
TensorFlow中的啟發式Placement演算法模組——Placer
背景
受限於單個Device的計算能力和儲存大小,許多深度學習模型都有著使用模型分片或相關策略的需求。模型分片的本質是將模型和相關的計算切分到不同的Device,這樣做不但可以解決單個Device放不下大模型的問題,還有可能有計算加速的收益。在深度學習框架方面,顯然TensorFlow比Caffe具有更高的靈活性,這主要得益於TensorFlow的Placement機制。Placement是TensorFlow引入的特有概念,它是指某個Op被放在了哪一個Device上,因此模型分片問題實際上就是該模型上每個Op的Placement設定問題。在Python層面,一共存在兩個API與Placement相關的介面,它們不但廣泛存在與框架程式碼中,還可以被使用者拿來直接使用。但是使用者指定Placement資訊存在一定的不可靠性,它與Op的實際情況往往存在一定的矛盾,而TensorFlow中的Placer就是解決這個問題的模組。
Placer功能描述
首先看一下NodeDef的結構,有兩個地方和Placement相關。一個是device屬性,它顯示指定了這個Node應該被放在何種Device上,另一個是字串標記loc:@xxxx,這是placement的約束條件,隱式指明該Node的Placement應該和哪些Node保持一致。準確地說,該Node應該和組名為xxxx內的所有Node的Placement保持一致,這兩個資訊有時候會出現矛盾的情形。
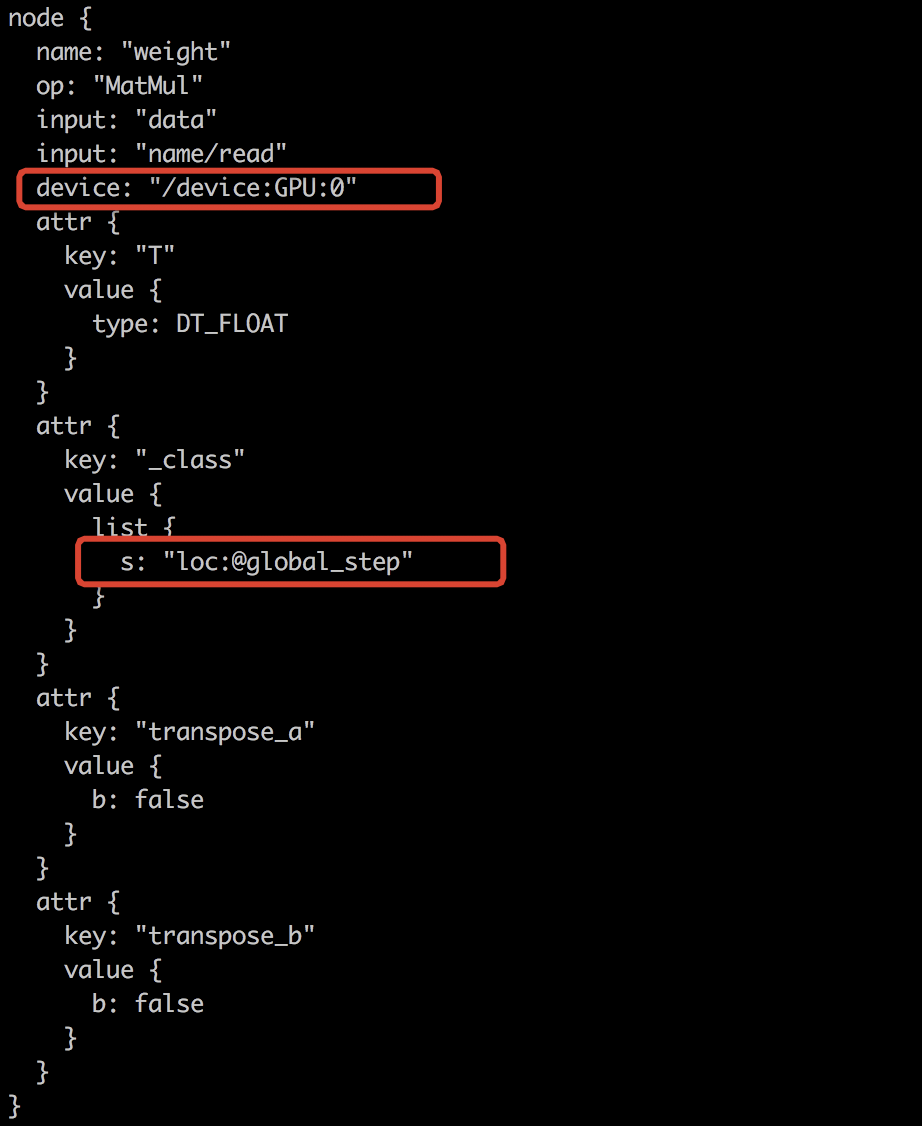
Placer不但要處理二者的矛盾,還要通過一些規則儘可能避免因Placement不當帶來的效能問題。每個Node在經過Placer處理後都會得到最終的Placement資訊,它將重新覆蓋NodeDef中的device屬性內容。所以,通俗地講,Placer的功能就是計算並填入所有NodeDef的device屬性
前驅內容
閱讀程式碼時難免會碰到一些為解決這個問題專門設立的名詞和經典的演算法,所以建議在閱讀Placer模組相關內容之前先確認已經弄清楚下面的東西,避免走一些彎路。
重要概念
Placement:每個Op的屬性資訊,它顯式地指明瞭某個Op應該被放置在哪一個Device上計算
Colocation Group:這也是每個Op的Placement相關的屬性資訊,從NodeDef上看就是字串為loc:@xxxx字樣的內容。它是若干Node的集合,在演算法中又被稱為約束(Constraint)條件。屬於同一個Colocation Group中的所有Node被約束為必須要具有相同的Placement資訊。這是Placement資訊的隱式表達,它和Placement可以同時被指定,因此存在矛盾的情況。如果發生衝突,則直接報錯
相關演算法
