
零基礎玩轉基礎圖片爬蟲【文件教程】
0. 寫在前面
1. 準備工作
- 安裝Python3
- 安裝requests庫,命令列 pip3 install requests
- 安裝lxml【需要解析xpath】,命令列 pip3 install lxml
測試下python3以及庫是否可用:

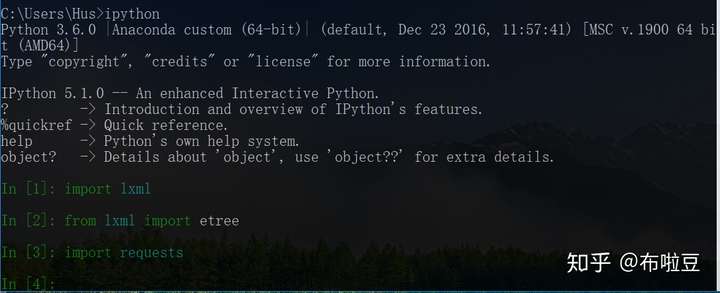
2. 分析目標網站
本次文件主要是對鬥圖啦網站進行抓取,下載圖片。
首先來分析下網站首頁
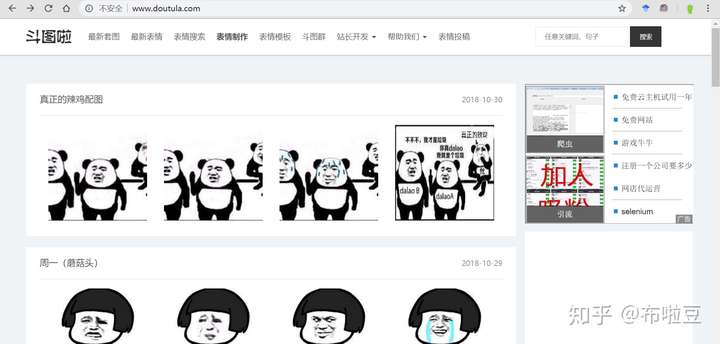

首頁這裡有不同的套圖,底部有個翻頁。點選不同的翻頁,看下效果...
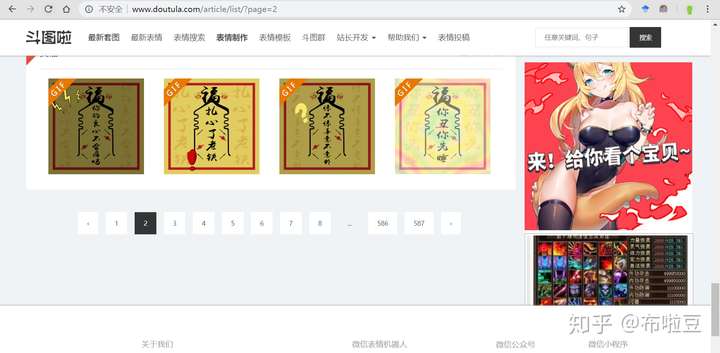
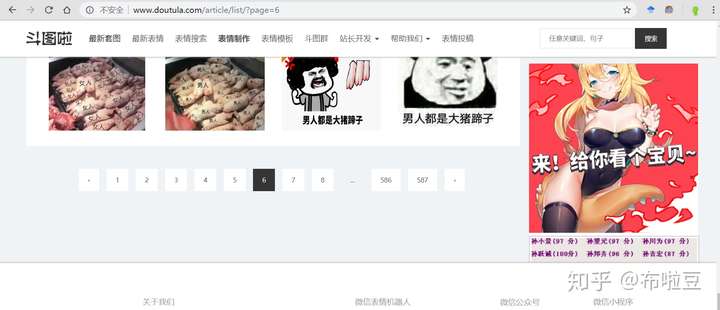
這裡貼出了第二頁和第六頁的截圖,url的規律是http://www.doutula.com/article/list/?page=頁碼
所以本次的目的,就是抓取該類url下的全部圖片並儲存本地
3. 獲取單頁的全部圖片
這裡以第二頁的網頁為例:
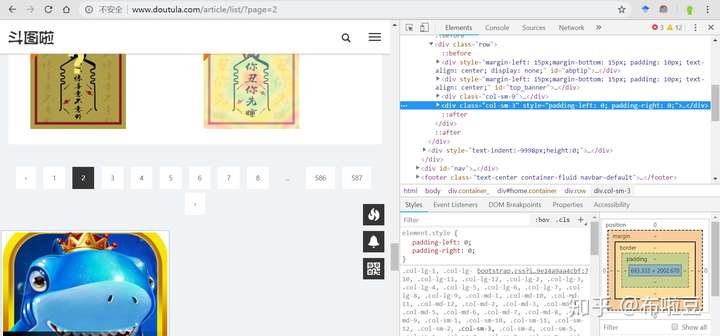
圖片的右側已經打開了除錯工具,且當前是Elements欄,看到class="col-sm-9"和class="col-sm-3",這個頁面是基於Bootstrap搭建的,肯定跑不了。
然後需要下載的圖片,全部在col-sm-9裡面,所以定位所需的圖片,就簡單了,然後就有了下面這張圖:
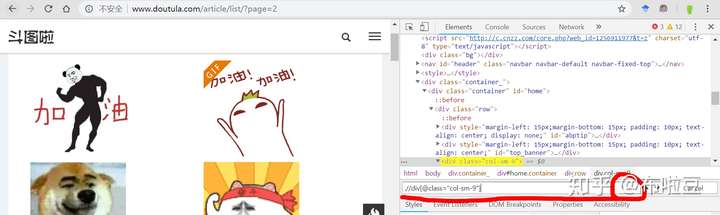
PS:在Elements欄開啟xpaht檢索框,按 ctrl+f 就會彈出框,支援字串、selector、xpath三種檢索方式。
這裡的檢索結果,只有一個,就是我們要的那個,太好了,接下來就開始獲取圖片的img標籤,然後提取它的屬性src即可。於是....
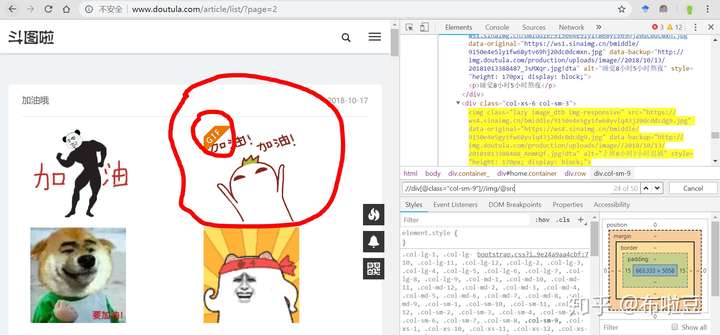
結果顯示有50個圖片,但是這個結果絕對是錯的,因為我數了,沒這麼多。然後我就自席間擦,發現gif標誌就是一個img的標籤圖,所以,這裡的xpath需要做判斷,只要大圖,不要gif圖。
於是,又有了下面這個圖:
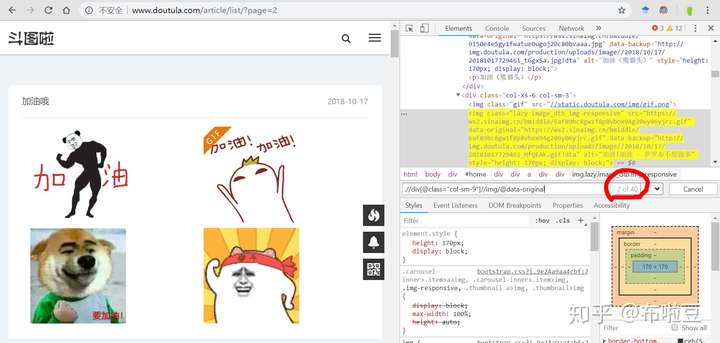
xpath規則,由.//div[@class="col-sm-9"]//img/@src變成了.//div[@class="col-sm-9"]//img/@data-original,為啥呀?原因有下:
