
使用jsoup十分鐘內掌握爬蟲技術
對,就是十分鐘,沒有接觸過爬蟲的你,肯定一臉懵逼,感覺好高深的樣子,前幾天我就是這樣的,但用了以後發現還是很簡單的,java爬蟲框架有很多,讓我有種選擇困難症,通過權衡比較還是感覺jsoup比較好用些,簡單強大,怎麼簡單強大呢?看了後面你就知道了。
為什麼要給大家講一下使用jsoup呢?一個是為了大家少走彎路,能快速掌握爬蟲技術,不要像我一樣繞了幾個小時在這上面。二是如果我講的不好或是哪裡有不對的地方麻煩大家在評論區指出來,大家一起討論討論,就像我們公司的口號一樣,幫助他人就是成就我自己。記得剛入行的時候,所在的公司是做旅遊方向軟體的,主要工作是開發各縣區的旅遊景區APP,每做一個app我就要上網找資料,錄資料,作為現場競標演示使用。那時候也蠢,只知道上網找資料,然後複製貼上,一個景區的資料少則一天,多則一個禮拜。在那家公司工作的一年時間裡,差不多有三四個月是浪費在無腦錄資料上的,而不是專研在技術上的,現在想想就心痛,如果當時用爬蟲的話,就可以省下一大筆時間了,多的用在技術和泡妞上不知道有多好。所以大家應該知道掌握爬蟲的重要性了吧!
