
十分鐘能學會的簡單python爬蟲
阿新 • • 發佈:2019-02-03
簡單爬蟲三步走,So easy~
本文介紹一個使用python實現爬蟲的超簡單方法,精通爬蟲挺難,但學會實現一個能滿足簡單需求的爬蟲,只需10分鐘,往下讀吧~
該方法不能用於帶有反爬機制的頁面,但對於我這樣的非專業爬蟲使用者,幾乎遇到的各種簡單爬蟲需求都是可以搞定的。
歸納起來,只有簡單的3步
- 使用開發人員工具分析網頁HTML
- 請求網頁
- 獲取相應資訊
我們以一個簡單的需求為例:
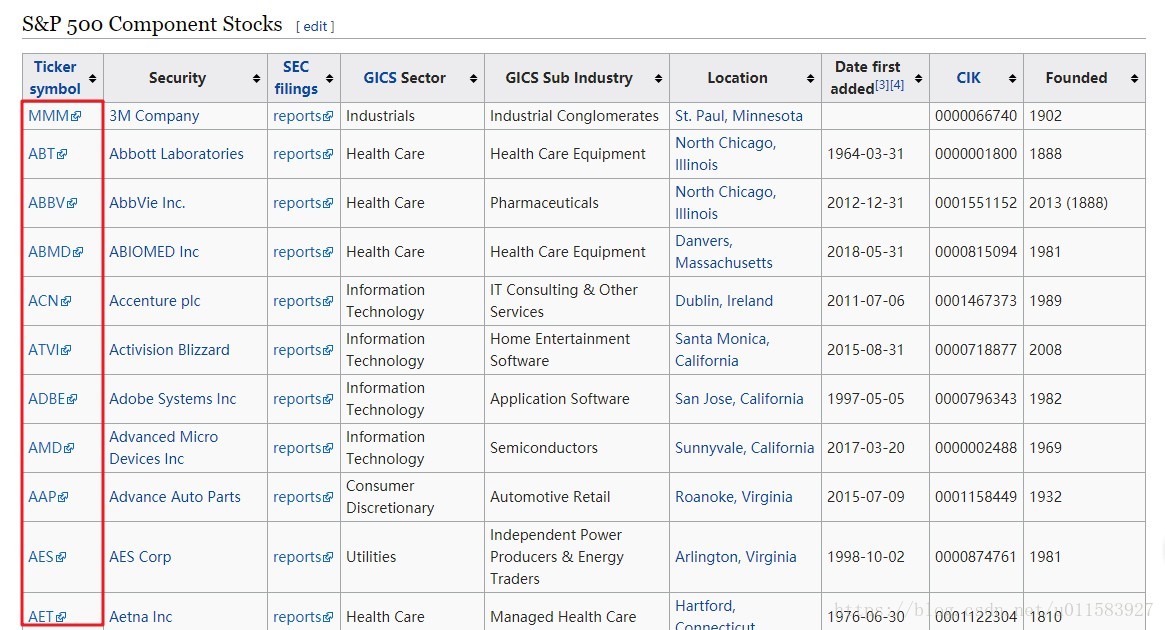
從wiki百科標普500指數頁面中,利用爬蟲自動獲取 S&P 500指數所對應的所有股票。如圖所示:
第一步:使用開發人員工具分析網頁HTML
首先我們要對待爬取的網頁人工的進行結構分析
這裡我使用的是Google瀏覽器
進入頁面後,按下F12
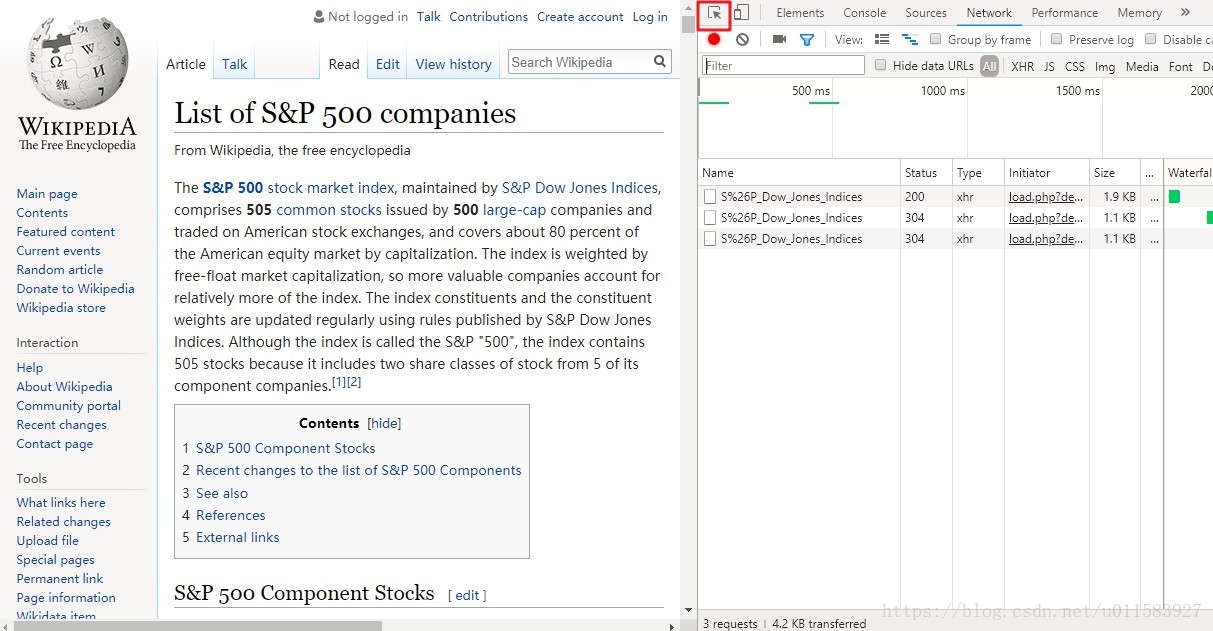
選擇開發人員工具左上角的小箭頭
這是一個對映工具
通過它你可以輕鬆的觀察網頁中每一個渲染後的元素所對應於網頁HTML中的位置
這能夠幫我們很輕鬆的完成html的結構分析,從而快速實現一個爬蟲
就像這樣
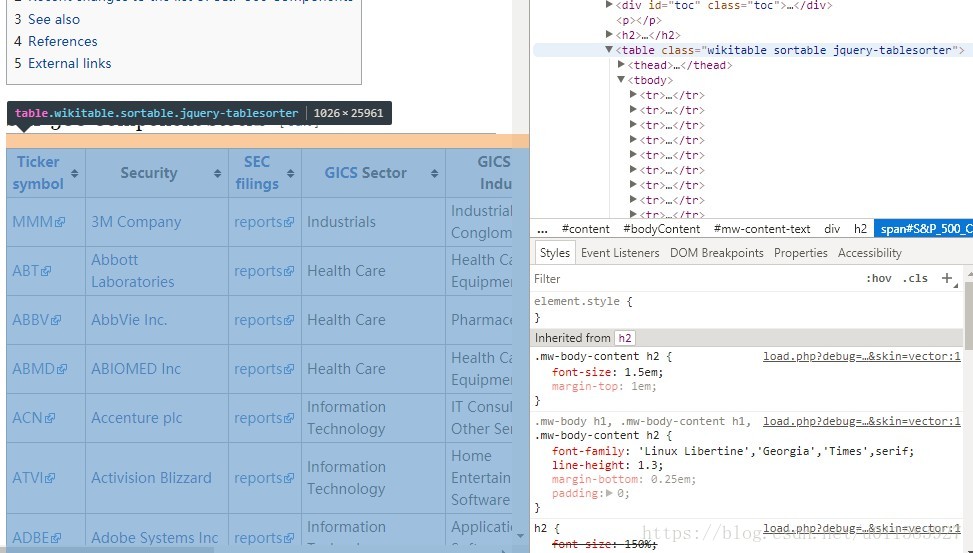
通過觀察,我們發現,所有待爬取的股票資訊都位於一個表格中
這個表格對應於一個
<table class="wikitable sortable jquery-tablesorter"> 標籤 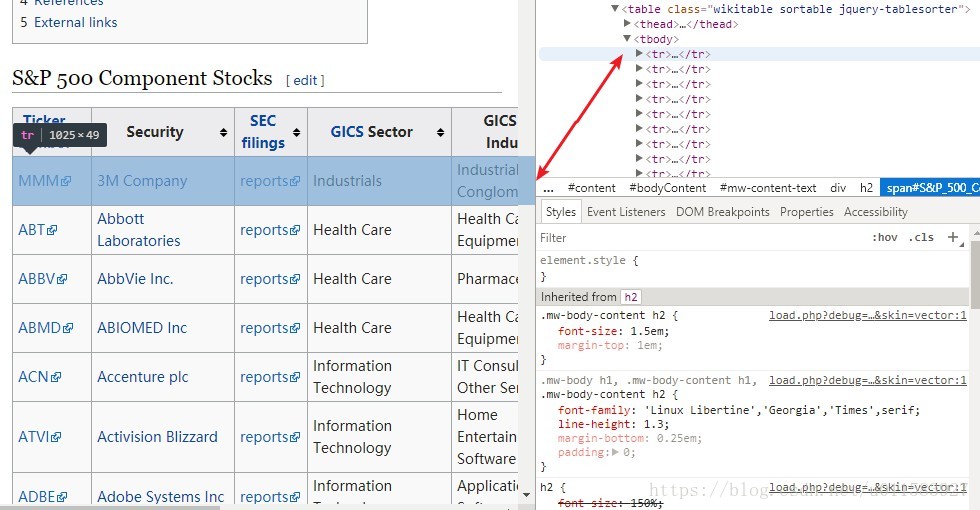
而表格中每一行的的股票資訊又對應了
table 下的一個tr 標籤 因此我們爬蟲的工作就是get到
table 下的所有tr 標籤,並解析出相應內容 第一步網頁HTML分析,完成!
第二步:請求網頁
