
Spring Cloud Sleuth 分散式跟蹤解決方案
Spring Cloud Sleuth
Adrian Cole,Spencer Gibb,Marcin Grzejszczak,Dave Syer
Dalston.RELEASE
Spring Cloud Sleuth為Spring Cloud實現分散式跟蹤解決方案。
術語
Spring Cloud Sleuth借用了Dapper的術語。
Span:工作的基本單位 例如,傳送RPC是一個新的跨度,以及向RPC傳送響應。Span由跨度的唯一64位ID標識,跨度是其中一部分的跟蹤的另一個64位ID。跨度還具有其他資料,例如描述,時間戳記事件,鍵值註釋(標籤),導致它們的跨度的ID以及程序ID(通常是IP地址)。
跨距開始和停止,他們跟蹤他們的時間資訊。建立跨度後,必須在將來的某個時刻停止。
| 提示 | 啟動跟蹤的初始範圍稱為root span。該跨度的跨度id的值等於跟蹤ID。 |
|---|
跟蹤:一組spans形成樹狀結構。例如,如果您正在執行分散式大資料儲存,則可能會由put請求形成跟蹤。
註釋: 用於及時記錄事件的存在。用於定義請求的開始和停止的一些核心註釋是:
-
cs - 客戶端傳送 - 客戶端已經發出請求。此註釋描繪了跨度的開始。
-
sr - 伺服器接收 - 伺服器端得到請求,並將開始處理它。如果從此時間戳中減去cs時間戳,則會收到網路延遲。
-
