
YOLOv2 / YOLO9000 深入理解
YOLOv2相對v1版本,在繼續保持處理速度的基礎上,從預測更準確(Better),速度更快(Faster),識別物件更多(Stronger)這三個方面進行了改進。其中識別更多物件也就是擴充套件到能夠檢測9000種不同物件,稱之為YOLO9000。
關於YOLO v1的內容,請參考 YOLO v1深入理解。下面具體看下YOLO2都做了哪些改進。
預測更準確(Better)
論文[1]中給出了下面的改進專案列表,列出各項改進對mAP的提升效果。

1)batch normalization(批歸一化)
批歸一化使mAP有2.4的提升。
批歸一化有助於解決反向傳播過程中的梯度消失和梯度爆炸問題,降低對一些超引數(比如學習率、網路引數的大小範圍、啟用函式的選擇)的敏感性,並且每個batch分別進行歸一化的時候,起到了一定的正則化效果(YOLO2不再使用dropout),從而能夠獲得更好的收斂速度和收斂效果。
通常,一次訓練會輸入一批樣本(batch)進入神經網路。批規一化在神經網路的每一層,在網路(線性變換)輸出後和啟用函式(非線性變換)之前增加一個批歸一化層(BN),BN層進行如下變換:①對該批樣本的各特徵量(對於中間層來說,就是每一個神經元)分別進行歸一化處理,分別使每個特徵的資料分佈變換為均值0,方差1。從而使得每一批訓練樣本在每一層都有類似的分佈。這一變換不需要引入額外的引數。②對上一步的輸出再做一次線性變換,假設上一步的輸出為Z,則Z1=γZ + β。這裡γ、β是可以訓練的引數。增加這一變換是因為上一步驟中強制改變了特徵資料的分佈,可能影響了原有資料的資訊表達能力。增加的線性變換使其有機會恢復其原本的資訊。
2)使用高解析度影象微調分類模型
mAP提升了3.7。
影象分類的訓練樣本很多,而標註了邊框的用於訓練物件檢測的樣本相比而言就比較少了,因為標註邊框的人工成本比較高。所以物件檢測模型通常都先用影象分類樣本訓練卷積層,提取影象特徵。但這引出的另一個問題是,影象分類樣本的解析度不是很高。所以YOLO v1使用ImageNet的影象分類樣本採用 224*224 作為輸入,來訓練CNN卷積層。然後在訓練物件檢測時,檢測用的影象樣本採用更高解析度的 448*448 的影象作為輸入。但這樣切換對模型效能有一定影響。