- gif 的 img 標籤,沒有 data-original 屬性
- 正常圖片的img和data-original屬性,它們的值是完全一樣的
另外,特別重要的一點。有經驗的應該知道,data-original這個屬性的出現,肯定是該網頁使用了jQuery圖片延遲載入外掛jQuery.lazyload
lazy
到這,就正確的提取到了我們需要的40個圖片【我數了,4*10,正確無誤】,而且取出來的url,是包含了域名的,不需要做額外操作。
接下來就是寫程式碼了,貼個截圖,看下程式碼和效果:
import requests
from lxml import etree
url = 'http://www.doutula.com/article/list/?page=2'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
}
resp = requests.get(url,headers=headers)
html = etree.HTML(resp.text)
imgs = html.xpath('.//div[@class="col-sm-9"]//img/@data-original')
print(imgs,len(imgs))
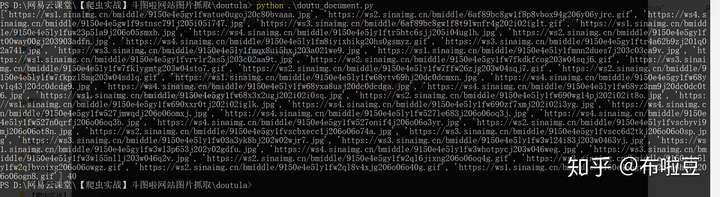
執行結果一切正常,這裡對程式碼做個簡短的說明:
- 匯入部分
- headers,這個是最好加的,請求一個網站,請求頭裡面的User-Agent是瀏覽器資訊,有這個就是模擬瀏覽器發出資訊了
html = etree.HTML(resp.text)解析純html字串,解析之後就可以使用xpath了imgs = html.xpath('.//div[@class="col-sm-9"]//img/@data-original')使用規則提取指定的資料,結果是列表格式;如果沒有資料就是空列表;- 最後將資料輸出,40個,正常。
單頁的圖片地址提取,到這就完成了。後面,我們來做圖片下載
4. 圖片下載
前面我們拿到了圖片的地址,有圖片地址就可以直接請求圖片並儲存本地了,很簡單。步驟如下:
- 首先,通過圖片地址,發起請求,拿到響應,響應的資料就是圖片了
- 然後,新建一個本地檔案,將響應資料寫到檔案上
邏輯是非常簡單的,下載圖片也是一個從url到本地檔案的過程,那就來封裝函式吧
先上程式碼:
def download_img(src):
filename = src.split('/')[-1] # 步驟1