ss - 伺服器傳送 - 在完成請求處理後(響應傳送回客戶端時)註釋。如果從此時間戳中減去sr時間戳,則會收到伺服器端處理請求所需的時間。
-
cr - 客戶端接收 - 表示跨度的結束。客戶端已成功接收到伺服器端的響應。如果從此時間戳中減去cs時間戳,則會收到客戶端從伺服器接收響應所需的整個時間。
視覺化Span和Trace將與Zipkin註釋一起檢視系統:
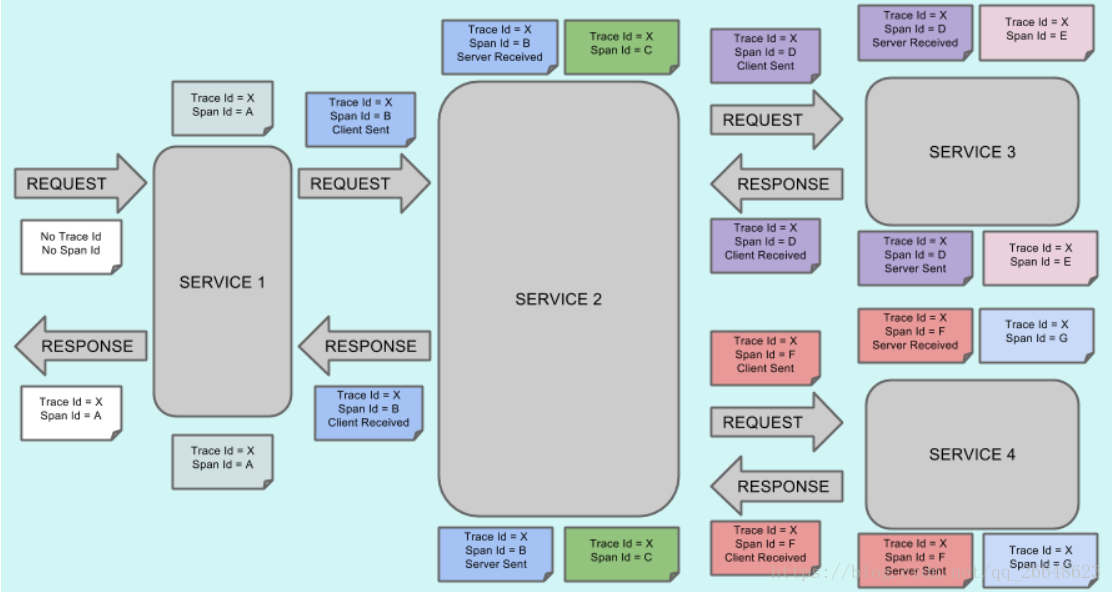
Trace Id = X
Span Id = D
Client Sent
這意味著,當前的跨度痕量-ID設定為X,Span -編號設定為e。它也發出了 客戶端傳送的事件。
這樣,spans的父/子關係的視覺化將如下所示:
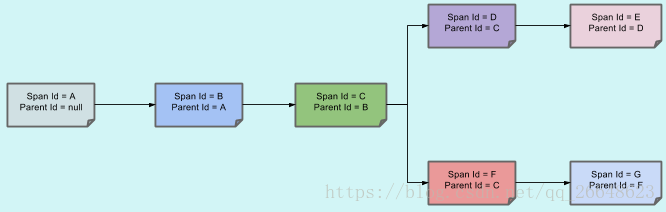
目的
在以下部分中,將考慮上述影象中的示例。
分散式跟蹤與Zipkin
共有7個spans。如果您在Zipkin中檢視痕跡,您將在第二個曲目中看到這個數字:
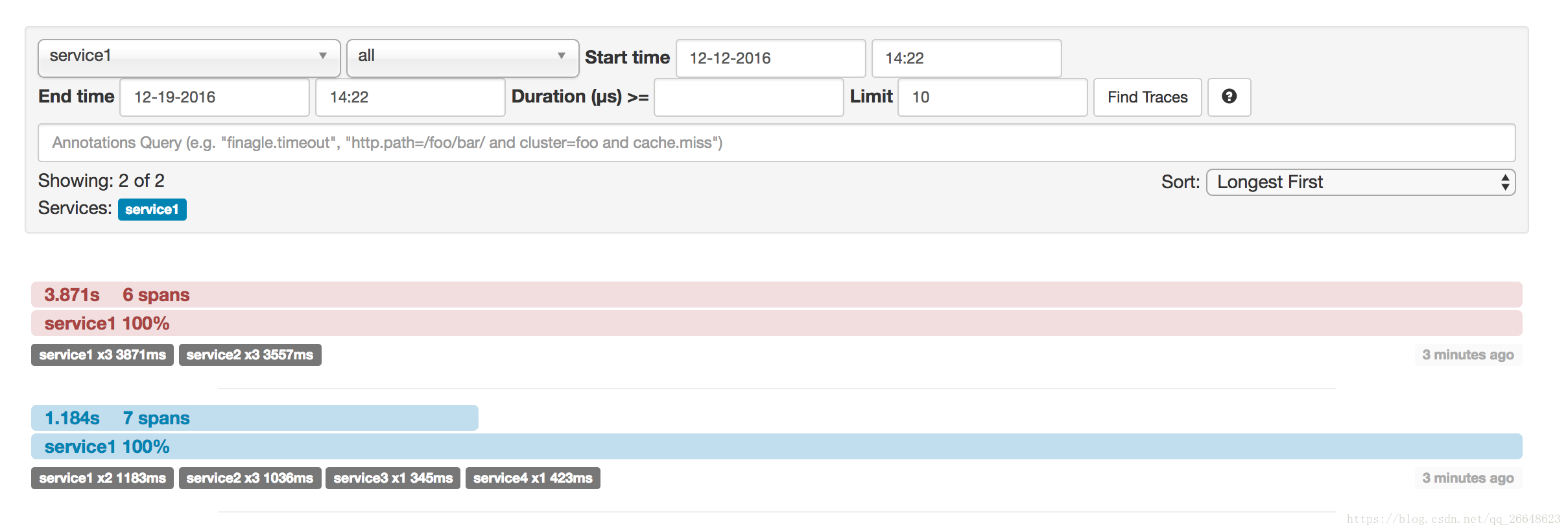
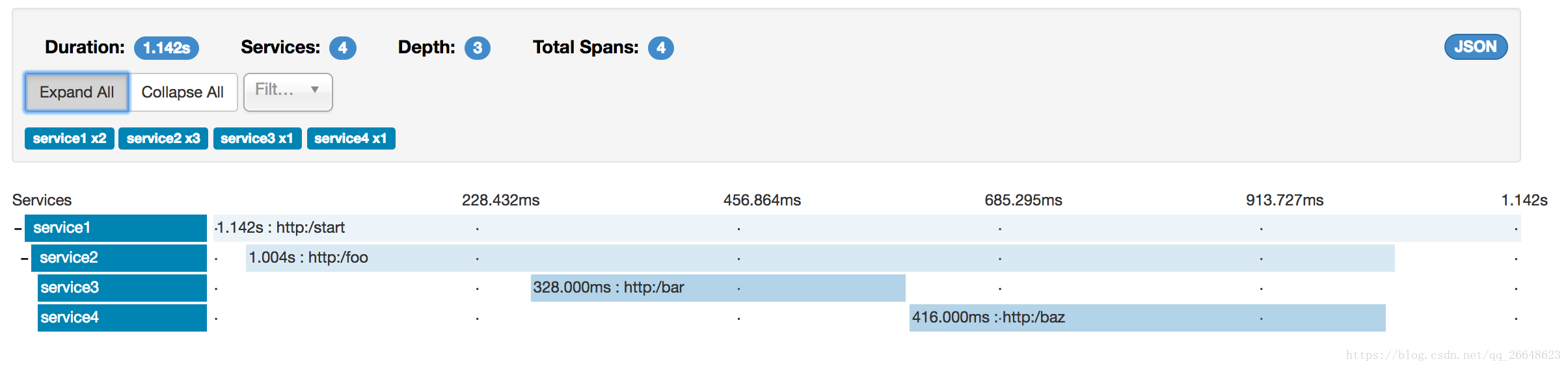
| 注意 | 當選擇特定的跟蹤時,您將看到合併的spans。這意味著如果傳送到伺服器接收和伺服器傳送/接收客戶端和客戶端傳送註釋的Zipkin有2個spans,那麼它們將被顯示為一個跨度。 |
|---|
為什麼在這種情況下,7和4 spans之間有區別?