所以YOLO2在採用 224*224 影象進行分類模型預訓練後,再採用 448*448 的高解析度樣本對分類模型進行微調(10個epoch),使網路特徵逐漸適應 448*448 的解析度。然後再使用 448*448 的檢測樣本進行訓練,緩解了解析度突然切換造成的影響。
3)採用先驗框(Anchor Boxes)
召回率大幅提升到88%,同時mAP輕微下降了0.2。
借鑑Faster RCNN的做法,YOLO2也嘗試採用先驗框(anchor)。在每個grid預先設定一組不同大小和寬高比的邊框,來覆蓋整個影象的不同位置和多種尺度,這些先驗框作為預定義的候選區在神經網路中將檢測其中是否存在物件,以及微調邊框的位置。
同時YOLO2移除了全連線層。另外去掉了一個池化層,使網路卷積層輸出具有更高的解析度。
之前YOLO1並沒有採用先驗框,並且每個grid只預測兩個bounding box,整個影象98個。YOLO2如果每個grid採用9個先驗框,總共有13*13*9=1521個先驗框。所以,相對YOLO1的81%的召回率,YOLO2的召回率大幅提升到88%。同時mAP有0.2%的輕微下降。
不過YOLO2接著進一步對先驗框進行了改良。
4)聚類提取先驗框尺度
聚類提取先驗框尺度,結合下面的約束預測邊框的位置,使得mAP有4.8的提升。
之前先驗框都是手工設定的,YOLO2嘗試統計出更符合樣本中物件尺寸的先驗框,這樣就可以減少網路微調先驗框到實際位置的難度。YOLO2的做法是對訓練集中標註的邊框進行聚類分析,以尋找儘可能匹配樣本的邊框尺寸。
聚類演算法最重要的是選擇如何計算兩個邊框之間的“距離”,對於常用的歐式距離,大邊框會產生更大的誤差,但我們關心的是邊框的IOU。所以,YOLO2在聚類時採用以下公式來計算兩個邊框之間的“距離”。 centroid是聚類時被選作中心的邊框,box就是其它邊框,d就是兩者間的“距離”。IOU越大,“距離”越近。YOLO2給出的聚類分析結果如下圖所示:
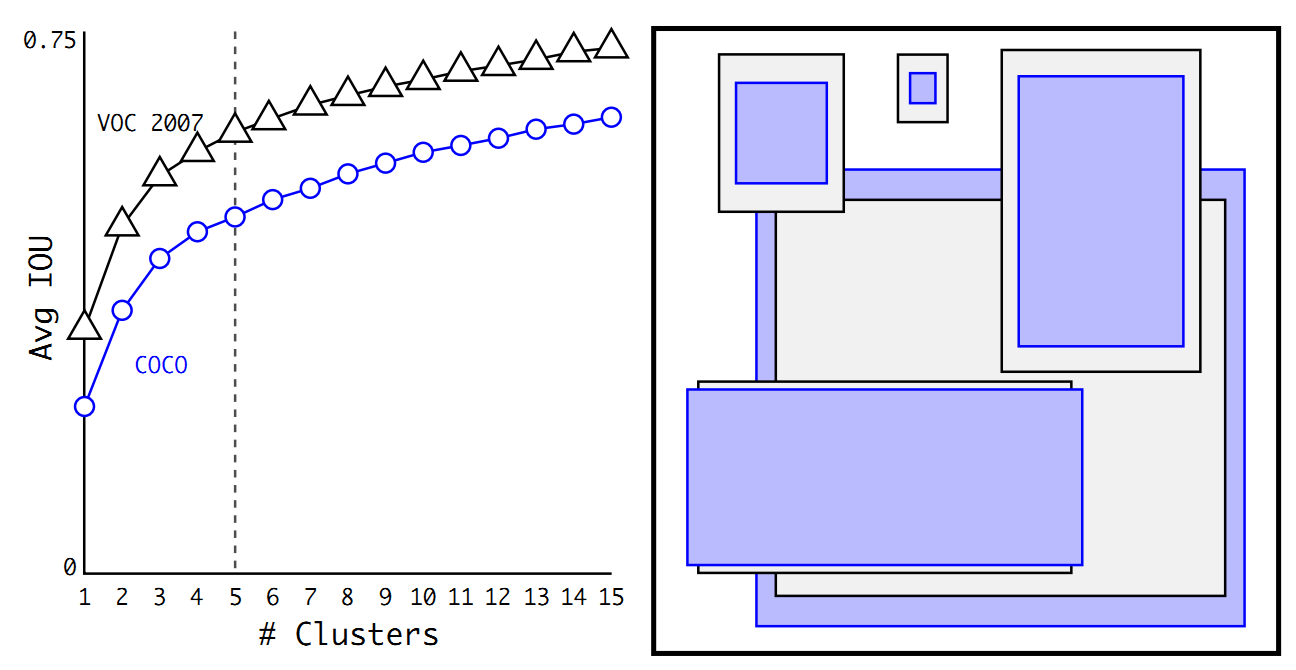
上圖左邊是選擇不同的聚類k值情況下,得到的k個centroid邊框,計算樣本中標註的邊框與各centroid的Avg IOU。顯然,邊框數k越多,Avg IOU越大。YOLO2選擇k=5作為邊框數量與IOU的折中。對比手工選擇的先驗框,使用5個聚類框即可達到61 Avg IOU,相當於9個手工設定的先驗框60.9 Avg IOU。