img = requests.get(src, headers=headers) # 步驟2
# img是圖片響應,不能字串解析;
# img.content是圖片的位元組內容
with open('imgs/' + filename, 'wb') as file: # 步驟3
file.write(img.content) # 步驟4
print(src, filename) # 步驟5
程式碼比較簡潔,定義一個 download_img 函式,接收一個引數src,然後完成下載操作,這裡也來介紹下:
- 步驟一,從傳入的引數src裡面,提取圖片的名字。通常url經過 / 分割,最後一個字串就是圖片名。
- 對src發起請求,記住要帶上請求頭,就可以拿到響應,存入img。此時的img是http響應,響應資料是一張圖片,響應的頭部還有些資料。
- 步驟三是使用open函式,以二進位制寫的方式開啟一個檔案,然後寫入img.content。為什麼用二進位制?因為img.content是位元組。
- 另外,步驟三裡面,有個imgs/,需要在當前py檔案所在的目錄中,建立一個imgs的資料夾,程式執行前建立好。
- 輸出,其餘的沒啥
看下執行結果和圖片檔案截圖:

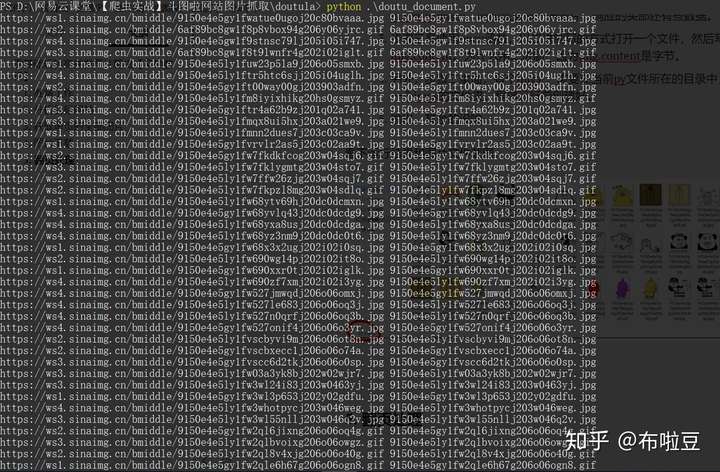
重要說明:雖然這裡沒有碰到坑,但是圖片請求和下載,一定會遇到一個Referer的坑。這個問題的來源,是雲託管服務中,在儲存圖片時,不希望別人網站拿去盜用,所以就設定一個“防跨域請求”的限制。
在請求圖片時,檢視下請求頭的Referer欄位【瀏覽器請求時,會把域名放上去】。如果是來自未設定網站的來源,則不返回圖片。所以請求圖片,推薦在請求頭中,加上Referer欄位,值就是域名
當前的完整程式碼部分:
import requests
from lxml import etree
url = 'http://www.doutula.com/article/list/?page=2'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
'Referer':'http://www.doutula.com/',
}
def download_img(src):
filename = src.split('/')[-1]
img = requests.get(src, headers=headers)
# img是圖片響應,不能字串解析;
# img.content是圖片的位元組內容
with open('imgs/' + filename, 'wb') as file:
