
Spark面試題(1)
面試題1:描述一下Spark 在yarn上的工作原理?
答:
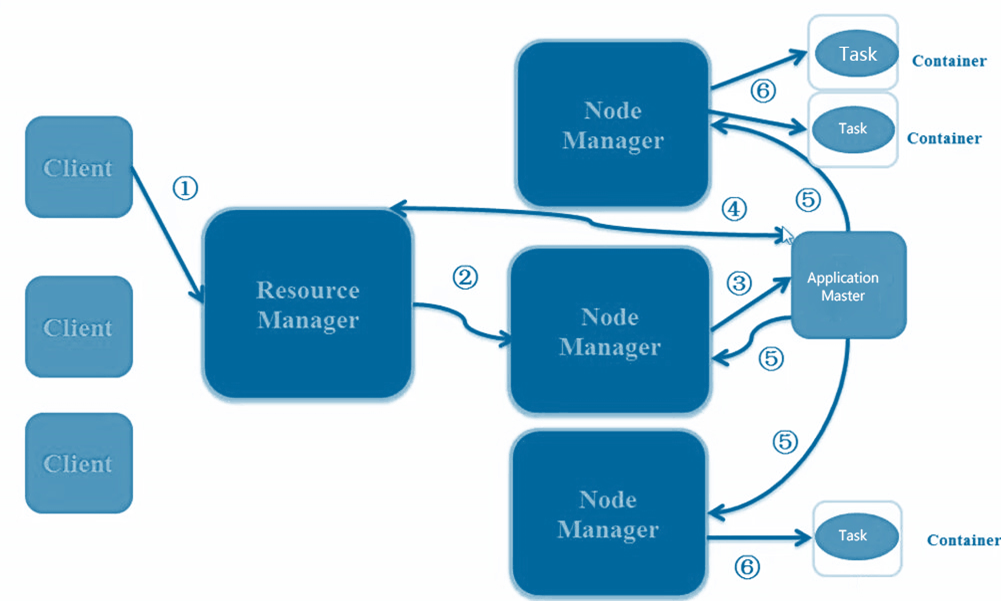
客戶端要提交一個yarn的作業,首先要通過Resource manager去分配一個container給node mananger,用來跑application master,然後application master到resource manager申請所需要的資源,ApplicationMaster通知NodeManager在獲得的Container中啟動excutor程序,在container裡面啟動executor,executor返回相應的執行狀態。如果是map-reduce,task換成map task和reduce task,若果是spark換成spark作業就好,所以很多作業都能跑到yarn上面的。
面試題2:說一下Spark-client和Spark-cluster的區別?
答: 廣義上來說就是Cluster模式適用於生產,Client適用於除錯模式。
底層來說:
(1)Client的Driver程序就執行在Client模式之上,application master僅僅向yarn請求executor,client會和請求的容器通訊來排程他們的工作,也就是client 不能離開。Cluster模式的Driver負責向yarn申請資源,並監督作業的執行情況,當用戶執行之後可以關閉client,作業仍然會執行在yarn上面。,客戶端是可以關閉的。
(2)總結來說就是Driver的位置不一樣和Application master的工作不一樣。
面試題3:簡述Spark中transformation和action的區別?
答:
(1)定義上區別
transformation:transformation是得到一個新的RDD,方式很多,比如從資料來源生成一個新的RDD,從RDD生成一個新的RDD。
action:action是得到一個值,或者一個結果(直接將RDDcache到記憶體中)
(2)底層執行的區別
transformation:它的執行採用的是懶策略,就是一不觸發action他是不會執行的。
action:它是直接觸發執行的。