大家是不是有點不耐煩了,在罵我還不進入正題,好好好,現在進入正題,我們以需求的方式去講這次的內容吧!我的需求是這樣的:爬取某網站的深圳寫字樓資料,儲存到我們自己的資料庫,以充實我們的資料量。我們拿點點租為例吧!首先我們進入點點租官網(http://sz.diandianzu.com/listing),如圖所示:
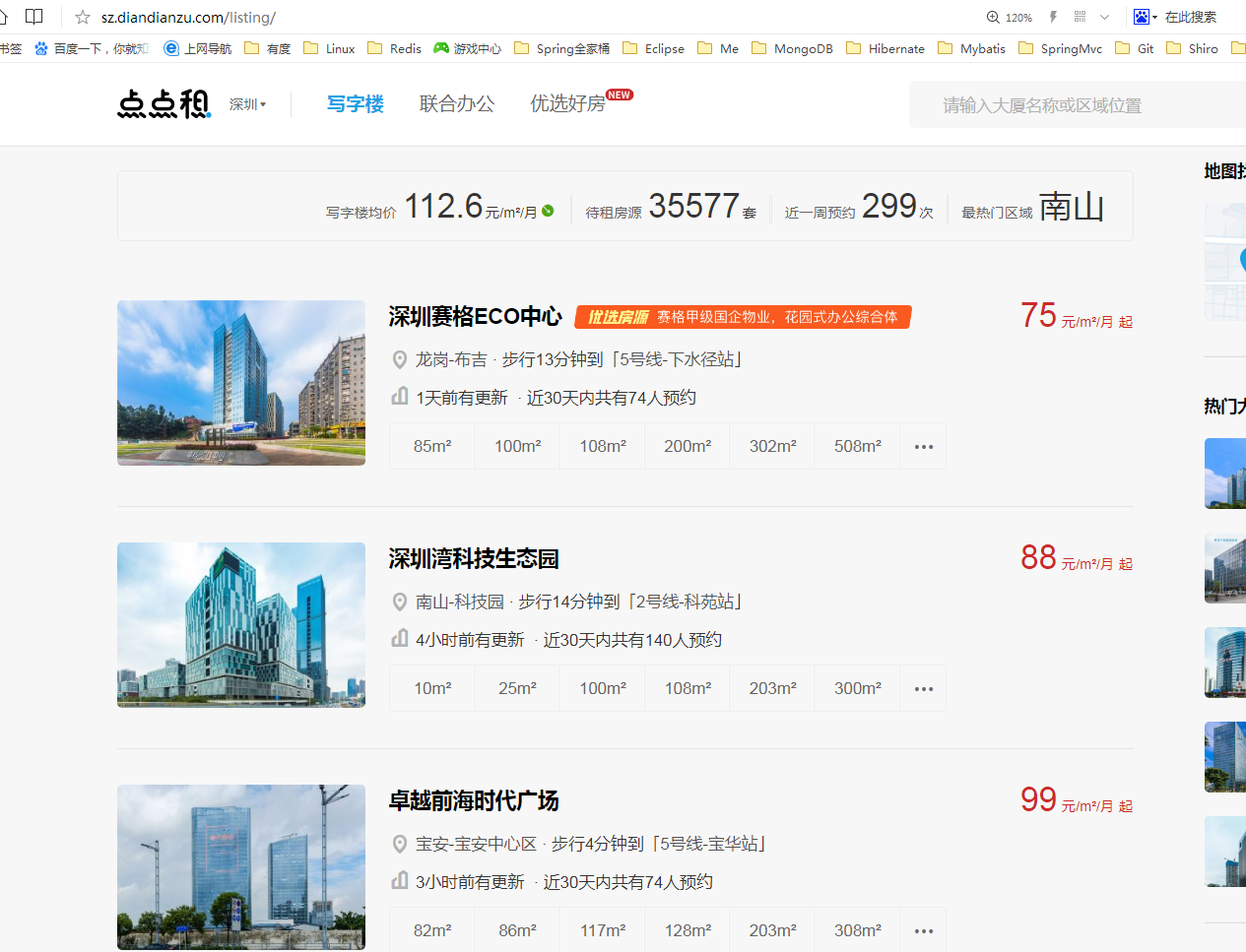
怎麼才能通過jsoup爬取到所有寫字樓資料呢?先劇透一點,通過Document doc = Jsoup.connect(“http://sz.diandianzu.com/listing”).userAgent(agent).ignoreHttpErrors(true).timeout(3000).get()就能獲取當前頁http://sz.diandianzu.com/listing的html原始碼,所以我們是通過原始碼標籤,id選擇器,類選擇器等多種方式去找到我們所要的資料。