file.write(img.content)
print(src, filename)
resp = requests.get(url,headers=headers)
html = etree.HTML(resp.text)
imgs = html.xpath('.//div[@class="col-sm-9"]//img/@data-original')
for img in imgs:
download_img(img)
5. 翻頁處理
翻頁這裡,也不難,但是涉及些知識點,所以這裡好好講講,多個方案對比看看。
第一種:函式遞迴
分析圖片的url以及翻頁,封裝一個函式,在函式裡面判斷下一頁,有則呼叫自身。程式碼會很簡單,且思路清晰。
第二種:迴圈拼接URL
這種方式,適合有規則的url,找到規律,迴圈操作,並且可以預判最後一個url,方便停止。迴圈就是翻頁的過程,簡單。
第三種:函式返回URL
基於 【1 + 3】 思路,首先一個死迴圈,迴圈內呼叫函式,處理第一個url。函式在處理了圖片url和翻頁的時候,這時返回下一頁的url。迴圈收到了函式的返回值,判斷有沒有下一頁?有,繼續呼叫函式;沒有,停止迴圈。這樣就不構成遞迴,而是簡單的迴圈。
第四種:生成器
基於思路【3】,函式返回,return即可;如果你將return改成yield,就成了生成器,用法基本和思路【3】一致。
不考慮實際情況,再多思路都是扯淡,所以這裡還是先上截圖,看下鬥圖啦網站的翻頁是怎麼樣的。
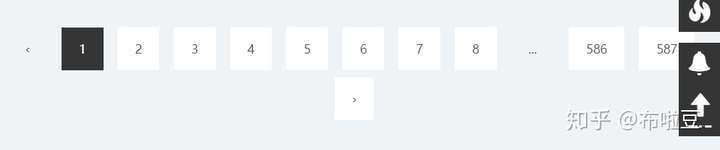

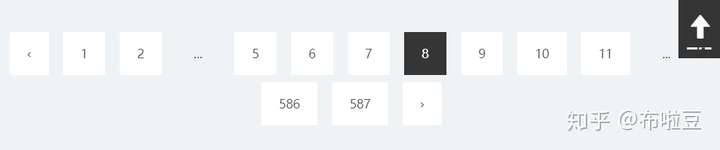

上面貼了三張圖,分別是 1 - 2 - 8 - 587 三頁。
從圖中可以看出,第二頁沒有 9 和 10 頁,第八頁有 9 和 10 、 11頁。也就是說到了某一頁,對應的前後三頁的資料都是展示【除了沒有的】。
然後看到第一頁和最後一頁,第一頁中往前翻的箭頭是無法點選的;最後一頁中往後翻的箭頭是無法點選的。
所以,有以下幾個方案可以做:
- 獲取翻頁的最大數值,走思路【2】的方案,迴圈拼接URL
- 獲取翻頁的全部URL,逐個請求並分析下次所得的URL,做個篩查,請求過的URL不在請求。思路【4】
- 針對不是最後一頁就有下一頁翻頁的思想,做函式的遞迴呼叫。思路【1】,總共587
- 針對不是最後一頁就有下一頁翻頁的思想,做函式返回URL的方案。思路【3】
- 判斷是否有圖片,有圖片則表示可能有下一頁,繼續請求,用圖片來判斷是否坐下一頁的請求,思路【2】
- 等等,方法挺多的....