-
2 spans來自http:/start範圍。它具有伺服器接收(SR)和伺服器傳送(SS)註釋。
-
2 spans來自service1到service2到http:/foo端點的RPC呼叫。它在service1方面具有客戶端傳送(CS)和客戶端接收(CR)註釋。它還在service2方面具有伺服器接收(SR)和伺服器傳送(SS)註釋。在物理上有2個spans,但它們形成與RPC呼叫相關的1個邏輯跨度。
-
2 spans來自service2到service3到http:/bar端點的RPC呼叫。它在service2方面具有客戶端傳送(CS)和客戶接收(CR)註釋。它還具有service3端的伺服器接收(SR)和伺服器傳送(SS)註釋。在物理上有2個spans,但它們形成與RPC呼叫相關的1個邏輯跨度。
-
2 spans來自service2到service4到http:/baz端點的RPC呼叫。它在service2方面具有客戶端傳送(CS)和客戶接收(CR)註釋。它還在service4側具有伺服器接收(SR)和伺服器傳送(SS)註釋。在物理上有2個spans,但它們形成與RPC呼叫相關的1個邏輯跨度。
因此,如果我們計算spans ,http:/start中有1 個來自service1的呼叫service2,2(service2)呼叫service3和2(service2) service4。共7個 spans。
邏輯上,我們看到Total Spans的資訊:4,因為我們有1個跨度與傳入請求相關的service1和3 spans與RPC呼叫相關。
視覺化錯誤