作為一個java程式設計師,如果你對html一概不知的話,我真想認識認識你,這是程式設計師必備技能。首先我們通過虛擬碼的方式去實現它!爬取資料最主要的一點就是找網站規律,實現程式碼很簡單。我們可以先花三十秒思考一下怎麼才能爬取到所有深圳寫字樓的資料呢?
1.我們要獲取到當前頁的所有樓盤id,2.我們要獲取到所有頁的樓盤id。3通過樓盤id獲取樓盤詳情。你是不是也是這麼想的呢?首先我們通過f12檢視一下原始碼,查詢一下當前頁的樓盤id,如圖所示,我們可以很快查詢到當前頁所有樓盤的id,如圖所示: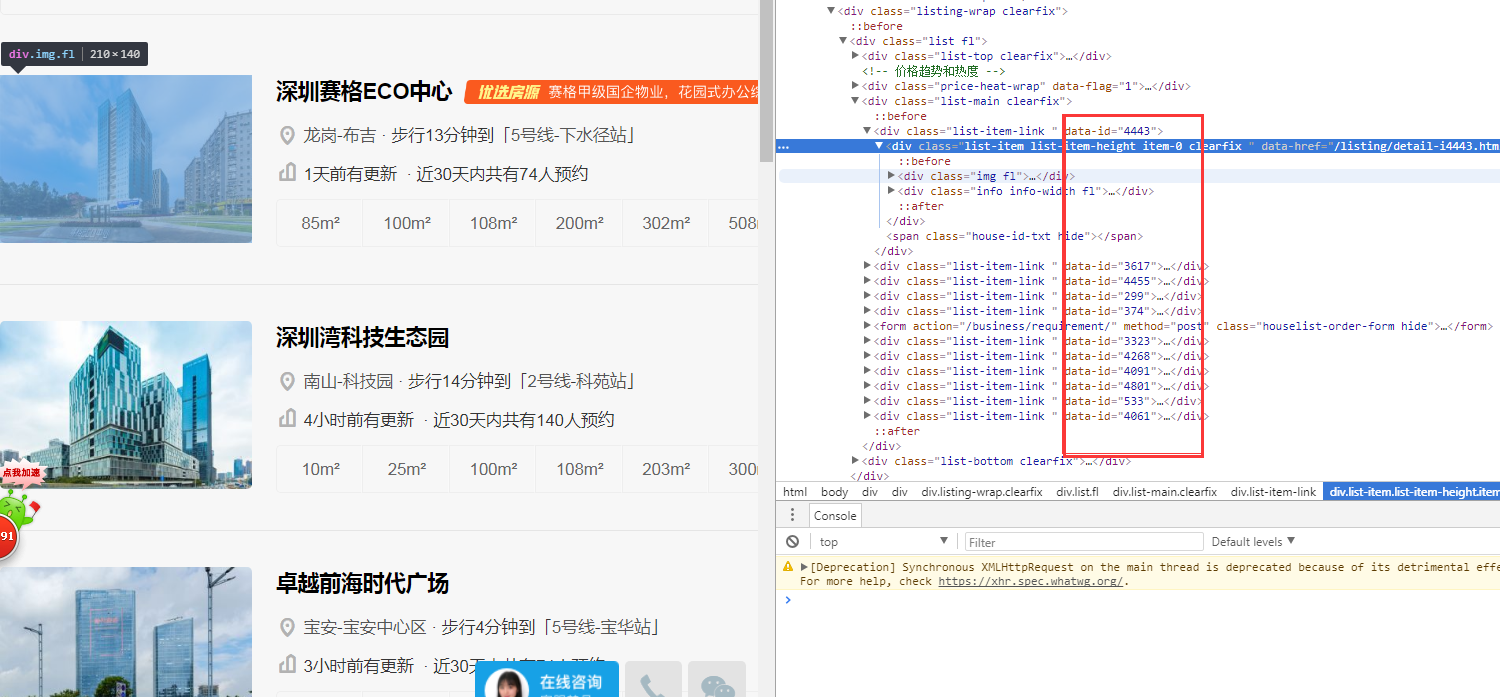
現在我們只是找到了當前頁的所有樓盤id,怎麼才能獲取到所有頁的樓盤id呢?我們先看一下第二頁,如圖所示:

注意看網址:http://sz.diandianzu.com/listing/p2/,你翻到第三頁就是http://sz.diandianzu.com/listing/p3/,以此類推,我們就知道只需要改變p後面的數值就能獲取到第N的資料啦,這在程式碼獲取上很簡單,我們只要在一個迴圈就能讀取到所有頁的資料了,怎麼才知道當前頁是最後一頁資料呢?