spark計算使用者訪問學科子網頁的top3
阿新 • • 發佈:2018-12-18
專案說明:附件為要計算資料的demo。點選開啟連結
利用spark的快取機制,讀取需要篩選的資料,自定義一個分割槽器,將不同的學科資料分別放到一個分割槽器中,並且根據指定的學科,取出點選量前三的資料,並寫入檔案。
具體程式如下:
1、專案主程式:
- package cn.allengao.Location
- import java.net.URL
- import org.apache.spark.rdd.RDD
- import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
- /**
- * class_name:
- * package:
- * describe: 快取機制,自定義一個分割槽器,根據指定的學科, 取出點選量前三的,按照每種學科資料放到不同的分割槽器裡
- * creat_user: Allen Gao
- * creat_date: 2018/1/30
- * creat_time: 11:21
- **/
- object AdvUrlCount {
- def main(args: Array[String]) {
- //從資料庫中載入規則
- // val arr = Array("java.learn.com", "php.learn.com", "net.learn.com")
- val conf = new SparkConf().setAppName("AdvUrlCount").setMaster("local[2]")
- val sc = new SparkContext(conf)
- //獲取資料
- val file = sc.textFile("j://information/learn.log")
- //提取出url並生成一個元祖,rdd1將資料切分,元組中放的是(URL, 1)
- val urlAndOne = file.map(line => {
- val fields = line.split("\t")
- val url = fields(1)
- (url, 1)
- })
- //把相同的url進行聚合
- val sumedUrl = urlAndOne.reduceByKey(_ + _)
- //獲取學科資訊快取,提高執行效率
- val cachedProject = sumedUrl.map(x => {
- val url = x._1
- val project = new URL(url).getHost
- val count = x._2
- (project, (url, count))
- }).cache()
- //呼叫Spark自帶的分割槽器此時會發生雜湊碰撞,會有資料傾斜問題產生,需要自定義分割槽器
- // val res = cachedProject.partitionBy(new HashPartitioner(3))
- // res.saveAsTextFile("j://information//out")
- //得到所有學科
- val projects = cachedProject.keys.distinct().collect()
- //呼叫自定義分割槽器並得到分割槽號
- val partitioner = new ProjectPartitioner(projects)
- //分割槽
- val partitioned: RDD[(String, (String, Int))] = cachedProject.partitionBy(partitioner)
- //對每個分割槽的資料進行排序並取top3
- val res = partitioned.mapPartitions(it => {
- it.toList.sortBy(_._2._2).reverse.take(3).iterator
- })
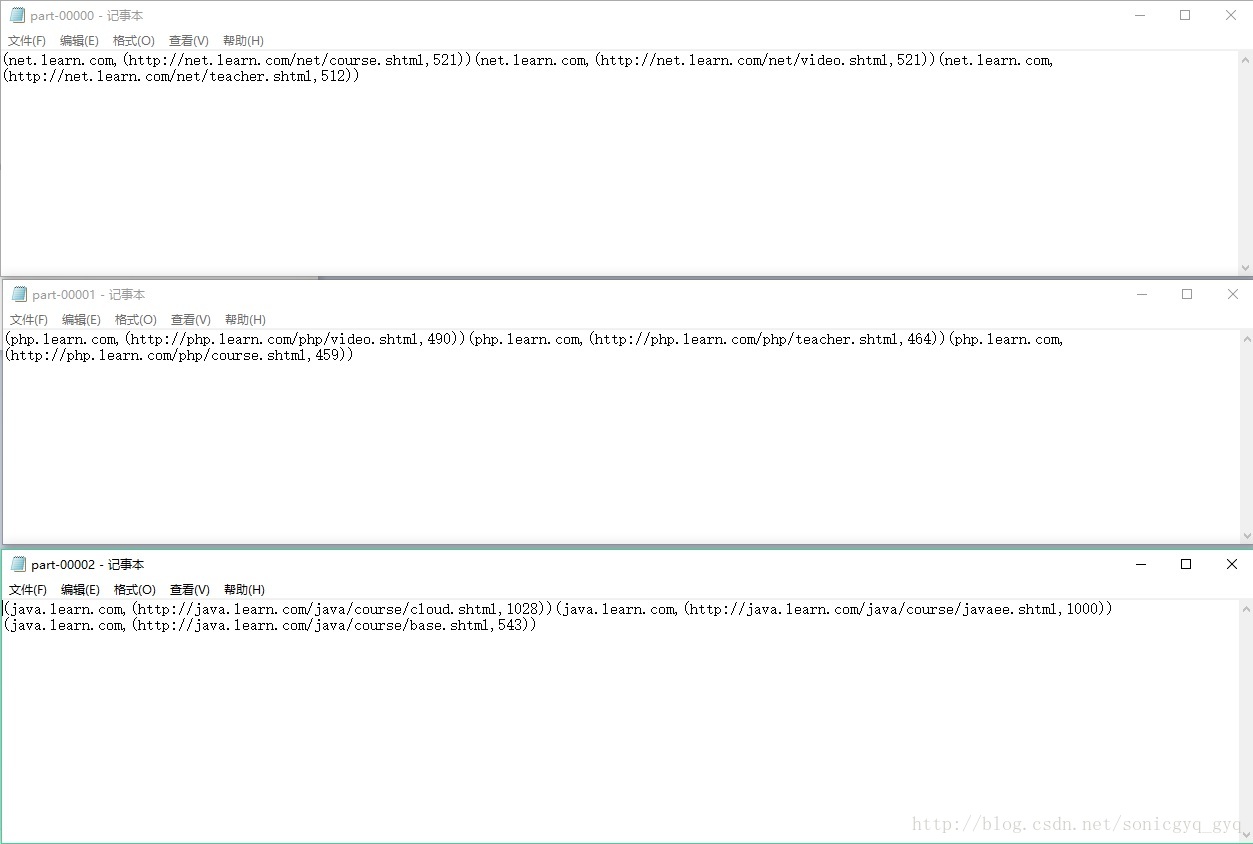
- res.saveAsTextFile("j://information//out1")
- sc.stop()
- }
- }
- package cn.allengao.Location
- import org.apache.spark.Partitioner
- import scala.collection.mutable
- classProjectPartitioner(projects: Array[String]) extendsPartitioner{
- //用來存放學科和分割槽號
- private val projectsAndPartNum = new mutable.HashMap[String,Int]()
- //計數器,用於指定分割槽號
- var n = 0
- for(pro<-projects){
- projectsAndPartNum += (pro -> n)
- n += 1
- }
- //得到分割槽數
- override def numPartitions = projects.length
- //得到分割槽號
- override def getPartition(key: Any) = {
- projectsAndPartNum.getOrElse(key.toString,0)
- }
- }