Zipkin允許您視覺化跟蹤中的錯誤。當異常被丟擲並且沒有被捕獲時,我們在Zipkin可以正確著色的跨度上設定適當的標籤。您可以在痕跡列表中看到一條是紅色的痕跡。這是因為丟擲了一個異常。
如果您點選該軌跡,您將看到類似的圖片
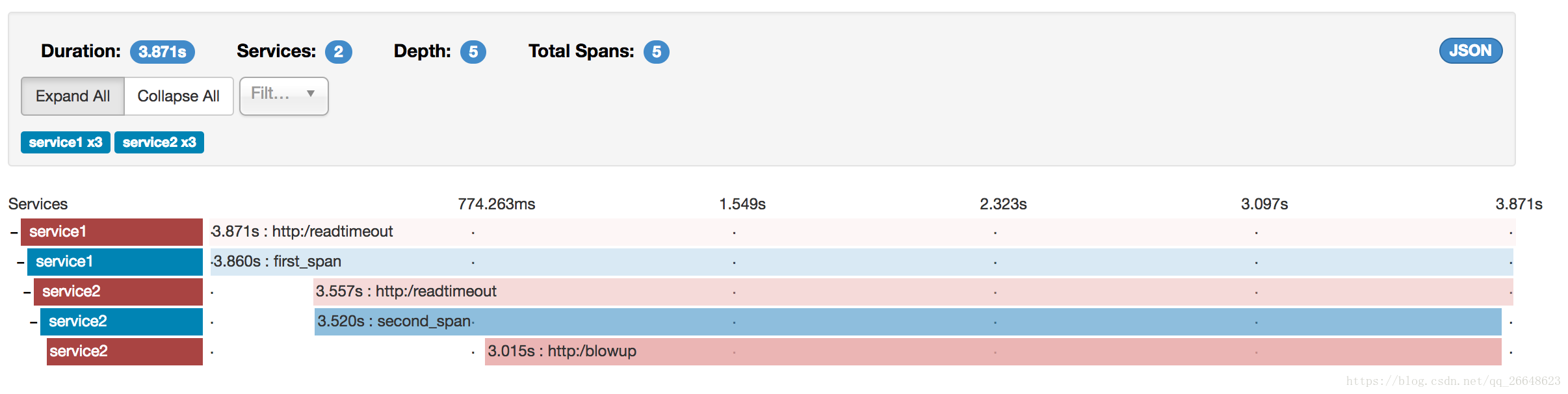
然後,如果您點選其中一個spans,您將看到以下內容
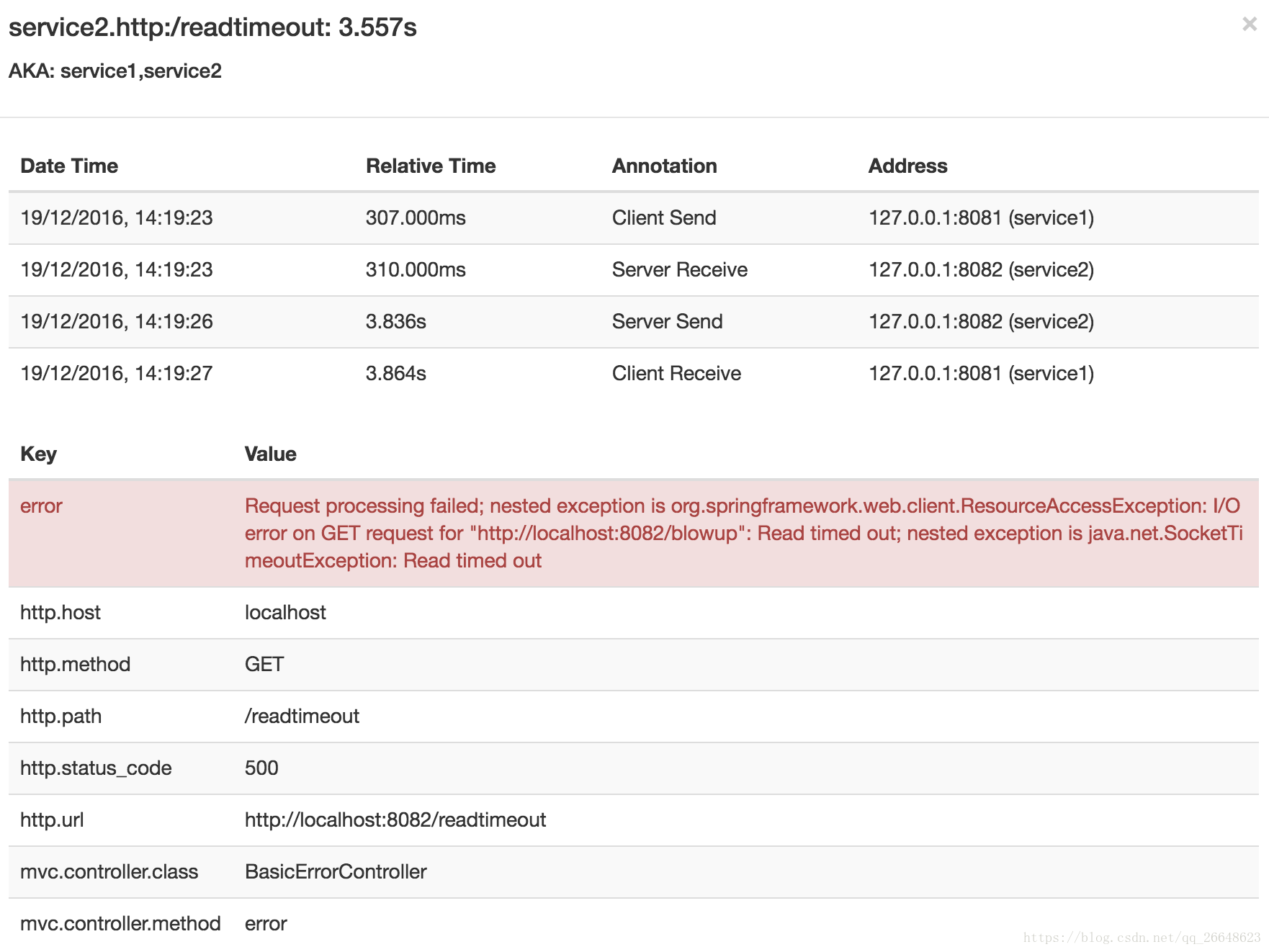
你可以看到,你可以很容易的看到錯誤的原因和整個stacktrace相關的。
Zipkin中的依賴圖將如下所示:

對數相關
當通過跟蹤id等於例如2485ec27856c56f4來對這四個應用程式的日誌進行灰名單時,將會得到以下內容:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2
service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4
service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3
service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3]
service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4
service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4]
service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]