方法這麼多,選一個簡單且可行的,第5個方法。
為什麼選第5個?因為:數字遞增且URL容易拼接,每頁都需要對圖片進行解析,操作方便。迴圈+函式返回的操作,是Python的基本操作,要求低。
有思路有方法,那擼起袖子開始幹了....
首先是封裝函式函式,在解析圖片的基礎之上,判斷圖片的資料:如果有返回True;沒有返回False;很簡單,上函式程式碼:
def parse_page(url):
resp = requests.get(url,headers=headers)
html = etree.HTML(resp.text)
imgs = html.xpath('.//div[@class="col-sm-9"]//img/@data-original')
if imgs:
return True
else:
return False
有這個函式,那下面就是寫個迴圈邏輯,對該函式進行呼叫並一直判斷函式返回值,再遞增數字,拼接URL,在呼叫函數了,整體程式碼如下:
import requests
from lxml import etree
from time import sleep
url = 'http://www.doutula.com/article/list/?page=2'
headers = {
'Referer':'http://www.doutula.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
}
def parse_page(url):
resp = requests.get(url,headers=headers)
html = etree.HTML(resp.text)
imgs = html.xpath('.//div[@class="col-sm-9"]//img/@data-original')
if imgs:
return True
else:
return False
base_url = 'http://www.doutula.com/article/list/?page={}'
i = 1
next_link = True
while next_link:
next_link = parse_page(base_url.format(i))
if next_link :
i += 1
else:
break
print(i)
print('~OVER~')
程式碼中,首先定義幾個值,用於拼接的base_url,迴圈用的i,以及下一頁判斷引數next_link。
在函式返回值為True是,i加1,同時while迴圈成立,繼續呼叫函式;否則break,跳出迴圈。
測試結果:

怎麼只有145頁?因為145頁是個錯誤頁面,跳過就好,來看下145頁的介面:
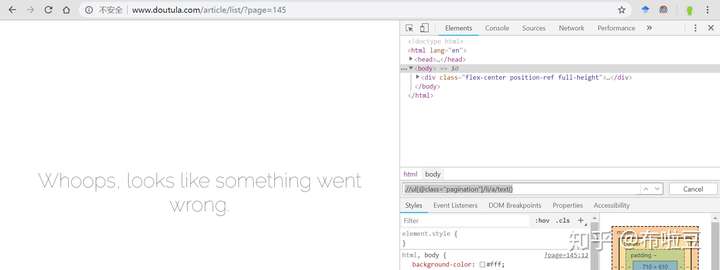
所以程式碼稍微帶動下,在i等於145 時再做個增加,跳過它。
不過,很快,我意識到了這是一個錯誤的思路。既然145頁會錯,後面還有400多頁,肯定還有錯誤的頁面,於是我就測試一下,錯誤頁面有這些:
145,246, 250, 344, 470, 471, 563, 565, 589, 590, 591, 592
所以,在不知道哪些是錯誤頁面的前提是,不能隨便給數字做加法,然後就有了另一個思路:
- 錯誤的數字,不會連著出現,最多出現一次
- 末尾的幾頁,不會報錯,直接出現無效,也就是末尾會出現連續的無圖片
所以,邏輯上就可以做連錯處理。如果連續出現三次無頁面,跳出迴圈,如果僅僅是一次、兩次,跳過,繼續往下爬。
上邏輯部分程式碼:
base_url = 'http://www.doutula.com/article/list/?page={}'
