
【暖*墟】 #AC自動機# AC自動機的總結與運用
KMP:匹配單串,線性掃描,在失配時用next陣列引導j指標回溯,進行下一步匹配。
Trie樹:多模式的匹配,構造26叉樹,同時記錄多個串的情況,記錄結尾,進行匹配。
KMP + Trie樹 = AC自動機
AC自動機:給一個字典,再給一個文字,問這個文本里出現了字典裡的哪些字。
可以用n個單詞的n次KMP演算法來做 O(n*m*單詞平均長度),
也可以用1個Trie樹去匹配文字串的每個字母位置來做 O(m*每次字典樹遍歷的平均深度)。
在AC自動機中,我們首先將每個模式串插入到Trie樹中,建立一棵Trie樹,
然後構建 fail指標(匹配失敗時用來引導p指標回溯,插穿在Trie樹的各個節點之間的指標)。
類似KMP演算法中的next陣列,能在失配時跳轉到【具有最長公共前後綴】的字元繼續匹配。
如果跳轉,跳轉後的串的字首 必為 跳轉前的模式串的字尾(向上跳),
並且跳轉的新位置的深度(匹配字元個數)一定小於跳之前的節點。
一、AC自動機的構建步驟
1.將所有模式串構建成 Trie 樹。
2.對 Trie 上所有節點構建字首指標(類似kmp中的next陣列)
3.利用字首指標對主串進行匹配。
-
AC自動機關鍵點一:trie字典樹的構建過程
字典樹的構建過程是這樣的,當要插入許多單詞的時候,我們要從前往後遍歷整個字串,
當我們發現當前要插入的字元其節點再先前已經建成
當我們發現當前要插入的字元沒有再其前一個字元所形成的樹下沒有自己的節點,
我們就要建立一個新節點來表示這個字元,接下往下遍歷其他的字元。然後重複上述操作。
假設我們有下面的單詞,she , he ,say, her, shr ,我們要構建一棵字典樹。
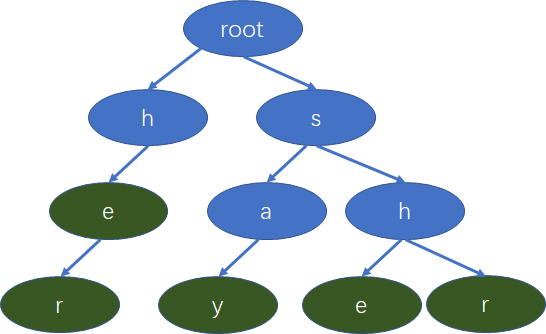
-
AC自動機關鍵點二:找Fail指標
在KMP演算法中,當我們比較到一個字元發現失配的時候我們會通過next陣列,
找到下一個開始匹配的位置,然後進行字串匹配,當然KMP演算法試用於單模式匹配。
所謂單模式匹配,就是給出一個模式串,給出一個文字串,尋找是否包含模式串。
AC自動機中,有fail指標,當發現失配的字元失配的時候,跳轉到fail指標指向的位置,
然後再次進行匹配操作,AC自動機之所以能實現多模式匹配,就歸功於fail指標的建立。
當前節點t有fail指標,其fail指標所指向的節點和t所代表的字元是相同的。
因為t匹配成功後,我們需要去匹配 t->child,發現失配,那麼就從t->fail開始再次匹配。