上圖右邊顯示了5種聚類得到的先驗框,VOC和COCO資料集略有差異,不過都有較多的瘦高形邊框。
5)約束預測邊框的位置
借鑑於Faster RCNN的先驗框方法,在訓練的早期階段,其位置預測容易不穩定。其位置預測公式為:
其中, 是預測邊框的中心, 是先驗框(anchor)的中心點座標, 是先驗框(anchor)的寬和高, 是要學習的引數。 注意,YOLO論文中寫的是,根據Faster RCNN,應該是"+"。
由於的取值沒有任何約束,因此預測邊框的中心可能出現在任何位置,訓練早期階段不容易穩定。YOLO調整了預測公式,將預測邊框的中心約束在特定gird網格內。
其中, 是預測邊框的中心和寬高。 是預測邊框的置信度,YOLO1是直接預測置信度的值,這裡對預測引數進行σ變換後作為置信度的值。 是當前網格左上角到影象左上角的距離,要先將網格大小歸一化,即令一個網格的寬=1,高=1。 是先驗框的寬和高。 σ是sigmoid函式。 是要學習的引數,分別用於預測邊框的中心和寬高,以及置信度。
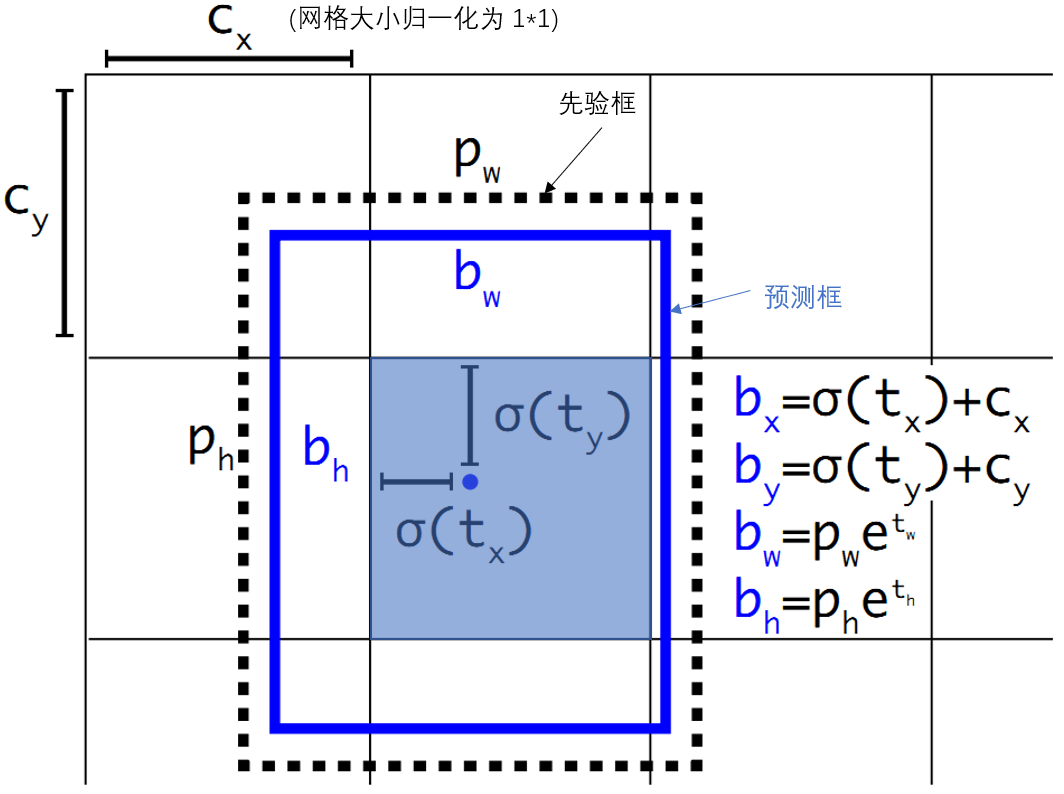
參考上圖,由於σ函式將約束在(0,1)範圍內,所以根據上面的計算公式,預測邊框的藍色中心點被約束在藍色背景的網格內。約束邊框位置使得模型更容易學習,且預測更為穩定。
6)passthrough層檢測細粒度特徵
passthrough層檢測細粒度特徵使mAP提升1。
物件檢測面臨的一個問題是影象中物件會有大有小,輸入影象經過多層網路提取特徵,最後輸出的特徵圖中(比如YOLO2中輸入416*416經過卷積網路下采樣最後輸出是13*13),較小的物件可能特徵已經不明顯甚至被忽略掉了。為了更好的檢測出一些比較小的物件,最後輸出的特徵圖需要保留一些更細節的資訊。
YOLO2引入一種稱為passthrough層的方法在特徵圖中保留一些細節資訊。具體來說,就是在最後一個pooling之前,特徵圖的大小是26*26*512,將其1拆4,直接傳遞(passthrough)到pooling後(並且又經過一組卷積)的特徵圖,兩者疊加到一起作為輸出的特徵圖。