Find-Union演算法:並查集演算法,TensorFlow通過FInd-Union演算法高效地處理了Node的Colocation問題。這裡只講一下概述,具體請參考這篇部落格。“並”和“查”是兩個問題,“並”指的是多個具有屬性的Element合併到某個Group,並對Group的屬性做修改的過程。“查”指的是查詢某個Element所在的Group的屬性過程。當發生“並”時,由於新元素的新增,勢必會引起Group屬性的修改,如何設計較好的資料結構高效的解決這兩個問題是並查集演算法的核心。
Placer決策基本原則
Placer會根據會對Graph進行一定程度的分析,並結合使用者的要求對每個Node的Placement進行微調,微調的原則可以概括為下面四點
1. 儘可能滿足使用者要求(User Requirement First):每個Node的placement會盡量滿足使用者的要求
2. 儘可能使用計算更快的裝置 (High Performance Device):若某個Node的Placement沒有被使用者指定,則優先分配計算更快的裝置
3. 保證程式可執行(Runable):若某個Node不存在使用者要求的Placement相關實現版本,會退而求其次選擇其它實現版本,保障程式可以用
4. 儘可能考慮近鄰特性(Near When Possible):在做Placement的微調時考慮節點的近鄰特性,儘可能減少無意義的拷貝
儘可能滿足使用者要求(User Requirement First)
使用者要求分為兩種,一種是顯示指定,表現為在Node中設定的device資訊;另一種是隱式指定,表現為loc:@xxxx屬性,即Colocation Group。Placer會根據使用者這兩方面的要求並結合實際情況做Placement資訊補全和微調。文章開頭的截圖展示了某個Node的NodeDef資訊,它表明型別為MatMul的Op被使用者顯示指定放到'/device:GPU:0'上,同時希望放入名為global_step的Colocation Group中。NodeDef中的device屬性和loc:@xxxx屬性分別由下面兩個python級別的API引入,它們都由使用者來控制,有些被用在高層API內部封裝中。
# device attributes @tf_export("device") def device(device_name_or_function): # colocation attributes @tf_export("colocate_with") def colocate_with(op, ignore_existing=False):
儘可能使用更快的計算裝置(High Performance Device)
如果某個Node的device屬性中不含device_type(即GPU或CPU),那麼Placer必須決定使用何種Device。每種Device註冊到TensorFlow中時都帶有優先順序,通常高優先順序的Device具有更好的計算效能。當某個Op具有多種Device實現時,Placer將選取優先順序最高的Device實現版本,通過設定device_type為所有實現版本中最高優先順序的Device來實現這種選取。
保證程式可以被執行(Runable)