下面開始進入程式碼階段
這裡我使用的是Python3
需要用到requests 和 BeautifulSoup 這兩個庫
因此別忘記引用:
import bs4
import requests首先我們需要請求網頁:
response = requests.get("http://en.wikipedia.org/wiki/List_of_S%26P_500_companies")隨後使用BeautifulSoup解析
soup = bs4.BeautifulSoup(response.text,"html5lib")沒有錯,就是這麼簡單~
第三步:獲取相應資訊
結合第一步的分析
我們爬蟲的工作就是get到table 下的所有tr 標籤,並解析出相應內容
通過BeautifulSoup庫的一個核心的方法select 我們便能完成這個工作
首先獲取所有的tr 標籤
symbolslist = soup.select('table')[0].select('tr')[1:]然後獲取tr 標籤中所需的屬性並打印出來
symbols = []
for i, symbol in enumerate(symbolslist):
tds = symbol.select('td')
symbols.append(
(
tds[0].select('a')[0].text, # Ticker
tds[1].select('a')[0].text, # Name
tds[3].text, # Sector
)
)大功告成,最終的程式執行結果如下:

全部程式碼如下:
import bs4
import requests
if __name__ == "__main__":
"""
Download and parse the Wikipedia list of S&P500
constituents using requests and BeautifulSoup.
Returns a list of tuples for to add to MySQL.
"""
# Use requests and BeautifulSoup to download the
# list of S&P500 companies and obtain the symbol table
response = requests.get(
"http://en.wikipedia.org/wiki/List_of_S%26P_500_companies"
)
soup = bs4.BeautifulSoup(response.text,"html5lib")
# This selects the first table, using CSS Selector syntax
# and then ignores the header row ([1:])
symbolslist = soup.select('table')[0].select('tr')[1:]
# Obtain the symbol information for each
# row in the S&P500 constituent table
symbols = []
for i, symbol in enumerate(symbolslist):
tds = symbol.select('td')
symbols.append(
(
tds[0].select('a')[0].text, # Ticker
tds[1].select('a')[0].text, # Name
tds[3].text, # Sector
)
)
# show the symbols
showNum =10
for i in range(showNum):
print(symbols[i])