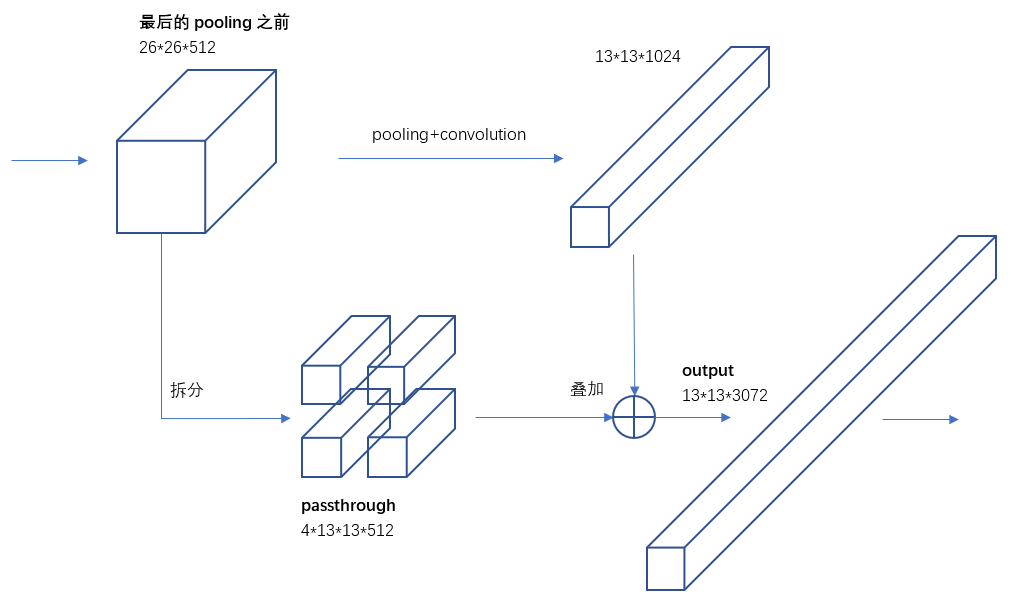
具體怎樣1拆4,下面借用參考文章[3]中的一副圖看的很清楚。圖中示例的是1個4*4拆成4個2*2。因為深度不變,所以沒有畫出來。
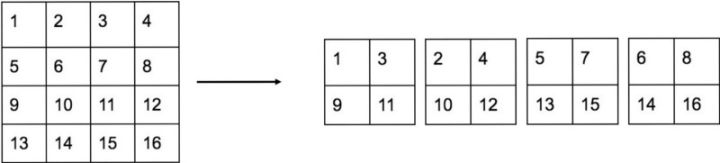
另外,根據YOLO2的程式碼,特徵圖先用1*1卷積從 26*26*512 降維到 26*26*64,再做1拆4並passthrough。下面圖6有更詳細的網路輸入輸出結構。
7)多尺度影象訓練
多尺度影象訓練對mAP有1.4的提升。
因為去掉了全連線層,YOLO2可以輸入任何尺寸的影象。因為整個網路下采樣倍數是32,作者採用了{320,352,…,608}等10種輸入影象的尺寸,這些尺寸的輸入影象對應輸出的特徵圖寬和高是{10,11,…19}。訓練時每10個batch就隨機更換一種尺寸,使網路能夠適應各種大小的物件檢測。
8)高解析度影象的物件檢測
圖1表格中最後一行有個hi-res detector,使mAP提高了1.8。因為YOLO2調整網路結構後能夠支援多種尺寸的輸入影象。通常是使用416*416的輸入影象,如果用較高解析度的輸入影象,比如544*544,則mAP可以達到78.6,有1.8的提升。
速度更快(Faster)
為了進一步提升速度,YOLO2提出了Darknet-19(有19個卷積層和5個MaxPooling層)網路結構。DarkNet-19比VGG-16小一些,精度不弱於VGG-16,但浮點運算量減少到約1/5,以保證更快的運算速度。

YOLO2的訓練主要包括三個階段。第一階段就是先在ImageNet分類資料集上預訓練Darknet-19,此時模型輸入為 224*224 ,共訓練160個epochs。然後第二階段將網路的輸入調整為 448*448 ,繼續在ImageNet資料集上finetune分類模型,訓練10個epochs,此時分類模型的top-1準確度為76.5%,而top-5準確度為93.3%。第三個階段就是修改Darknet-19分類模型為檢測模型,移除最後一個卷積層、global avgpooling層以及softmax層,並且新增了三個 3*3*1024卷積層,同時增加了一個passthrough層,最後使用 1*1 卷積層輸出預測結果,輸出的channels數為:num_anchors*(5+num_classes) ,和訓練採用的資料集有關係。