這是通過Soft Placement機制保證的。如果某個Node被顯示指定精確放在某Device上,但系統中卻沒有該Device上的實現版本,那麼為了保證程式可用,Soft Placement將發揮作用。它將忽略device type,在系統中按照Device優先順序選取另一個可用的實現版本重新改寫Placement。舉例而言,假設某Node的op是SparseToDense,device_type被指定為GPU,但目前SparseToDense在TensorFlow中只有CPU的實現,那麼Soft Placement將改寫該Node的device_type為CPU。
儘可能考慮近鄰特性(Near When Possible)
在Placer中使用以下三種啟發式規則來實現這一原則。
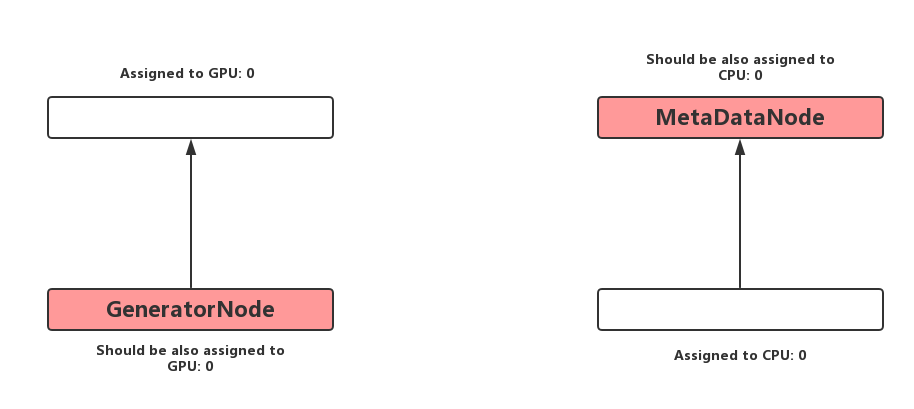
a. 若某個Node是GeneratorNode(0-indegree,1-outdegree,且輸出非reference type),將其與Consumer具有相同的Placement可以防止無意義的跨Device拷貝。這一步在演算法中被稱之為啟發式規則A。
b. 若某個Node是MetaDataNode(直接在Tensor的元資料MetaData上操作,比如Reshape),將其與Producer具有相同的Placemen可以防止無意義的跨Device拷貝。這一步在演算法中被稱為啟發式規則B。
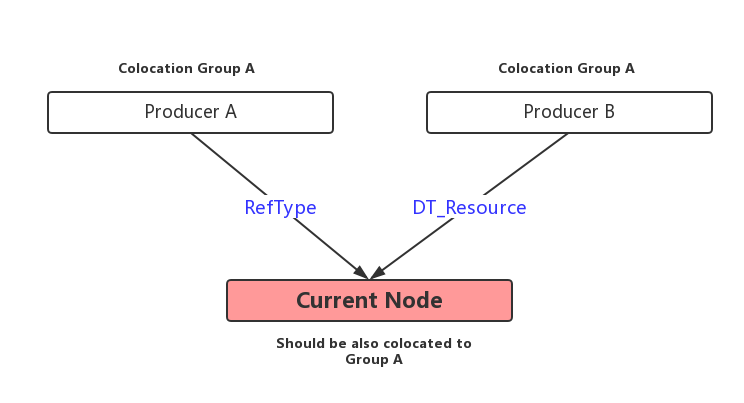
c. 若某個Node的輸入是Reference type或者是Reource type,那麼儘量將其與輸入放在同一個Colocation Group中。演算法中沒有為這個步驟起名字,為了方便我們稱之為啟發式規則C。
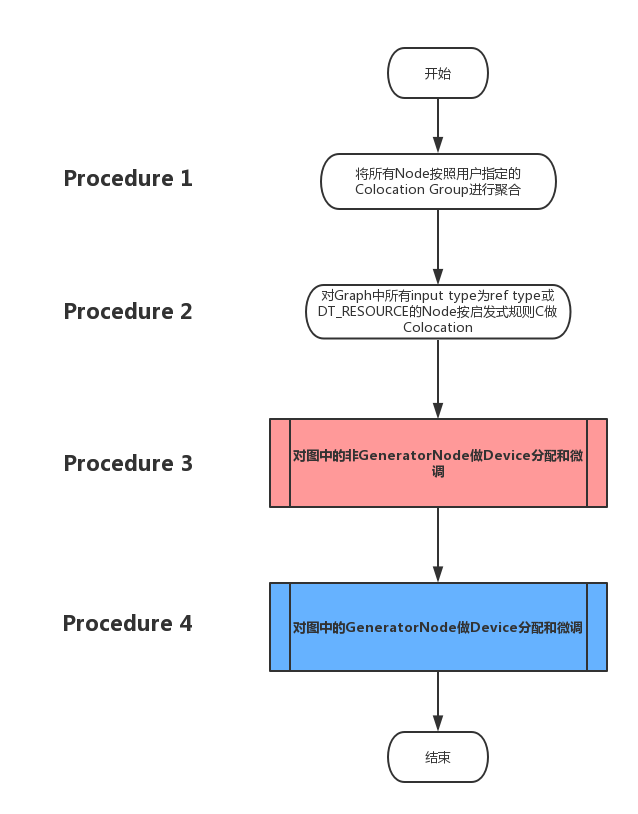
Placer決策演算法總體流程
總體流程分為四個步驟,下圖展示了巨集觀層面的流程圖。其中最後兩個步驟相對較為複雜,下一小節中將會細化其流程圖。
Placer演算法決策分步詳解與關鍵程式碼對照
第一步——根據使用者指定做Colocation Group
一般情況下,沒有被使用者指定Colocation Group資訊的Node會被單獨放入一個Group中作為唯一的成員,並以該Node的Name作為Group的名字,所以Graph中每個Node都會有自己的Colocation Group。從邏輯上來說,合併多個Group是非常簡單的問題,但是這個場景中的Group不僅是Node的集合,還包含若干屬性,比如某個Group的possible device表示這個Group可用的所有Device集合。因此我們需要一種資料結構和演算法,幫助我們在合併兩個Group時很方便地生成新Group及相關屬性(方便Union),並且能夠根據某個Node快速檢視所屬Group的所有屬性(快速Find),這就是Find-Union的優勢所在。Find-Union演算法原理將不在這裡描述,這裡只給出程式碼中Find-Union用到的基本資料結構——Member,它用來描述Group的基本資訊。在閱讀下段程式碼註釋前,需要對Find-Union中的樹形結構含義有基本的理解。