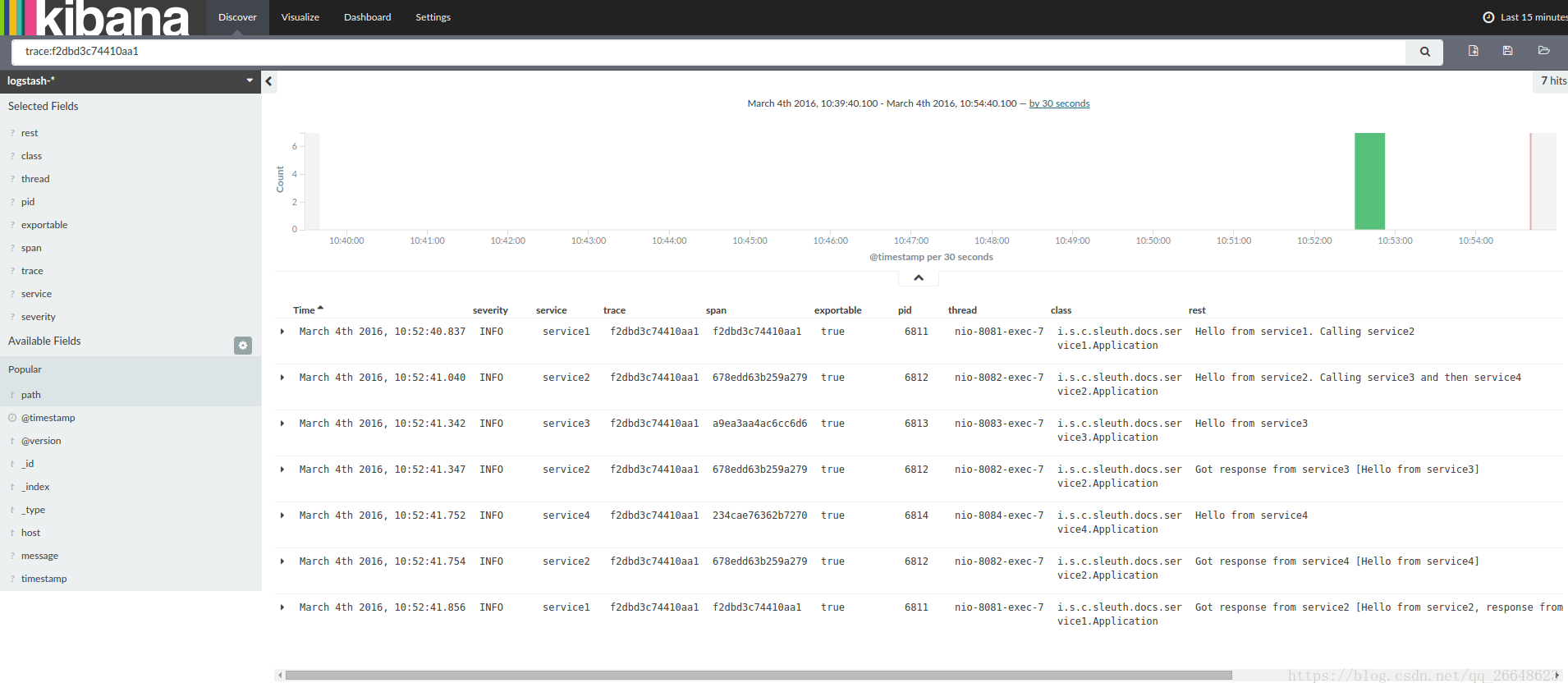
如果你使用像一個日誌聚合工具Kibana,
Splunk的等您可以訂購所發生的事件。基巴納的例子如下所示:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}
| 注意 | 如果您想將Grok與Cloud Foundry的日誌一起使用,則必須使用此模式: |
|---|
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}
使用Logstash進行JSON回溯
通常,您不希望將日誌儲存在文字檔案中,而不是將Logstash可以立即選擇的JSON檔案中儲存。為此,您必須執行以下操作(為了可讀性,我們將依賴關係傳遞給groupId:artifactId:version符號。
依賴關係設定
-
確保Logback位於類路徑(ch.qos.logback:logback-core)
-
新增Logstash Logback編碼 - 版本4.6的示例:net.logstash.logback:logstash-logback-encoder:4.6
回讀設定
您可以在下面找到一個Logback配置(名為logback-spring.xml)的示例:
-
將來自應用程式的資訊以JSON格式記錄到檔案
-
已經評論了兩個額外的追加者 - 控制檯和標準日誌檔案
-
具有與上一節所述相同的記錄模式
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
?