由於anchors數為5,對於VOC資料集(20種分類物件)輸出的channels數就是125,最終的預測矩陣T的shape為 (batch_size, 13, 13, 125),可以先將其reshape為 (batch_size, 13, 13, 5, 25) ,其中 T[:, :, :, :, 0:4] 為邊界框的位置和大小 ,T[:, :, :, :, 4] 為邊界框的置信度,而 T[:, :, :, :, 5:] 為類別預測值。
物件檢測模型各層的結構如下(參考文章[4]):
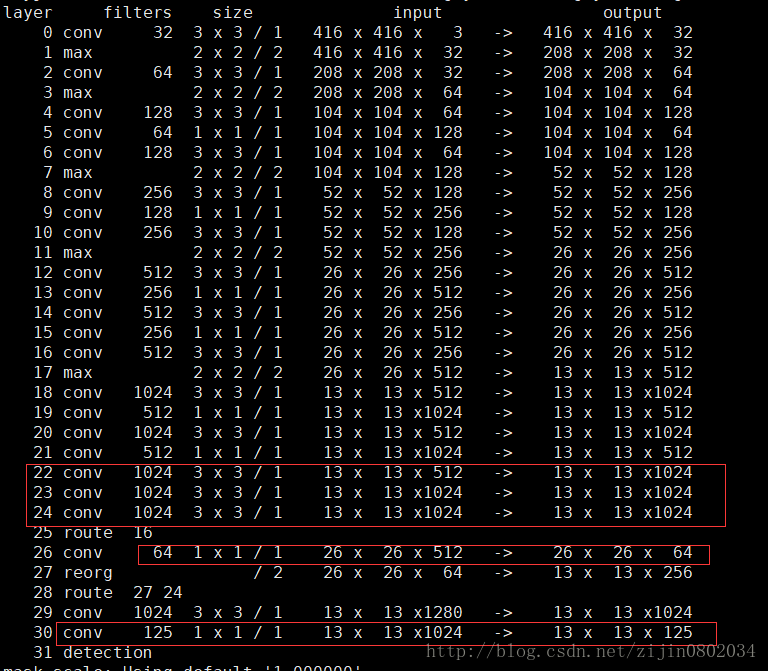
看一下passthrough層。圖中第25層route 16,意思是來自16層的output,即26*26*512,這是passthrough層的來源(細粒度特徵)。第26層1*1卷積降低通道數,從512降低到64(這一點論文在討論passthrough的時候沒有提到),輸出26*26*64。第27層進行拆分(passthrough層)操作,1拆4分成13*13*256。第28層疊加27層和24層的輸出,得到13*13*1280。後面再經過3*3卷積和1*1卷積,最後輸出13*13*125。
YOLO2 輸入->輸出
綜上所述,雖然YOLO2做出了一些改進,但總的來說網路結構依然很簡單。就是一些卷積+pooling,從416*416*3 變換到 13*13*5*25。稍微大一點的變化是增加了batch normalization,增加了一個passthrough層,去掉了全連線層,以及採用了5個先驗框。
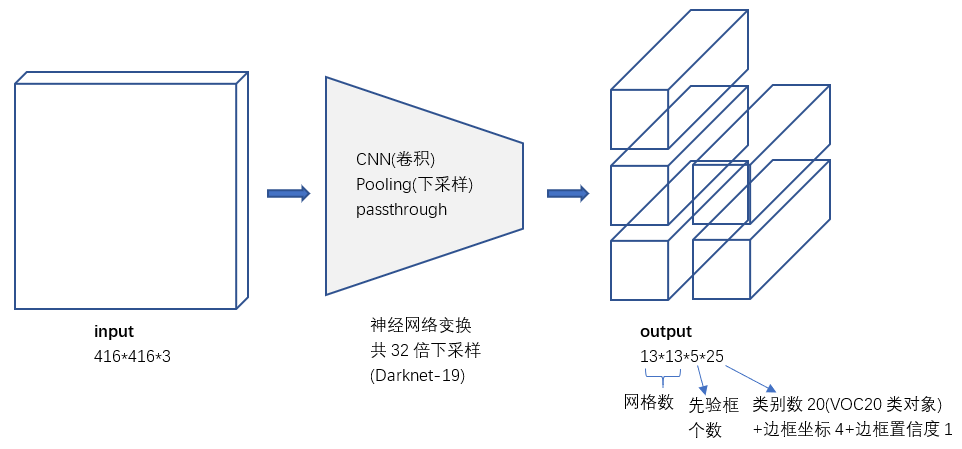
對比YOLO1的輸出張量,YOLO2的主要變化就是會輸出5個先驗框,且每個先驗框都會嘗試預測一個物件。輸出的 13*13*5*25 張量中,25維向量包含 20個物件的分類概率+4個邊框座標+1個邊框置信度。
YOLO2 誤差函式
誤差依然包括邊框位置誤差、置信度誤差、物件分類誤差。

公式中:
意思是預測邊框中,與真實物件邊框IOU最大的那個,其IOU<閾值Thresh,此係數為1,即計入誤差,否則為0,不計入誤差。YOLO2使用Thresh=0.6。