1 // Represents a node in the disjoint node set forest, and the 2 // accumulated constraints on the device used by that node. 3 struct Member { 4 Member() = default; 5 // The id of the node that is the parent of this one, or its own 6 // id if it is a root. parent <= 0 indicates that this member is invalid. 7 int parent = -1; 8 9 // A proxy for the depth of the tree that is used to prefer 10 // connecting smaller trees to larger trees when merging disjoint 11 // sets. 12 int rank = 0; 13 14 // The intersection of all device types supported by this node, 15 // and those of all of its children, in priority order 16 // of the preferred device. 17 DeviceTypeVector supported_device_types; 18 19 // The merged form of the device requested for this node, with 20 // those of all of its children. 21 DeviceNameUtils::ParsedName device_name; 22 23 // If this node is a root, stores a list of Devices to which this node 24 // and all of its children have been assigned, or nullptr if this 25 // has not yet been computed. 26 std::vector<Device*> possible_devices; 27 };
下面的程式碼是處理這一步驟的核心程式碼。首先建立ColocationGraph物件,這是一個處理Colocation Group的工具類,裡面使用了Find-Union演算法對Group進行聚合。在呼叫InitiailizeMembers對Find-Union演算法的基本資料結構進行初始化之後,就直接呼叫ColocationAllNodes根據使用者指定的所有colocation資訊進行聚合。
