經典的機器學習模型(壹)
阿新 • • 發佈:2018-11-09
1 K近鄰演算法K-Nearest Neighbor (k-NN)
KNN是通過測量不同特徵值之間的距離進行分類。它的思路是:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,其中K通常是不大於20的整數。KNN演算法中,所選擇的鄰居都是已經正確分類的物件。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。
演算法描述:
1)計算測試資料與各個訓練資料之間的距離;
2)按照距離的遞增關係進行排序;
3)選取距離最小的K個點;
4)確定前K個點所在類別的出現頻率;
5)返回前K個點中出現頻率最高的類別作為測試資料的預測分類。
#coding:utf-8
from numpy import *
import operator
##給出訓練資料以及對應的類別
def createDataSet():
group = array([[1.0,2.0],[1.2,0.1],[0.1,1.4],[0.3,3.5]])
labels = ['A','A','B','B']
return group,labels
###通過KNN進行分類
def classify(input,dataSet,label,k):
dataSize = dataSet.shape[0]
####計算歐式距離
diff = #-*-coding:utf-8 -*-
import sys
sys.path.append("...檔案路徑...")
import KNN
from numpy import *
dataSet,labels = KNN.createDataSet()
input = array([1.1,0.3])
K = 3
output = KNN.classify(input,dataSet,labels,K)
print("測試資料為:",input,"分類結果為:",output)
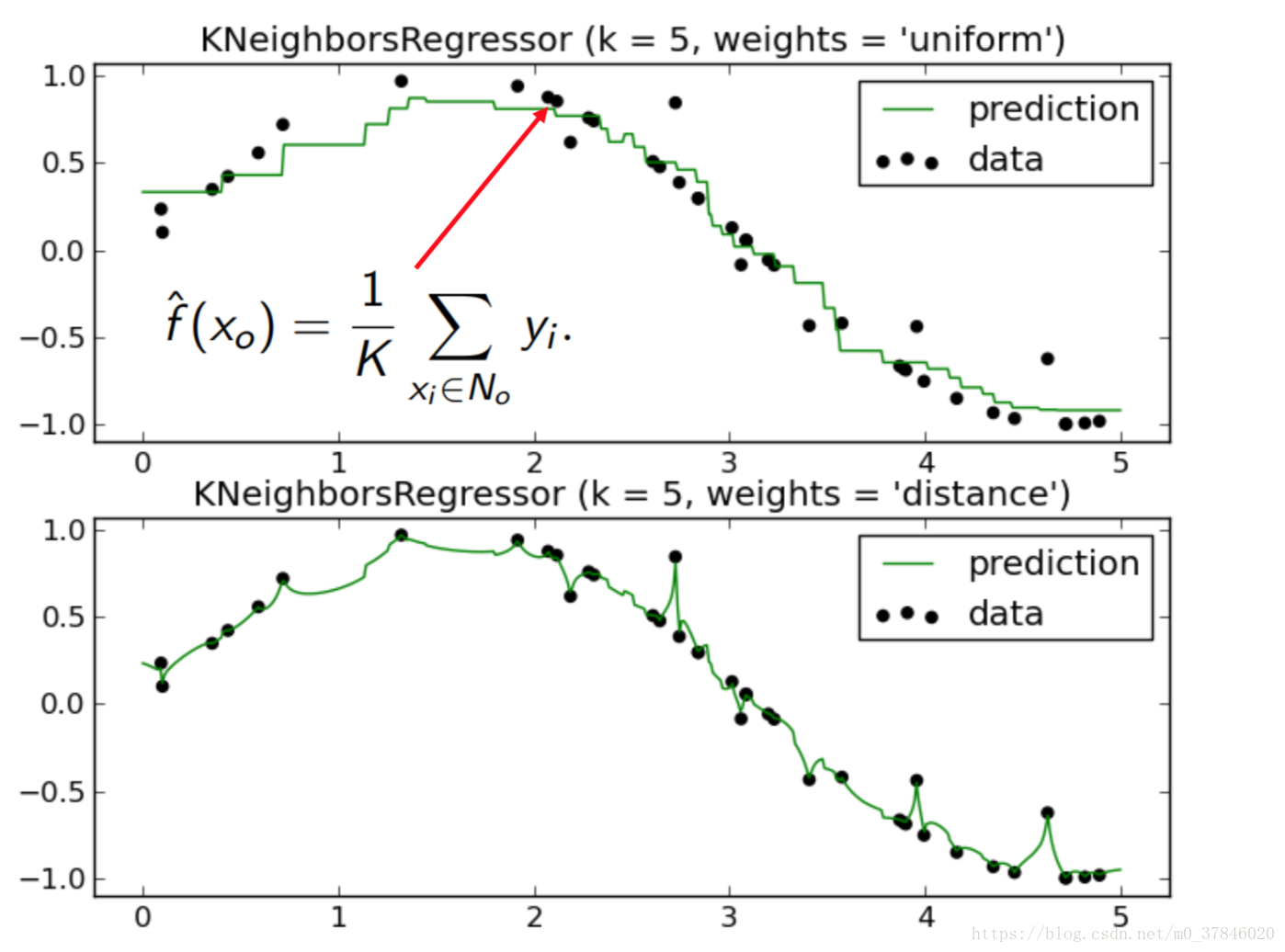
KNN用來回歸預測(KNN for Regression (Prediction))
2 樸素貝葉斯 Naïve Bayes
2.1 貝葉斯法則 (Bayes Rule)
是似然概率,
是先驗概率,
是標準化常量。
2.2 貝葉斯假設
在給定標籤(類別Y)的情況下,所有的特徵都是獨立的。也就是說:
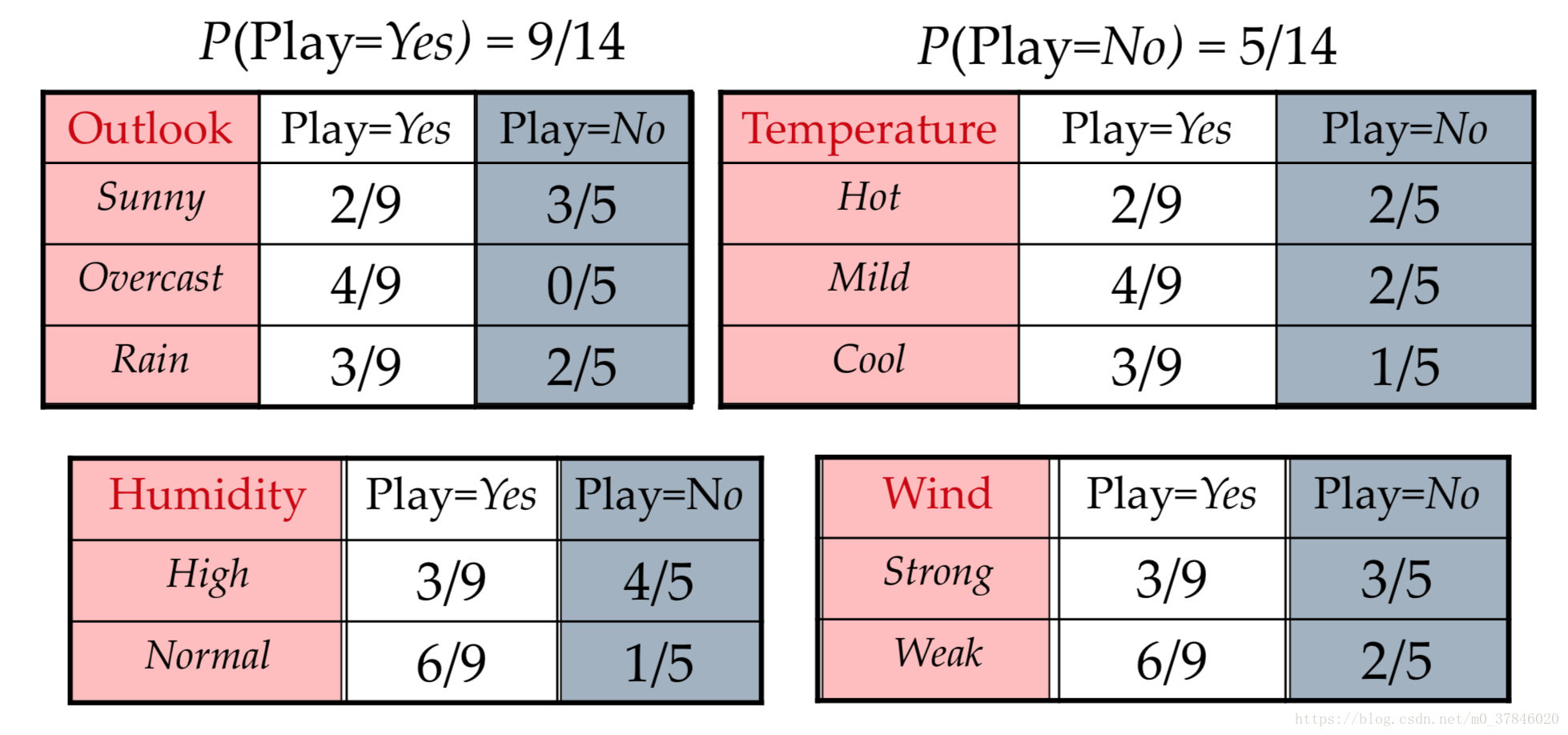
2.3練習
整理資料:
預測資料
屬於什麼標籤。