
機器學習模型的特徵監控方案設計
1. 預備知識
1.1 KS-檢驗
KS-檢驗與t-檢驗等方法不同的是KS檢驗不需要知道資料的分佈情況,可以算是一種非引數檢驗方法。當然這樣方便的代價就是當檢驗的資料分佈符合特定的分佈時,KS-檢驗的靈敏度沒有相應的檢驗來的高。在樣本量比較小的時候,KS-檢驗最為非引數檢驗在分析兩組資料之間是否不同時相當常用。
PS:t-檢驗的假設是檢驗的資料滿足正態分佈,否則對於小樣本不滿足正態分佈的資料用t-檢驗就會造成較大的偏差,雖然對於大樣本不滿足正態分佈的資料而言t-檢驗還是相當精確有效的手段。
KS檢驗使用的是兩條累積分佈曲線之間的最大垂直差作為D值(statistic D)作為描述兩組資料之間的差異。在此圖中這個D值出現在x=1附近,而D值為0.45(0.65-0.25)。
1.2 CDF 累積分佈函式
累積分佈函式(Cumulative Distribution Function),又叫分佈函式,是概率密度函式的積分,能完整描述一個實隨機變數X的概率分佈。一般以大寫CDF標記,,與概率密度函式probability density function(小寫pdf)相對。
1.3 KS-檢驗D值計算
對以下兩組資料做KS-檢驗:
a = [1.26, 0.34, 0.70, 1.75, 50.57, 1.55, 0.08, 0.42, 0.50, 3.20, 0.15, 0.49, 0.95, 0.24, 1.37, 0.17, 6.98, 0.10, 0.94, 0.38]b = [2.37, 2.16, 14.82, 1.73, 41.04, 0.23, 1.32, 2.91, 39.41, 0.11, 27.44, 4.51, 0.51, 4.50, 0.18, 14.68, 4.66, 1.30, 2.06, 1.19]
1.3.1 對a組資料做統計描述
Mean = 3.61Median = 0.60High = 50.6 Low = 0.08Standard Deviation = 11.2可以發現這組資料並不符合正態分佈, 否則會有大約有15%的資料值小於-7.59(均值-標準差(3.61-11.2))。而資料中顯然沒有小於0的數值,所以該組資料不符合正態分佈。
1.3.2 觀察資料的累積分段函式(Cumulative Fraction Function)
注:google為Cumulative Distribution Function
對a組資料從小到大進行排序:
sorted a=[0.08, 0.10, 0.15, 0.17, 0.24, 0.34, 0.38, 0.42, 0.49, 0.50, 0.70, 0.94, 0.95, 1.26, 1.37, 1.55, 1.75, 3.20, 6.98, 50.57]。
觀察發現前10%的資料(2/20)小於0.15,前85%(17/20)的資料小於3。所以,對任何數x來說,其累積分段就是所有比x小的數在資料集中所佔的比例。
對於數0.15,其累積分段為10%,對於數3,其累積分段為85%......求出a組資料中所有數的累積分段值後繪製累積分段圖如下所示:
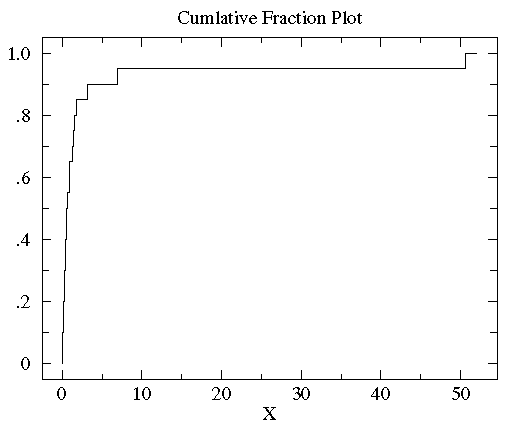 可以看到大多數資料都分佈在左側(資料值比較小),這就是非正態分佈的標誌(注:正態分佈兩邊小中間大)。為了更好的觀測資料在x軸上的分佈,可以對x軸的座標進行非等分的劃分。在資料都為正的時候有一個很好的方法就是對x軸進行log轉換。
可以看到大多數資料都分佈在左側(資料值比較小),這就是非正態分佈的標誌(注:正態分佈兩邊小中間大)。為了更好的觀測資料在x軸上的分佈,可以對x軸的座標進行非等分的劃分。在資料都為正的時候有一個很好的方法就是對x軸進行log轉換。
下圖就是對x軸的座標做log轉換以後的圖:

把b組資料按上述方法做同樣處理,結果如下,其中實線表示a組資料的累積分段,虛線表示b組資料的累積分段:
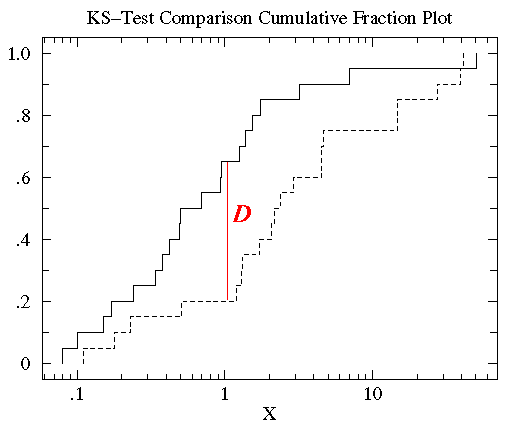
可以發現a和b的資料分佈範圍大致相同(0.1 - 50)。但是對於大部分x值,在a組資料集中比x小的資料所佔的比例比b組中的要高,也就是說達到相同累積比例的值在b組中比a組中要高。
1.3.3 計算D值
KS-檢驗使用的是兩條累積分佈曲線之間的最大垂直差作為D值(statistic D)來描述兩組資料之間的差異。在此圖中,D值出現在x=1附近,且D值為0.45(0.65-0.25)。
2. 為什麼要做特徵監控
舉一個例子:
眼看著雙十一快要到了,公司要做大促,實現留存拉新的目標,但面臨一個棘手的問題:總是有專業羊毛黨來薅羊毛。BOSS想到了公司新招了個演算法調包俠小王,於是找到了他,讓他做一個識別羊毛黨的模型。
小王開始了工作,構造訓練集、選模型、調參、測試...
訓練集的資料如下所示:
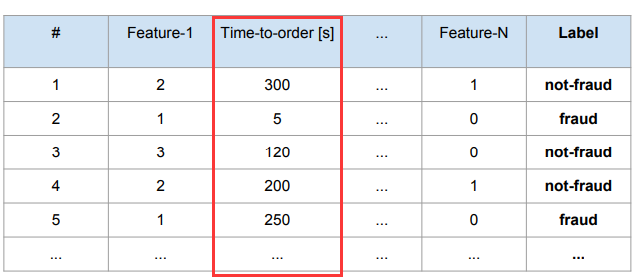
可以觀察到,Time-to-order [s] 欄位的分佈是這個樣子的:

模型訓練完成後,BOSS在測試集上一看:”效果挺不錯的嘛,趕緊上線!對了小王,你呀還得再加一個新功能,監控一下CPU、記憶體、延遲的情況。“.......”好的!“
過了兩週....
BOSS找到了小王:”你這咋回事,我們這麼多客戶,怎麼一個羊毛黨都發現不了???“

小王也納悶:線下效果很好啊,這是為什麼?

趕緊去檢視歷史日誌資訊,迅速發現了問題:
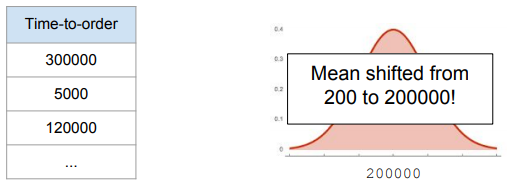
原來這個Time-to-order [s] 特徵是以毫秒為單位feed進模型的(不是以秒為單位)!所以導致所有的預測都是錯誤的!
雖然很快找到了原因,但兩週的時間仍然產生了諸多問題:
- 公司損失了很多錢。
- 開發人員沒有及時發現此問題。
- 開發人員本可以及時發現它並提供一個修復。
由於我們不能忽視預測質量的下降,所以我們需要持續監控已經部署的機器學習模型。當我們在某些領域開展業務時,往往面臨的一個挑戰是,我們模型的預測結果具有遲滯性。也就是說當我們注意到這個問題時,問題已經發生了。因此,需要監控實時流量中特徵分佈與模型評估測試集中特徵分佈之間的相似性,從而能夠立即發現並評估模型的輸入特徵是否發生了重大變化。
3. 監控方案的設計
3.1 確保輸入特徵的分佈(總是)與訓練時特徵的分佈相同
這裡是通過KS-檢驗實現。
3.2 資料聚合的視窗大小的設計

資料聚合的視窗設定較小,優點是可以快速檢測出是否有異常資料(特徵),缺點是受短期季節性或短期活動等波動因素的影響較大。
資料聚合的視窗設定較大,優點是受短期的季節性等波動因素的影響較小,缺點是對異常資料的檢測緩慢。
3.3 已監控特徵的分析頻次設計

高頻次分析的優點是可以更快地發現異常,缺點是計算複雜性高,成本高
低頻次分析的優點是不復雜,成本低,缺點是異常檢測緩慢。
3.4 監控介面設計
實際上,監控介面的設計和普通BI系統的區別不大。
在展示內容上,除了常見的模型CPU/GPU使用率、記憶體佔用率、模型響應時長等,往往還會按模型分組、建立特徵KS-檢驗直方圖、時間段選擇、異常特徵展示、不同模型實時效果對比等資訊。