Fail指標的求法:BFS。直接與根節點相連的節點失配,他們的fail指標直接指向root。
其他節點的fail指標:假設當前節點為father,其孩子節點記為child。
求child的Fail指標時,首先我們要找到其father的Fail指標所指向的節點t,
看t的孩子中有沒有和child節點所表示的字母相同的節點,如果有、就是child的fail指標;
如果沒有,找father->fail->fail,重複過程,直到到達root(指向root)。
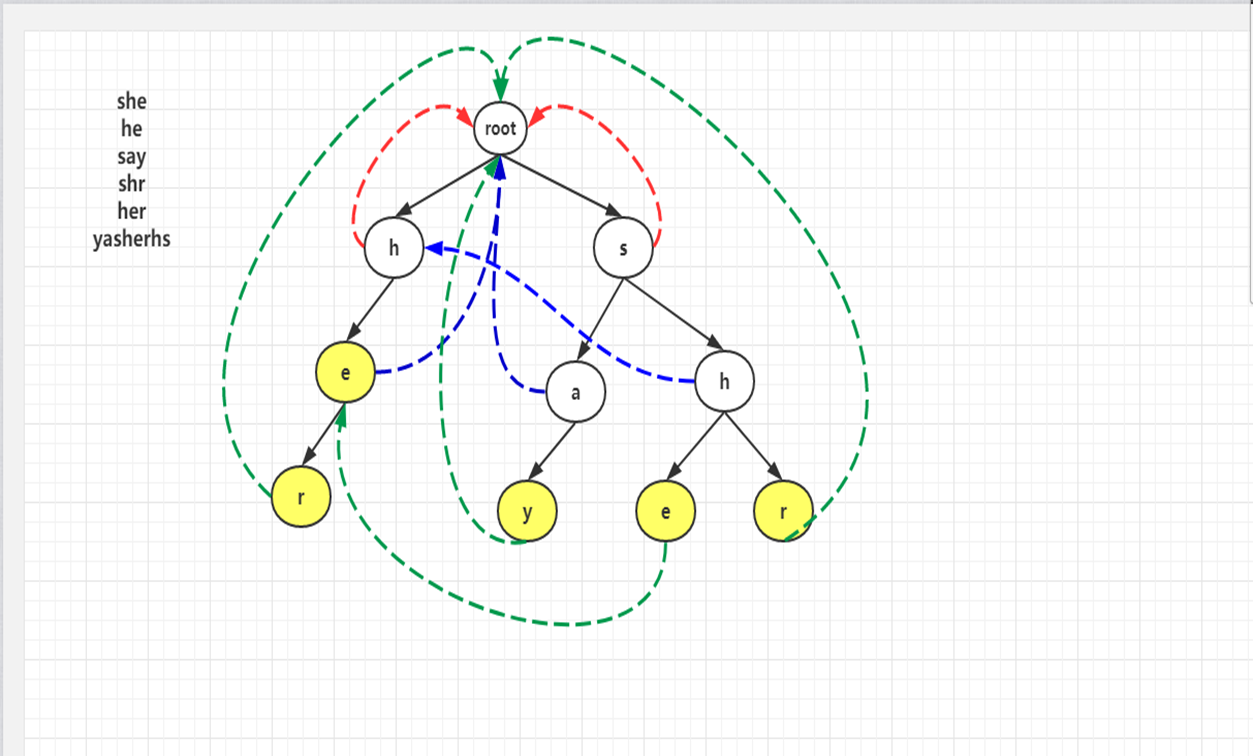
-
AC自動機關鍵點三:文字串的匹配
(1)當前字元匹配,表示從當前節點沿著樹邊有一條路徑可以到達目標字元,
如果當前匹配的字元是一個單詞的結尾,我們可以沿著當前字元的fail指標,一直遍歷到根,
如果這些節點末尾有標記(標記代表節點是一個單詞末尾),遍歷到的都是可以匹配上的節點。
統計完畢後標記。此時沿該路徑走向下一個節點繼續匹配,目標指標移向下個字元。
(2)當前字元不匹配,則去當前節點fail指標所指向的字元繼續匹配,直到指標指向root。
重複這2個過程中的任意一個,直到文字串走到結尾為止。
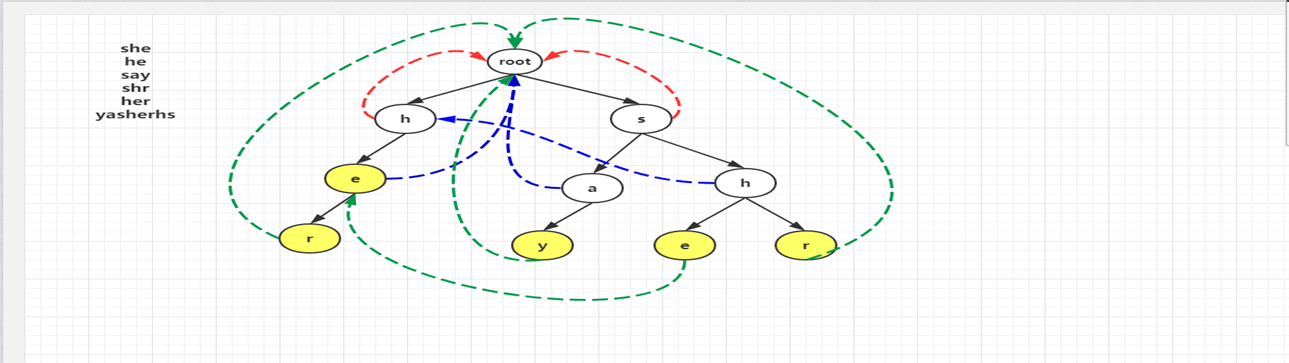
對照上圖,看一下模式匹配這個詳細的流程,其中文字串為 yasherhs(某文章)。
對於i=0,1,Trie 中沒有對應的路徑,故不做任何操作;
i=2,3,4時,指標p走到左下節點e。因為節點e的 count 資訊為1,所以cnt+1,
(到達某一個單詞的末尾,該資訊用bool tail [ ] 記錄,單詞數++)。
並且將節點e的 count 值設定為-1,表示該單詞已經出現過了,防止重複計數。
最後 temp 指向e節點的失敗指標所指向的節點繼續查詢。
以此類推,最後 temp 指向 root,退出 while 迴圈,這個過程中 count 增加了2。
表示找到了2個單詞she和he。當i=5時,程式進入第5行,p指向其失敗指標的節點,
也就是右邊那個e節點,隨後在第6行指向r節點,r節點的 count 值為1,
從而count+1,迴圈直到 temp 指向 root 為止。最後i=6,7時,找不到任何匹配,結束。
二、程式碼實現
- 構建Trie樹:
//trie字典樹: int tot=1,trie[maxn][26]; bool tail[maxn]; //串尾元素標記 void make_trie(char* s){ //insert int len=strlen(s),p=1; //p從根節點開始 for(int i=0;i<len;i++){ int ch=s[i]-'A'; //按照具體情況轉為數字 if(!trie[p][ch]) trie[p][ch]=++tot; //tot用於節點編號 p=trie[p][ch]; } tail[p]=true; //標記串尾元素 }