意思是前128000次迭代計入誤差。注意這裡是與先驗框的誤差,而不是與真實物件邊框的誤差。可能是為了在訓練早期使模型更快學會先預測先驗框的位置。
意思是該邊框負責預測一個真實物件(邊框內有物件)。
各種是不同型別誤差的調節係數。
識別物件更多(Stronger)/ YOLO9000
VOC資料集可以檢測20種物件,但實際上物件的種類非常多,只是缺少相應的用於物件檢測的訓練樣本。YOLO2嘗試利用ImageNet非常大量的分類樣本,聯合COCO的物件檢測資料集一起訓練,使得YOLO2即使沒有學過很多物件的檢測樣本,也能檢測出這些物件。
基本的思路是,如果是檢測樣本,訓練時其Loss包括分類誤差和定位誤差,如果是分類樣本,則Loss只包括分類誤差。
1)構建WordTree
要檢測更多物件,比如從原來的VOC的20種物件,擴充套件到ImageNet的9000種物件。簡單來想的話,好像把原來輸出20維的softmax改成9000維的softmax就可以了,但是,ImageNet的物件類別與COCO的物件類別不是互斥的。比如COCO物件類別有“狗”,而ImageNet細分成100多個品種的狗,狗與100多個狗的品種是包含關係,而不是互斥關係。一個Norfolk terrier同時也是dog,這樣就不適合用單個softmax來做物件分類,而是要採用一種多標籤分類模型。
YOLO2於是根據WordNet[5],將ImageNet和COCO中的名詞物件一起構建了一個WordTree,以physical object為根節點,各名詞依據相互間的關係構建樹枝、樹葉,節點間的連線表達了物件概念之間的蘊含關係(上位/下位關係)。
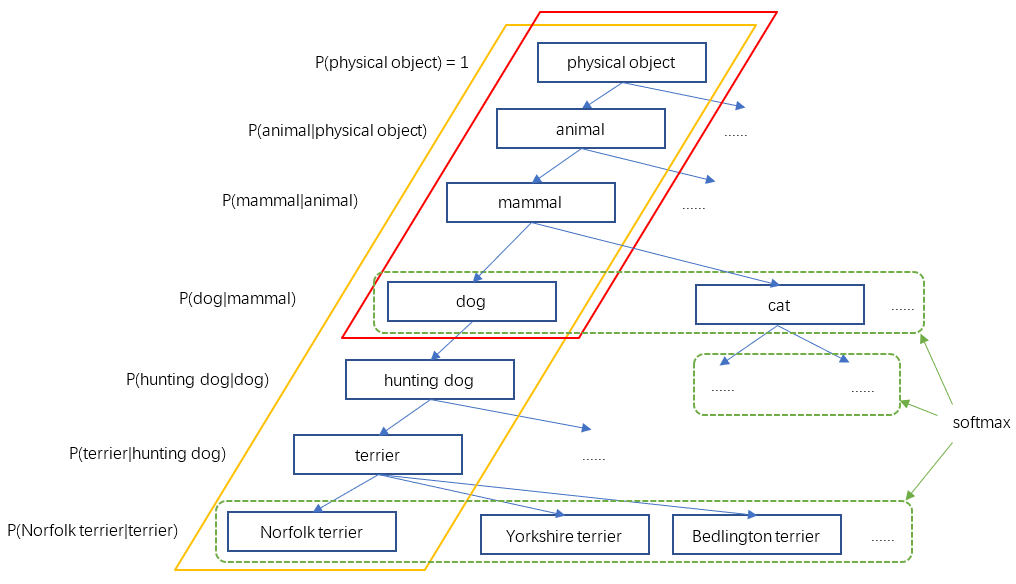
整個WordTree中的物件之間不是互斥的關係,但對於單個節點,屬於它的所有子節點之間是互斥關係。比如terrier節點之下的Norfolk terrier、Yorkshire terrier、Bedlington terrier等,各品種的terrier之間是互斥的,所以計算上可以進行softmax操作。上面圖10只畫出了3個softmax作為示意,實際中每個節點下的所有子節點都會進行softmax。