我們可以通過比較一下有資料和沒有資料的時候頁面原始碼區別就知道了,程式碼部分後面講。獲取所有頁的id規律我們知道了,怎麼通過id獲取當詳情資料呢?我們隨便點開一個樓盤的詳情頁,如圖所示,還是重點看url部分:
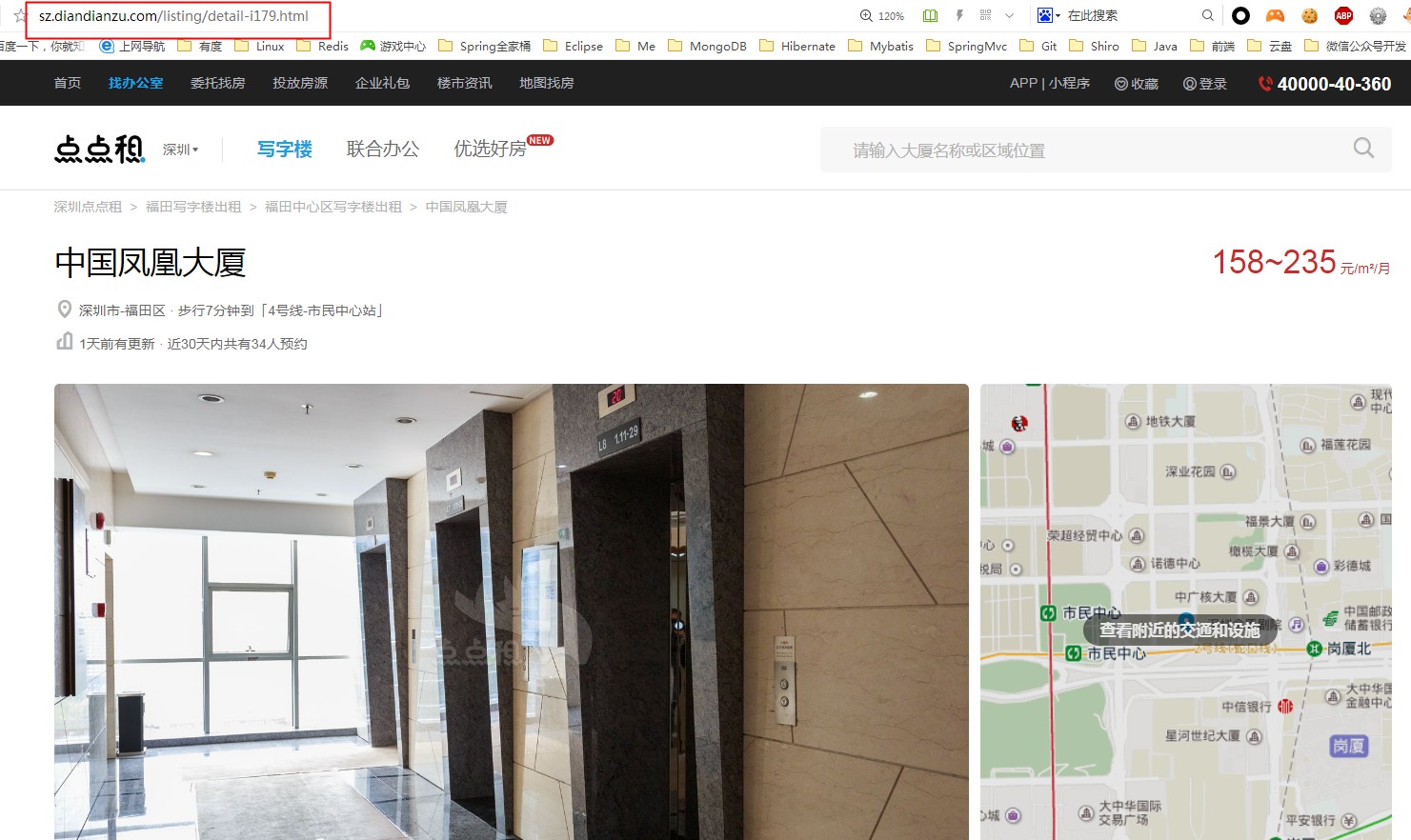
看到http://sz.diandianzu.com/listing/detail-i179.html這個url,我們再隨便開啟一下另外一個專案詳情的url:http://sz.diandianzu.com/listing/detail-i3484.html,發現他們的區別只是i後面的數值不一樣,這個179和3484是什麼呢?你肯定想的到肯定就是我們的樓盤id啦,所以通過迴圈樓盤id列表,然後解析http://sz.diandianzu.com/listing/detail-i{樓盤id}.html的方式就能獲取到所有樓盤詳情啦!
