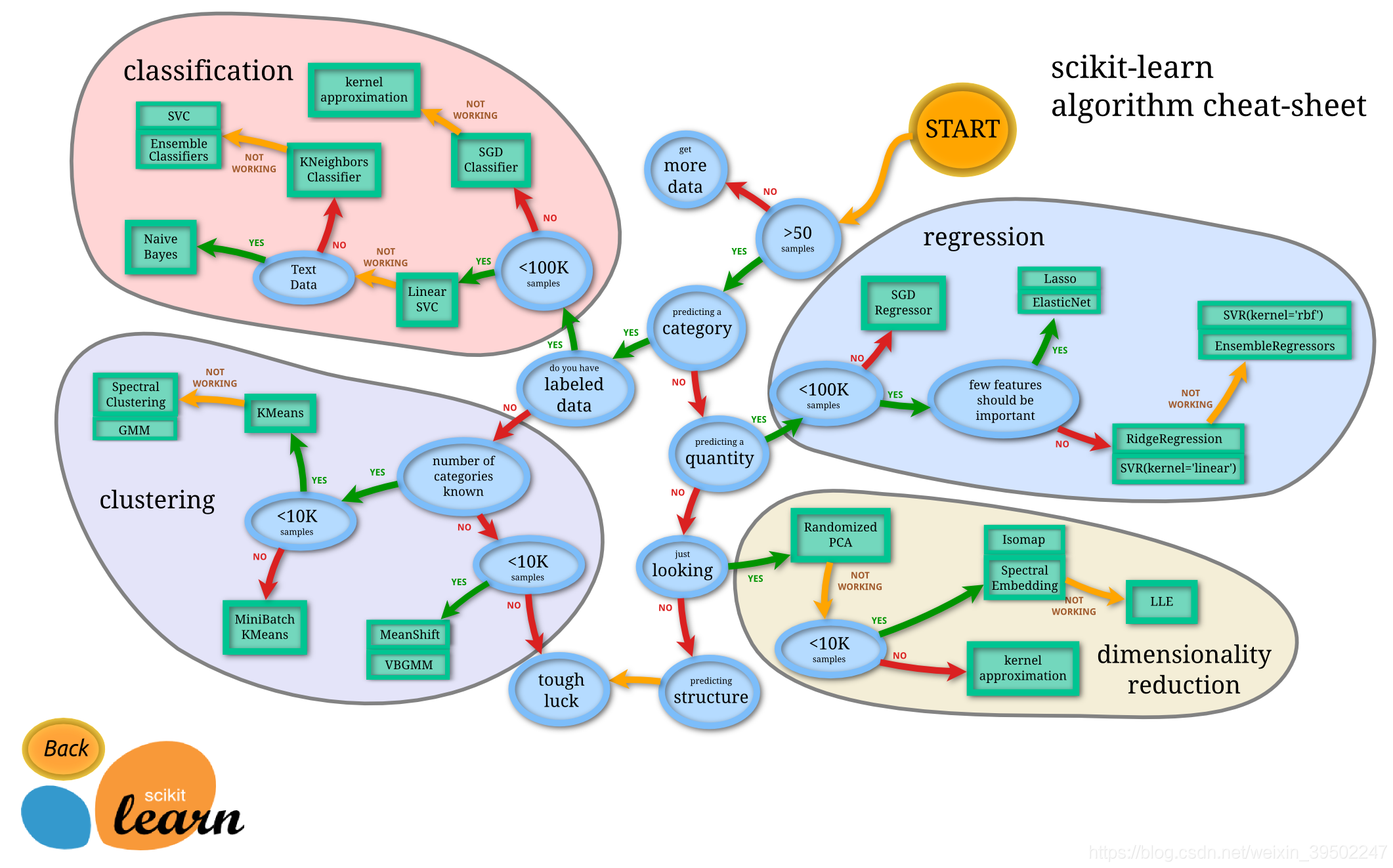
一張圖說明了sklearn裡面有多少種演算法可供選擇,其中箭頭表示的是根據不同需求尋找不同演算法的路線
使用sklearn訓練一個線性迴歸模型
import pandas as pd from sklearn import model_selection from sklearn import linear_model
pandas 是基於NumPy 的一種工具,該工具是為了解決資料分析任務而建立的。
adver = pd.read_csv("Advertising.csv", usecols=[1,2,3,4])
adver.head()Out[5]:
| TV | radio | newspaper | sales | |
|---|---|---|---|---|
| 0 | 230.1 | 37.8 | 69.2 | 22.1 |
| 1 | 44.5 | 39.3 | 45.1 | 10.4 |
| 2 | 17.2 | 45.9 | 69.3 | 9.3 |
| 3 | 151.5 | 41.3 | 58.5 | 18.5 |
| 4 | 180.8 | 10.8 | 58.4 | 12.9 |
x表示前三列的input資料,y表示最後一列的output資料。並對資料集進行分割
x,y = adver.iloc[:, :-1], adver.iloc[:, -1]
x_train, x_test, y_train, y_test = model_selection.train_test_split(x, y, test_size=0.25,random_state=42)
建立一個線性迴歸(linear regression)模型;fit方法表示訓練模型;score對模型進行評價
regr = linear_model.LinearRegression() # 1
regr.fit(x_train, y_train) # 2
regr.score(x_test, y_test) # 3Out[8]: 0.8935163320163657
輸出測試結果
X_new = [[ 50.0, 150.0, 150.0],
[250.0, 50.0, 50.0],
[100.0, 125.0, 125.0]]
regr.predict(X_new)Out[9]: array([34.15367536, 23.83792444, 31.57473763])
使用sklearn訓練一個svm模型
from sklearn import svmsvr = svm.LinearSVR(random_state=42)
svr.fit(x_train, y_train)
svr.score(x_test, y_test)Out[11]: 0.8665383823569167
svr.predict(X_new)Out[12]: array([25.86174666, 21.5094961 , 24.77368402])
匯出coreML的mlmodel檔案
import coremltools
input_features = ["tv", "radio", "newspaper"]
output_feature = "sales"
model = coremltools.converters.sklearn.convert(regr, input_features, output_feature)
# Set model metadata
model.author = 'Xiao Liang'
model.license = 'BSD'
model.short_description = 'Predicts the price of a house in the Beijing area.'
# Set feature descriptions manually
model.input_description['tv'] = 'Ads price spent on tv'
model.input_description['radio'] = 'Ads price spent on radio'
model.input_description['newspaper'] = 'Ads price spent on newspaper'
# Set the output descriptions
model.output_description['sales'] = 'Price of the house'
model.save("MyAdversising.mlmodel")python部分的程式碼到此為止,接下來是在xcode上的使用,核心程式碼就三句:一句傳入輸入,一句定義輸出,一句取出輸出。完成啦。
let input = MyAdvertisingInput(tv: tv, radio: radio, newspaper: newspaper)
guard let output = try? advertising.prediction(input: input) else {
return
}
let sales = output.sales