2)WordTree的構建方法。
構建好的WordTree有9418個節點(物件型別),包括ImageNet的Top 9000個物件,COCO物件,以及ImageNet物件檢測挑戰資料集中的物件,以及為了新增這些物件,從WordNet路徑中提取出的中間物件。
構建WordTree的步驟是:①檢查每一個將用於訓練和測試的ImageNet和COCO物件,在WordNet中找到對應的節點,如果該節點到WordTree根節點(physical object)的路徑只有一條(大部分物件都只有一條路徑),就將該路徑新增到WrodTree。②經過上面操作後,剩下的是存在多條路徑的物件。對每個物件,檢查其額外路徑長度(將其新增到已有的WordTree中所需的路徑長度),選擇最短的路徑新增到WordTree。這樣就構造好了整個WordTree。
3)WordTree如何表達物件的類別
之前物件互斥的情況下,用一個n維向量(n是預測物件的類別數)就可以表達一個物件(預測物件的那一維數值接近1,其它維數值接近0)。現在變成WordTree,如何表達一個物件呢?如果也是n維向量(這裡WordTree有9418個節點(物件),即9418維向量),使預測的物件那一位為1,其它維都為0,這樣的形式依然是互斥關係,這樣是不合理的。合理的向量應該能夠體現物件之間的蘊含關係。
比如一個樣本影象,其標籤是是"dog",那麼顯然dog節點的概率應該是1,然後,dog屬於mammal,自然mammal的概率也是1,…一直沿路徑向上到根節點physical object,所有經過的節點其概率都是1。參考上面圖10,紅色框內的節點概率都是1,其它節點概率為0。另一個樣本假如標籤是"Norfolk terrier",則從"Norfolk terrier"直到根節點的所有節點概率為1(圖10中黃色框內的節點),其它節點概率為0。
所以,一個WordTree對應且僅對應一個物件,不過該物件節點到根節點的所有節點概率都是1,體現出物件之間的蘊含關係,而其它節點概率是0。
4)預測時如何確定一個WordTree所對應的物件
上面講到訓練時,有標籤的樣本對應的WordTree中,該物件節點到根節點的所有節點概率都是1,其它節點概率是0。那麼用於預測時,如何根據WordTree各節點的概率值來確定其對應的物件呢?