- fail指標的實現:(名稱用nextt陣列代替)
//fail指標:(名稱可以用nextt陣列代替) int nextt[maxn],que[maxn]; void bfs(){ for(int i=0;i<26;i++) trie[0][i]=1; //↑↑↑初始化:0的所有轉移邊都設為根節點為1 que[1]=1; nextt[1]=0; //que為廣搜佇列 for(int q1=1,q2=1;q1<=q2;q1++){ //q1,q2相當於head,tail int p=que[q1]; //佇列中head位置對應的節點編號 for(int i=0;i<26;i++){ //遍歷該編號能對應的所有字母 if(!trie[p][i]) trie[p][i]=trie[nextt[p]][i]; //↑↑↑若不存在trie[p][i],則沿p的字首指標走到第一個滿足存在的字元i轉移邊 //則會得到結點v=nextt[p],對應值就是trie[nextt[p]][i] else que[++q2]=trie[p][i], //trie[p][i]存在,存入隊尾 nextt[trie[p][i]]=trie[nextt[p]][i]; //記錄fail指標 } } } }
- 文字串的匹配:
//匹配是否存在: int find1(){ int p=1; for(int i=1;i<=m;i++){ p=trie[p][a[i]]; //向下層尋找匹配字元 if(tail[p]) return false; //匹配到返回0,否則返回1 } return true; } //文章匹配單詞數: void find2(char *s){ int p=1,len=strlen(s),c,k; for(int i=0;i<len;i++){ c=s[i]-'a'; k=trie[p][c];//p為層數(節點編號) while(k>1){ //可以匹配的到 && 不是根節點 ans+=tail[k]; //如果到達一處單詞結尾,ans+=1 tail[k]=0; //防止重複計數 k=nextt[k]; //返回上層的該元素出現位置,重新找 } p=trie[p][c]; //向下層尋找匹配字元編號 } }
——時間劃過風的軌跡,那個少年,還在等你。