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>?
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->?
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
?
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"parent": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
?
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<!--<appender-ref ref="logstash"/>-->
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>
| 注意 | 如果您使用自定義logback-spring.xml,則必須通過bootstrap application而不是application屬性檔案傳遞spring.application.name。否則您的自定義logback檔案將不會正確讀取該屬性。 |
|---|
傳播Span上下文
跨度上下文是必須傳播到任何子程序跨越程序邊界的狀態。Span背景的一部分是行李。跟蹤和跨度ID是跨度上下文的必需部分。行李是可選的部分。
行李是一組金鑰:儲存在範圍上下文中的值對。行李與痕跡一起旅行,並附在每一個跨度上。Spring Cloud如果HTTP標頭以baggage-為字首,並且以baggage_開頭的訊息傳遞,Sleuth將會明白標題是行李相關的。
| 重要 | 行李物品的數量或大小目前沒有限制。但是,請記住,太多可能會降低系統吞吐量或增加RPC延遲。在極端情況下,由於超出了傳輸級訊息或報頭容量,可能會使應用程式崩潰。 |
|---|
在跨度上設定行李的示例:
Span initialSpan = this.tracer.createSpan("span");
initialSpan.setBaggageItem("foo", "bar");
行李與Span標籤
行李隨行旅行(即每個孩子跨度都包含其父母的行李)。Zipkin不瞭解行李,甚至不會收到這些資訊。
標籤附加到特定的跨度 - 它們僅針對該特定跨度呈現。但是,您可以通過標籤搜尋查詢跟蹤,其中存在具有搜尋標籤值的跨度。
如果您希望能夠根據行李查詢跨度,則應在根跨度中新增相應的條目作為標籤。
@Autowired Tracer tracer;
Span span = tracer.getCurrentSpan();
String baggageKey = "key";
String baggageValue = "foo";
span.setBaggageItem(baggageKey, baggageValue);
tracer.addTag(baggageKey, baggageValue);
新增到專案中
只有Sleuth(對數相關)
如果您只想從Spring Cloud Sleuth中獲利,而沒有Zipkin整合,只需將spring-cloud-starter-sleuth模組新增到您的專案中即可。
Maven的
<dependencyManagement> <b class="conum">(1)</b>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Camden.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
-
為了不自己選擇版本,如果您通過Spring BOM新增依賴關係管理,會更好
-
將依賴關係新增到spring-cloud-starter-sleuth
搖籃
dependencyManagement { <b class="conum">(1)</b>
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Camden.RELEASE"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
}
-
為了不自己選擇版本,如果您通過Spring BOM新增依賴關係管理,會更好
-
將依賴關係新增到spring-cloud-starter-sleuth
通過HTTP訪問Zipkin
如果你想要Sleuth和Zipkin只需新增spring-cloud-starter-zipkin依賴關係。
Maven的
<dependencyManagement> <b class="conum">(1)</b>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Camden.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
-
為了不自己選擇版本,如果您通過Spring BOM新增依賴關係管理,會更好
-
將依賴關係新增到spring-cloud-starter-zipkin
搖籃
dependencyManagement { <b class="conum">(1)</b>
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Camden.RELEASE"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
}
-