根據訓練標籤的設定,其實模型學習的是各節點的條件概率。比如我們看WordTree(圖10)中的一小段。假設一個樣本標籤是dog,那麼dog=1,父節點mammal=1,同級節點cat=0,即P(dog|mammal)=1,P(cat|mammal)=0。
既然各節點預測的是條件概率,那麼一個節點的絕對概率就是它到根節點路徑上所有條件概率的乘積。比如
P(Norfolk terrier) = P(Norfolk terrier|terrier) * P(terrier|hunting dog) * P(hunting dog|dog) *…* P(animal|physical object) * P(physical object)
對於分類的計算,P(physical object) = 1。
不過,為了計算簡便,實際中並不計算出所有節點的絕對概率。而是採用一種比較貪婪的演算法。從根節點開始向下遍歷,對每一個節點,在它的所有子節點中,選擇概率最大的那個(一個節點下面的所有子節點是互斥的),一直向下遍歷直到某個節點的子節點概率低於設定的閾值(意味著很難確定它的下一層物件到底是哪個),或達到葉子節點,那麼該節點就是該WordTree對應的物件。
5)分類和檢測聯合訓練
由於ImageNet樣本比COCO多得多,所以對COCO樣本會多做一些取樣(oversampling),適當平衡一下樣本數量,使兩者樣本數量比為4:1。
YOLO9000依然採用YOLO2的網路結構,不過5個先驗框減少到3個先驗框,以減少計算量。YOLO2的輸出是13*13*5*(4+1+20),現在YOLO9000的輸出是13*13*3*(4+1+9418)。假設輸入是416*416*3。
由於物件分類改成WordTree的形式,相應的誤差計算也需要一些調整。對一個檢測樣本,其分類誤差只包含該標籤節點以及到根節點的所有節點的誤差。比如一個樣本的標籤是dog,那麼dog往上標籤都是1,但dog往下就不好設定了。因為這個dog其實必然也是某種具體的dog,假設它是一個Norfolk terrier,那麼最符合實際的設定是從Norfolk terrier到根節點的標籤都是1。但是因為樣本沒有告訴我們這是一個Norfolk terrier,只是說一個dog,那麼從dog以下的標籤就沒法確定了。
對於分類樣本,則只計算分類誤差。YOLO9000總共會輸出13*13*3=507個預測框(預測物件),計算它們對樣本標籤的預測概率,選擇概率最大的那個框負責預測該樣本的物件,即計算其WrodTree的誤差。
另外論文中還有一句話,“We also assume that the predicted box overlaps what would be the ground truth label by at least .3 IOU and we backpropagate objectness loss based on this assumption.”。感覺意思是其它那些邊框,選擇其中預測置信度>0.3的邊框,作為分類的負樣本(objectness)。即這些邊框不應該有那麼高的置信度來預測該樣本物件。具體的就要看下程式碼了。
小結
總的來說,YOLO2通過一些改進明顯提升了預測準確性,同時繼續保持其執行速度快的優勢。YOLO9000則開創性的提出聯合使用分類樣本和檢測樣本的訓練方法,使物件檢測能夠擴充套件到缺乏檢測樣本的物件。
最後,如果你竟然堅持看到這裡,覺得還有所幫助的話,請點個贊:)๑۩۞۩๑