1 ColocationGraph colocation_graph( 2 graph_, devices_, 3 options_ == nullptr || options_->config.allow_soft_placement(), 4 default_device_); 5 6 TF_RETURN_IF_ERROR(colocation_graph.InitializeMembers()); 7 8 // 1. First add all of the nodes. Note that steps (1) and (2) 9 // requires two passes over the nodes because the graph (and hence 10 // the constraints) may not be acyclic. 11 TF_RETURN_IF_ERROR(colocation_graph.ColocateAllNodes());
第二步——啟發式規則C的運用
這一步將對Colocation Group進行調整。在遍歷Graph的每個Node時,需要根據Node input來決定是否將該Node所在的Group與Source Node所在的Group合併。如果Node的input是ref_type或者DT_RESOURCE(關於DT_RESOURCE一般會在使用ResourceVariable時才會碰到。ResourceVariable與Variable相比具有很多新特性,這些特性是TF2.0中主推的內容。關於它的優勢我們不在這裡展開,只對其Op的型別做一個說明。Variable在C++層面的Op型別是VariableV2,而ResourceVariable在C++層面的Op型別為VarHandleOp。後者產生的Tensor就是一種DT_RESOURCE),那麼就嘗試做合併。在合併之前需要做必要的可行性檢查,適當地主動報錯。比如在合併時除了要考慮這一對節點的連線以外,還需要考慮這個Node的其他輸入是否屬於ref_type或者DT_RESOURCE。這一部分的程式碼比較長,但相對比較簡單,這裡不再展示。
第三步——啟發式規則B的運用
從這一步開始,Placer才開始真正的為每個Node分配Device,下面的流程圖中展示了這一步驟。
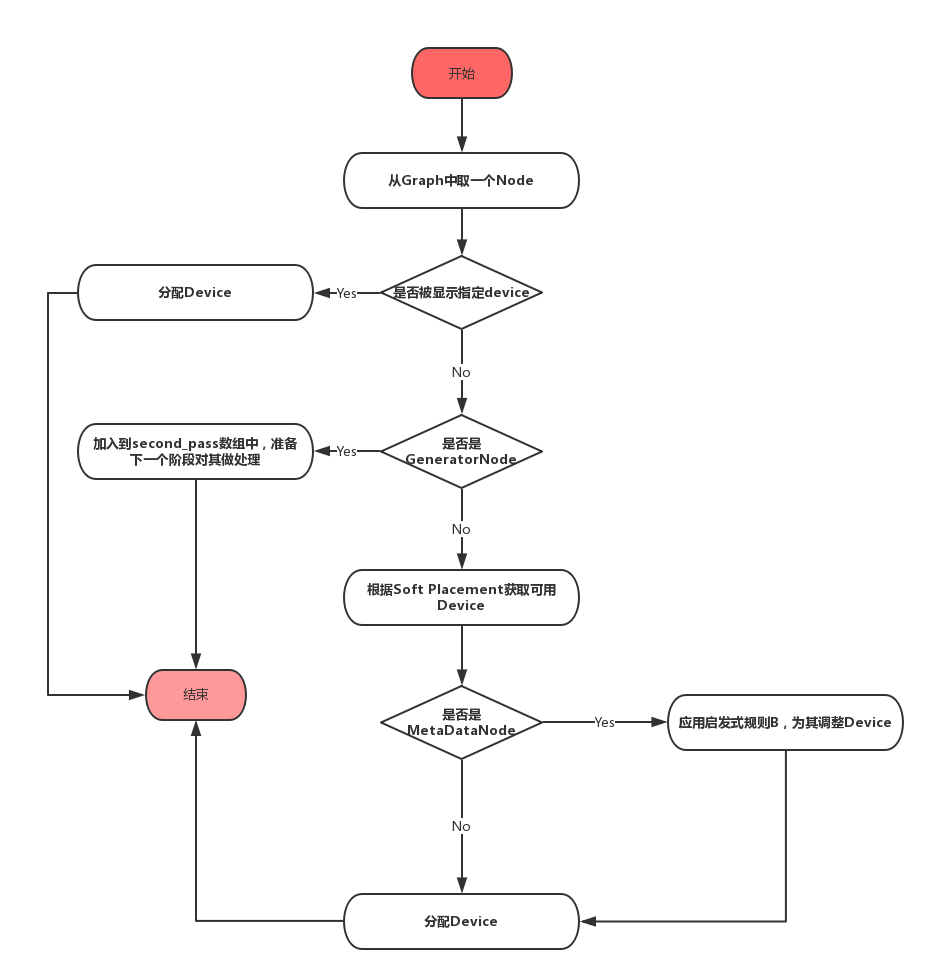
1. 如果當前的Node的device屬性中已經有值,那麼Placer將不再對其做重複的assign操作,直接跳過這個Node。
2. 如果當前Node是GeneratorNode,先將其放入一個名為second_pass的vector中。
3. 如果不是以上兩種情況,那麼該Node正是這一步驟需要處理的物件。先從該Node所在的Colocation Group中獲取可用的Devices(獲取會受到Soft Placement的影響)作為候選。如果該node是MetaData node,那麼會嘗試應用啟發式規則B,否則,將分配候選集中優先順序最高的Device。
下面的程式碼展示了對MetaDataNode的處理邏輯,這就是啟發式規則B的程式碼。