為了不自己選擇版本,如果您通過Spring BOM新增依賴關係管理,會更好
-
將依賴關係新增到spring-cloud-starter-zipkin
通過Spring Cloud Stream使用Zipkin的Sleuth
如果你想要Sleuth和Zipkin只需新增spring-cloud-sleuth-stream依賴關係。
Maven的
<dependencyManagement> <b class="conum">(1)</b>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Camden.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
<dependency> (3)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- EXAMPLE FOR RABBIT BINDING -->
<dependency> (4)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
-
為了不自己選擇版本,如果您通過Spring BOM新增依賴關係管理,會更好
-
將依賴關係新增到spring-cloud-sleuth-stream
-
將依賴關係新增到spring-cloud-starter-sleuth中,這樣就可以下載依賴關係
-
新增一個粘合劑(例如Rabbit binder)來告訴Spring Cloud Stream應該繫結什麼
搖籃
dependencyManagement { <b class="conum">(1)</b>
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Camden.RELEASE"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-sleuth-stream" (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth" (3)
// Example for Rabbit binding
compile "org.springframework.cloud:spring-cloud-stream-binder-rabbit" (4)
}
-
為了不自己選擇版本,如果您通過Spring BOM新增依賴關係管理,會更好
-
將依賴關係新增到spring-cloud-sleuth-stream
-
將依賴關係新增到spring-cloud-starter-sleuth中,這樣就可以下載所有依賴關係
-
新增一個粘合劑(例如Rabbit binder)來告訴Spring Cloud Stream應該繫結什麼
Spring Cloud Sleuth Stream Zipkin收藏家
如果要啟動Spring Cloud Sleuth Stream Zipkin收藏夾,只需新增spring-cloud-sleuth-zipkin-stream依賴關係即可
Maven的
<dependencyManagement> <b class="conum">(1)</b>
相關推薦
Spring Cloud Sleuth 分散式跟蹤解決方案
Spring Cloud Sleuth
Adrian Cole,Spencer Gibb,Marcin Grzejszczak,Dave Syer
Dalston.RELEASE
Spring Cloud Sleuth為Spring Cloud實現分散式跟蹤解決
Spring系列學習之Spring Cloud Sleuth分散式跟蹤解決方案
英文原文:https://spring.io/projects/spring-cloud-sleuth
目錄
概述
特性
Spring Boot配置
快速開始
學習
文件
示例
概述
Spring Cloud Sleuth為Spring Cloud實施分散
Spring Cloud 中 分散式事務解決方案 -- 阿里GTS的使用
1:依賴引入
<!--gts相關-->
<!--資料庫連線-->
<dependency>
<groupId>org.springframework.b
Spring Cloud Sleuth(分散式服務跟蹤)(1)
首先準備工作如下:
1.服務註冊中心:eureka-server。
2.微服務應用:trace-1,實現REST介面,並呼叫trace-2應用的介面。
其pom.xml檔案如下:
<?xml version="1.0" encoding="UTF-8"?>
<p
spring Cloud Sleuth 分散式服務跟蹤
前瞻:
首先我們知道spring Cloud Sleuth分散式服務跟蹤是幹什麼的,在現如今的系統規模中,隨著系統規模的越來越大,微服務之間的呼叫關係越來越錯綜複雜,通常一個前端的請求在系統中會經過多個微服務之間的呼叫最後才能返回正確的結果,而在這麼多微服務之間
Spring Cloud Sleuth服務跟蹤
監控
使用zipkin(https://zipkin.io/)
監控服務構建: (普通的springBoot專案)
<!--引入的zipkinServer依賴-->
<dependency>
<groupId>io.zipkin.java</gro
Spring cloud 微服務安全解決方案
Restful 的通訊安全有很多中解決方案,例如
1. HTTP Basic Auth 認證 2. Cooke / Session 認證 3. Token 認證 &nbs
