
一個JavaWeb專案開發總結
一個JavaWeb專案開發總結
一、學會如何讀一個JavaWeb專案原始碼
步驟:表結構->web.xml->mvc->db->spring ioc->log->程式碼
-
先了解專案資料庫的表結構,這個方面是最容易忘記的,有時候我們只顧著看每一個方法是怎麼進行的,卻沒有去了解資料庫之間的主外來鍵關聯。其實如果先了解資料庫表結構,再去看一個方法的實現會更加容易。
-
然後需要過一遍web.xml,知道專案中用到了什麼攔截器,監聽器,過濾器,擁有哪些配置檔案。如果是攔截器,一般負責過濾請求,進行AOP等;如果是監聽器,可能是定時任務,初始化任務;配置檔案有如 使用了spring後的讀取mvc相關,db相關,service相關,aop相關的檔案。
-
檢視攔截器,監聽器程式碼,知道攔截了什麼請求,這個類完成了怎樣的工作。有的人就是因為缺少了這一步,自己寫了一個action,配置檔案也沒有寫錯,但是卻怎麼除錯也無法進入這個action,直到別人告訴他,請求被攔截了。
-
接下來,看配置檔案,首先一定是mvc相關的,如springmvc中,要請求哪些請求是靜態資源,使用了哪些view策略,controller註解放在哪個包下等。然後是db相關配置檔案,看使用了什麼資料庫,使用了什麼orm框架,是否開啟了二級快取,使用哪種產品作為二級快取,事務管理的處理,需要掃描的實體類放在什麼位置。最後是spring核心的ioc功能相關的配置檔案,知道介面與具體類的注入大致是怎樣的。當然還有一些如apectj等的配置檔案,也是在這個步驟中完成
-
log相關檔案,日誌的各個級別是如何處理的,在哪些地方使用了log記錄日誌
-
從上面幾點後知道了整個開源專案的整體框架,閱讀每個方法就不再那麼難了。
-
當然如果有專案配套的開發文件也是要閱讀的。
![]()

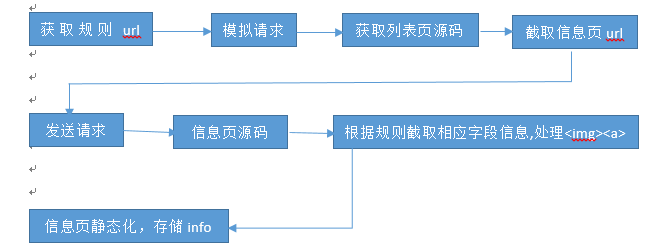
二、爬蟲是如何實現的:
獲取規則url(正則表示式) -> 模擬請求(如httpclient get請求)-> 獲取列表頁html -> 獲取資訊頁 -> 傳送請求 -> 資訊頁html -> 根據規則擷取相應的欄位資訊 -> 對欄位進行清理(如圖片壓縮) -> 靜態化(儲存到資料庫)
三、架構文件
開發專案是需要學會寫架構文件,而不是隻是做一個碼農
包含以下內容:
- 模組分級,各模組關係,各模組負責人
- 各模組時序圖
- 各模組表結構
- 協議文件(介面文件)
- 每個負責人工作計劃
下發任務後每個模組的負責人用開發工具畫出自己的時序圖,表結構和介面文件,最後彙總到總專案負責人處。


四、其它
-
資料庫是否分表問題:用分表的方式管理表有時並不合理,如果讀的壓力高是不值得的,可能更慢。如果寫併發高就行(以千萬級別為準)。 讀是按快取的,快取密度在95%以上是比較保險的。讀的優化:讀單條資訊,只需搜到這個id,然後直接從快取中拿,快取用id做快取,查id的效率是很高的
-
CMS=模板+資料:可以通過只有一套自己的模板(如用freemarker),傳送請求獲取json資料填入資訊。CMS有模板通過把資料填入模板即形成一個網頁。
-
計算機瀏覽器的網頁內容要在手機上檢視,需要做到響應式HTML
-
如通過抓取網頁內容放到app上顯示,需要做的內容:圖片大小自適應,內容儘量保真,校驗內容是否丟失,連結需要替換的需要進行替換,html標籤替換
-
爬蟲的核心是多執行緒的任務管理,抓取分頁列表內容。
-
微信公眾號上是如何繫結使用者讓使用者只登入一次,下次不用登陸?這個過幾天補充。