1 int assigned_device = -1; 2 3 // Heuristic B: If the node only operates on metadata, not data, 4 // then it is desirable to place that metadata node with its 5 // input. 6 if (IsMetadata(node)) { 7 // Make sure that the input device type is in the list of supported 8 // device types for this node. 9 const Node* input = (*node->in_edges().begin())->src(); 10 // TODO(vrv): if the input is empty, consider postponing this 11 // node's assignment to the second pass, so that we handle the 12 // case where a metadata node's input comes from a backedge 13 // of a loop. 14 if (CanAssignToDevice(input->assigned_device_name(), *devices)) { 15 assigned_device = input->assigned_device_name_index(); 16 } 17 } 18 19 // Provide the default, if necessary. 20 if (assigned_device == -1) { 21 assigned_device = graph_->InternDeviceName((*devices)[0]->name()); 22 } 23 24 AssignAndLog(assigned_device, node);
第四步——啟發式規則A的運用
這一步將對second_pass陣列中的所有的Node分配Device,下面的流程圖中展示了這一步驟。
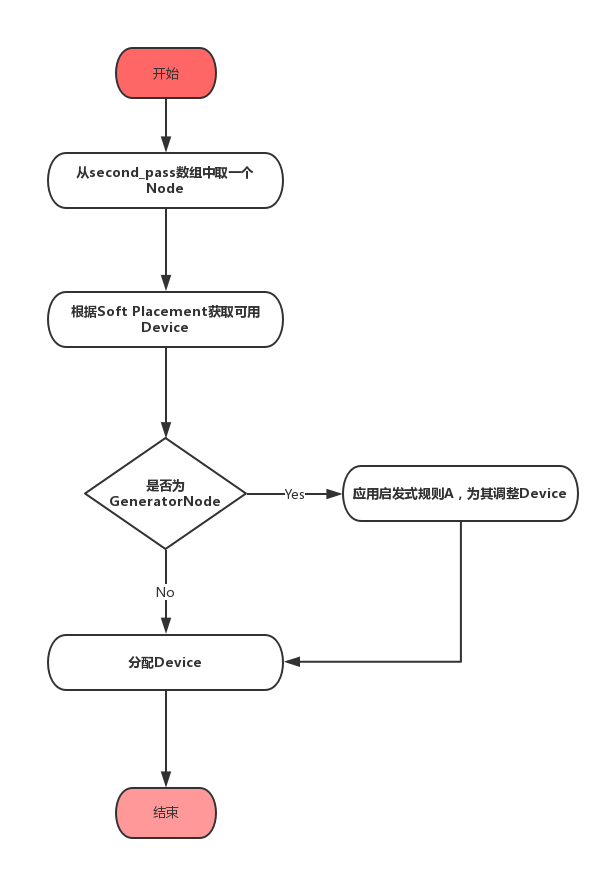
放在second_pass中的程式碼全部是GeneratorNode,所以只需要應用啟發式規則A即可,和步驟3一樣,啟發式規則A的應用也是嘗試性的,如果實在不能滿足,會直接分配候選Device中優先順序最高的Device,下面是啟發式規則A的應用部分程式碼。