i = 1
error_time = 0
next_link = True
while next_link:
next_link = parse_page(base_url.format(i))
if next_link :
i += 1
error_time = 0
else:
if error_time>=3:
print(error_time,'break')
break
i+=1
error_time+=1
next_link = True
print(i,error_time)
print('~OVER~')
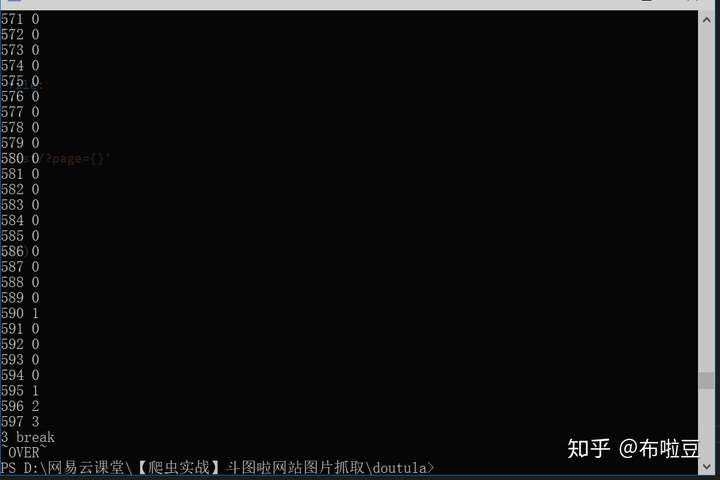
上執行結果截圖【測試多次,結果會有差異】:
6. 總結
到這,翻頁就完成了。加上前面的圖片URL解析、圖片下載、翻頁處理,一個簡單的圖片爬蟲就完成了。
不過呢,要加異常處理,否則一個錯誤終止整個程式,後續都沒得玩了
貼下完成程式碼,以及執行結果圖:
import requests
from lxml import etree
from time import sleep
url = 'http://www.doutula.com/article/list/?page=2'
headers = {
'Referer':'http://www.doutula.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36',
}
def parse_page(url):
resp = requests.get(url,headers=headers)
html = etree.HTML(resp.text)
imgs = html.xpath('.//div[@class="col-sm-9"]//img/@data-original')
for img in imgs:
try:
download_img(img)
except:
pass
if imgs:
return True
else:
return False
def download_img(src):
filename = src.split('/')[-1]
img = requests.get(src, headers=headers)
# img是圖片響應,不能字串解析;
# img.content是圖片的位元組內容
with open('imgs/' + filename, 'wb') as file:
file.write(img.content)
print(src, filename)
base_url = 'http://www.doutula.com/article/list/?page={}'
i = 1
error_time = 0
next_link = True
while next_link:
sleep(0.5)
try:
next_link = parse_page(base_url.format(i))
except:
next_link = True
if next_link :
i += 1
error_time = 0
else:
if error_time>=3:
print(error_time,'break')
break
i+=1
error_time+=1
next_link = True
print(i,error_time)
print('~OVER~')
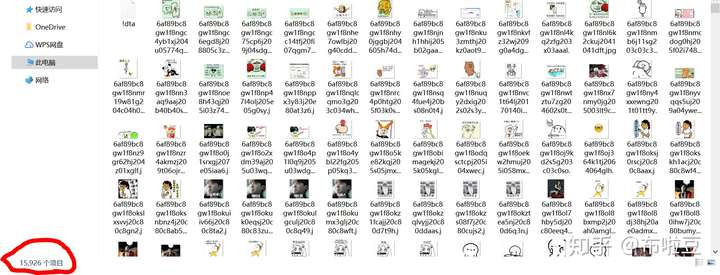
截圖是,下載15926張圖片,但是程式依舊在執行,也就是說....圖片還更多。
你們拿到爬蟲程式碼後,可以自己去執行,記得建立一個imgs資料夾,慢慢下載喲