第十八天:浪跡天涯網上商城(1.0版本)--引入spring cloud sleuth分散式鏈路追蹤
1、需求
我們都知道隨著專案的發展,各個底層的服務呼叫關係複雜,有時候因為某個服務的效能問題導致整個呼叫鏈出現故障,那麼排查問題是很困難的。現在我們引入Spring Cloud Sleuth分散式鏈路追蹤來解決這個問題。
2、Spring Cloud Sleut
【spring cloud】spring cloud Sleuth 和Zipkin 進行分散式鏈路跟蹤
spring cloud 分散式微服務架構下,所有請求都去找閘道器,對外返回也是統一的結果,或者成功,或者失敗。
但是如果失敗,那分散式系統之間的服務呼叫可能非常複雜,那麼要定位到發生錯誤的具體位置,就是一個比較麻煩的問題。
所以定位故障點,就引入了spring cloud Sleuth【Sleuth是獵
springcloud(十二):使用Spring Cloud Sleuth和Zipkin進行分散式鏈路跟蹤
Spring Cloud Sleuth 一般的,一個分散式服務跟蹤系統,主要有三部分:資料收集、資料儲存和資料展示。根據系統大小不同,每一部分的結構又有一定變化。譬如,對於大規模分散式系統,資料儲存可分為實時資料和全量資料兩部分,實時資料用於故障排查(troubleshooting),全量資料用於系統優化;資
Spring Cloud:使用Spring Cloud Sleuth和Zipkin進行分散式鏈路跟蹤(12)
隨著業務發展,系統拆分導致系統呼叫鏈路愈發複雜一個前端請求可能最終需要呼叫很多次後端服務才能完成,當整個請求變慢或不可用時,我們是無法得知該請求是由某個或某些後端服務引起的,這時就需要解決如何快讀定位服務故障點,以對症下藥。於是就有了分散式系統呼叫跟蹤的誕生。
現今業界分散式服務跟蹤的理論基礎主
springcloud+springboot(十二):使用Spring Cloud Sleuth和Zipkin進行分散式鏈路跟蹤
Spring Cloud Sleuth
一般的,一個分散式服務跟蹤系統,主要有三部分:資料收集、資料儲存和資料展示。根據系統大小不同,每一部分的結構又有一定變化。譬如,對於大規模分散式系統,資料儲存可分為實時資料和全量資料兩部分,實時資料用於故障排查(troubleshooting),全量資料用於系統優化
Spring Cloud分散式事務解決方案
開源專案
我們利用訊息佇列實現了分散式事務的最終一致性解決方案,請大家圍觀。可以參考Github CoolMQ原始碼,專案支援網站: http://rabbitmq.org.cn,最新文章或實現會更新在上面
二 前言
阿里2017雲棲大會《破解世界性技術難題!GTS
SpringCloud之分散式服務跟蹤 Spring Cloud Sleuth
隨著業務的發展,系統規模也變的越來越大,各微服務間的呼叫關係也變得越來越錯綜複雜。通常一個由客戶端發起的請求在後端系統好中會經過多個不同的微服務呼叫來協同產生最後的請求結果,在複雜的微服務架構系統中,幾乎每一個前端請求都會形成一條複雜的分散式服務呼叫鏈路,在
SpringCloud之分散式服務跟蹤Spring Cloud Sleuth例項
一、簡介
隨著業務的發展,系統規模也會變得越來越大,各微服務間的呼叫關係也變得越來越錯綜複雜。通常一個由客戶端發起的請求在後端系統中會經過多個不同的微服務呼叫來協同產生最後的請求結果,在複雜的微服務架構系統中,幾乎每一個前端請求都會形成一條複雜的分散式服務呼叫鏈路,在每條鏈
跟我學SpringCloud | 第十一篇:使用Spring Cloud Sleuth和Zipkin進行分散式鏈路跟蹤
SpringCloud系列教程 | 第十一篇:使用Spring Cloud Sleuth和Zipkin進行分散式鏈路跟蹤
Springboot: 2.1.6.RELEASE
SpringCloud: Greenwich.SR1
如無特殊說明,本系列教程全採用以上版本
在分散式服務架構中,需要對分散
spring cloud微服務快速教程之(十二) 分散式ID解決方案(mybatis-plus篇)
0-前言
分散式系統中,分散式ID是個必須解決的問題點;
雪花演算法是個好方式,不過不能直接使用,因為如果直接使用的話,需要配置每個例項workerId和datacenterId,在微服務中,例項一般動態配置,直接指定具體例項的這兩個引數是不現實的;
所以,一般採用雪花演算法的變種,主要是將這兩個
微服務學習筆記--使用Spring Cloud Sleuth配合Zipkin實現微服務的跟蹤
在微服務架構中可以使用Zipkin來追蹤服務呼叫鏈路,可以知道各個服務的呼叫依賴關係。在Spring Cloud中,也提供了Spring Cloud Sleuth來方便整合Zipkin實現。
本文使用一個Zipkin Server,使用者微服務,電影微服務來實現
Spring Cloud Sleuth鏈路跟蹤之使用Mysq儲存服務鏈路跟蹤資訊(學習總結)
一、簡介
我們在上上一篇文章(https://blog.csdn.net/Weixiaohuai/article/details/82883280)已經實現了通過RabbitMQ訊息中介軟體的方式來收集服務鏈路跟蹤資訊,但是當zipkin-server服務端重啟之後,你會發
Spring Cloud Sleuth和zipkin微服務跟蹤
Spring Cloud Sleuth是為Spring Cloud實現了分散式追蹤解決方案。
Spring Cloud Sleuth借用了Dapper的術語:
跨度(Span):基本的工作單位。例如,傳送一個RPC是一個新的跨度,就像向RPC傳送響應