1 int assigned_device = -1; 2 3 // Heuristic A application. 4 if (IsGeneratorNode(node)) { 5 const Node* output = (*node->out_edges().begin())->dst(); 6 int output_device_name = output->assigned_device_name_index(); 7 8 const bool consumers_on_same_device = std::all_of( 9 node->out_edges().begin(), node->out_edges().end(), 10 [output_device_name](const Edge* e) { 11 return e->dst()->assigned_device_name_index() == output_device_name; 12 }); 13 14 if (consumers_on_same_device && 15 CanAssignToDevice(output->assigned_device_name(), *devices)) { 16 assigned_device = output_device_name; 17 } 18 } 19 20 // Provide the default, if necessary. 21 if (assigned_device == -1) { 22 assigned_device = graph_->InternDeviceName((*devices)[0]->name()); 23 } 24 25 AssignAndLog(assigned_device, node);
至此,所有Node的Placement資訊都已經分配並微調完畢。
總結
經過Placer處理的GraphDef保證了計算圖在Placement層面已經不存在任何衝突,因此它被認為是解決Placement衝突的最後一道防線。在Placer之後,GraphDef將被送入GraphPartitioner模組中根據每個Node的device做子圖切分,並插入Send,Recv以及必要的ControlFlow節點。從上面的梳理中我們也可以看出Placer模組的核心是應用多種啟發式規則對Placement進行微調,但這些啟發式規則還相對較為簡單,並沒有完全解決效能問題。如果在Placement方面去挖掘效能方面的優化空間,我們馬上可以想到,在分散式模式下,粗糙的Placement方案會讓作業效能變得非常差,因為它會引入計算之外的通訊開銷。TensorFlow為了高度靈活性,將Placement策略的負擔丟給了使用者,這也是為什麼有些使用者寫出的TensorFlow分散式程式效能非常差的原因之一。從TensorFlow框架的功能角度來說,它應該能夠解放使用者的編寫程式負擔,讓使用者能夠完全專注在模型演算法層面的研究中。但是自動搜尋Placement最佳策略的難度非常大,因為它要考慮叢集通訊的頻寬,以及每個Op的計算量,是一個與硬體和環境高度聯絡的複雜問題。不僅如此,通常深度學習模型含有成千上萬個Node,這使得方案的搜尋空間巨大無比。對於這個問題,Google曾經提出過強化學習搜尋最佳模型分片策略的方法,有興趣地同學可以參考這篇ICML論文: Device Placement Optimization with Reinforcement Learning。