規律是找到了,現在我們開始簡單的程式碼過程吧!在碼程式碼之前,我們可以先看看jsoup的中文文件:http://www.open-open.com/jsoup/dom-navigation.ht,只需要根據文件就能輕易獲取到當前頁任意一段程式碼內容。首先我們從一個URL載入一個Document,如圖所示:

我的程式碼也是這樣的,別忘了先把jsoup 的jar包引入進來:
Document doc = Jsoup.connect("http://sz.diandianzu.com/listing").get();debug以下檢視doc輸出內容拷貝到文字編輯器我們可看到就是當前頁的html原始碼,我們先找到樓盤列表這一塊的div原始碼,如圖所示:
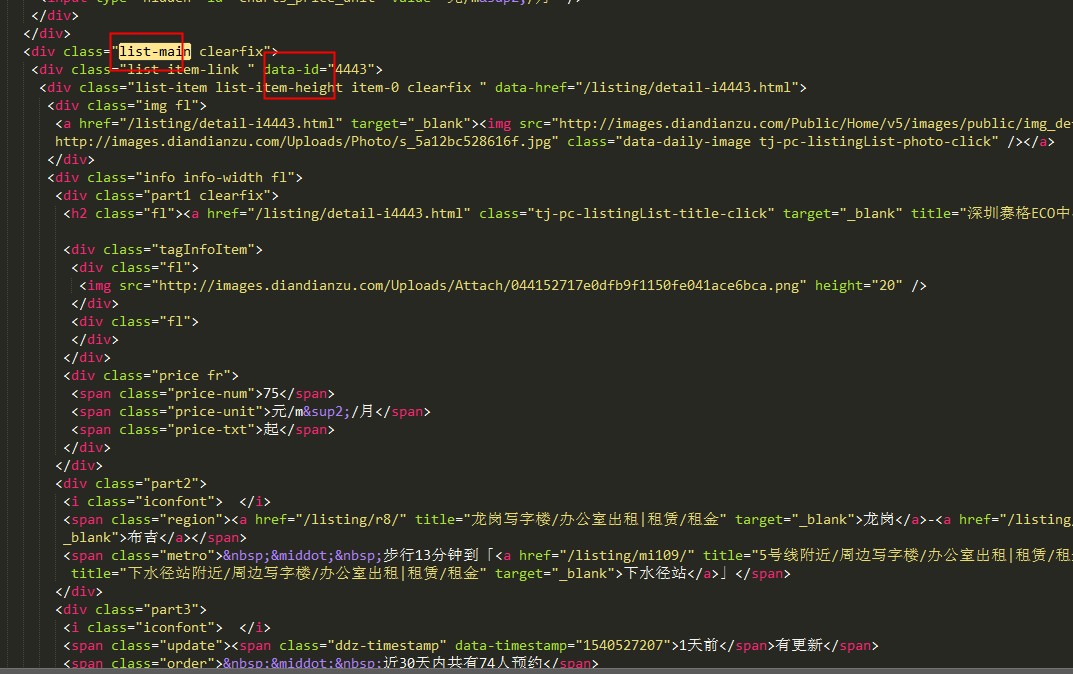
我們的樓盤資料都在class為list-main裡面呢,根據jsoup文件我們通過定位到list-main這個div裡面去,再根據 遍歷div裡面的data-id就能獲取到所有data-id裡面的樓盤id了,程式碼如圖所示:
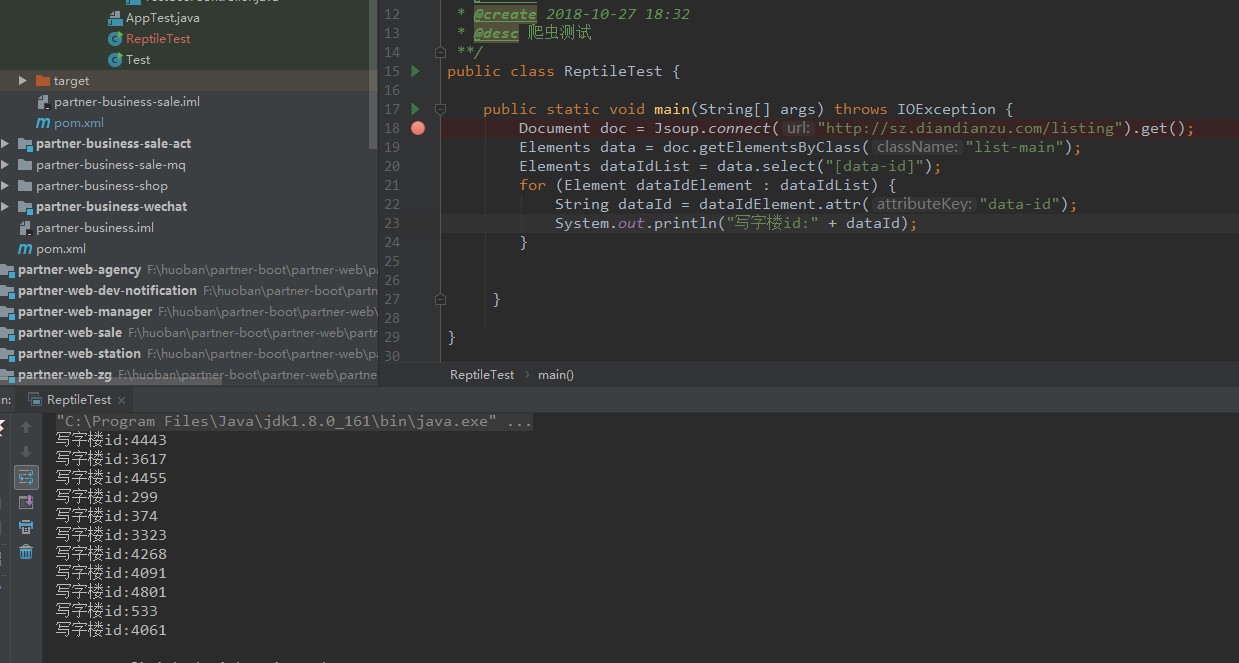
是不是很簡單呢?只需要根據jsoup文件就能很快獲取到我們想要的元素值。怎麼獲取所有頁面的寫字樓id呢?我們改造一下這段程式碼,如圖所示:

是不是很簡單呢?但這裡還有一個問題,是怎麼區分是不是最後一頁,是最後一頁我們就得介紹迴圈,不能會一直查詢下去,我們查詢一下沒有資料的list-main跟有資料的list-main裡面的原始碼區別,在url輸入http://sz.diandianzu.com/listing/p2000/沒有資料了,如圖所示:

好,我們解析一下這個頁面的html原始碼,看一下它的程式碼是怎麼樣的?解析出來後如圖所示:
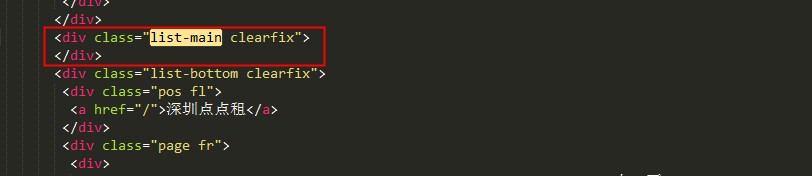
看到沒有,list-main類選擇這個div裡面沒有任何東西,所以我們只需要判斷data-id這個標籤存不存在,就可以知道是不是最後一頁,不存在值就直接退出,完整獲取所有樓盤id的程式碼:
package com.zhaoshang800.boot;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.IOException;import java.util.ArrayList;import java.util.List;/** * @author zhx * @create 2018-10-27 18:32 * @desc 爬蟲測試 **/public class ReptileTest { public static void main(String[] args) throws IOException { try { long startTime = System.currentTimeMillis(); List<String> buildingIdList = new ArrayList<>(); int pageNum = 0; while (1 == 1) { pageNum++; try { System.out.println("當前頁:" + pageNum); String url = "http://sz.diandianzu.com/listing/p"+pageNum; Document doc = Jsoup.connect(url).get(); if(doc == null){ continue; } Elements data = doc.getElementsByClass("list-main"); Elements dataIdList = data.select("[data-id]"); if (null == dataIdList || dataIdList.size() <= 0) { break; } for (Element dataIdElement : dataIdList) { String dataId = dataIdElement.attr("data-id"); System.out.println("寫字樓id:" + dataId); buildingIdList.add(dataId); } } catch (Exception e) { e.printStackTrace(); } } System.out.println("一共有寫字樓"+buildingIdList.size()); long endTime = System.currentTimeMillis(); System.out.println("獲取樓盤id一共用時"+(endTime - startTime)/1000+"秒"); } catch (Exception e) { e.printStackTrace(); } }
把我這段程式碼複製過去直接執行main方法就可以打印出所有的樓盤id了,如圖所示:

是不是很簡單,後面的獲取所有樓盤詳情想必大家應該知道怎麼做了吧?留給大家自己動手去做吧,如果還有疑問的或是有什麼指教的話,可以在評論區聯絡我,我會第一時間一一答覆。