
使用3臺虛擬機器搭建Hadoop HA叢集(2)
系列部落格目錄連結:Hadoop權威指南學習筆記:總章
基礎環境搭建:使用3臺虛擬機器搭建Hadoop HA叢集(1)
HA環境搭建:使用3臺虛擬機器搭建Hadoop HA叢集(2)
本部分包含以下基本分內容
- 安裝部署zookeeper
- 安裝部署Hadoop相關元件
一. 部署zookeeper
1. zooKeeper 軟體安裝須知
鑑於 ZooKeeper 本身的特點,伺服器叢集的節點數推薦設定為奇數臺。按照計劃,此處規劃三臺。
2. zookeeper下載
操作節點:cloud2
官方下載連結如下:
3. 解壓檔案
操作節點:cloud2
tar -zxvf zookeeper-3.4.8.tar.gz
mv zookeeper-3.4.8 /home/hadoop/apps
cd /home/hadoop/apps
ln -s zookeeper-3.4.8 zookeeper
此處我將解壓後的zookeeper資料夾統一放置於/home/hadoop/apps下,Hadoop同此,下面不再解釋。
4. 編輯配置檔案
操作節點:cloud2
[email protected]:~/apps$ cd zookeeper/conf
[email protected]:~/apps/zookeeper/conf$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[email protected]:~/apps/zookeeper/conf$ cp zoo_sample.cfg zoo.cfg
原始配置檔案內包含以下四個配置,進行以下簡要說明:
- tickTime:心跳基本時間單位,毫秒級,ZK基本上所有的時間都是這個時間的整數倍。
- initLimit:tickTime的個數,表示在leader選舉結束後,followers與leader同步需要的時間,如果followers比較多或者說leader的資料非常大多時,同步時間相應可能會增加,那麼這個值也需要相應增加。
- syncLimit:tickTime的個數,這時間容易和上面的時間混淆,它也表示follower和observer與leader互動時的最大等待時間,只不過是在與leader同步完畢之後,進入正常請求轉發或ping等訊息互動時的超時時間。
- dataDir:記憶體資料庫快照存放地址,如果沒有指定事務日誌存放地址(dataLogDir),預設也是存放在這個路徑下,建議兩個地址分開存放到不同的裝置上。
- clientPort:配置ZK監聽客戶端連線的埠
我們需要做的包含兩項
a. 修改dataDir目錄位置,我此處指定為/home/hadoop/data/zookeeper/data
b. 檔案末尾追加:
dataLogDir=/home/hadoop/data/zookeeper/log
server.1=a.cloud.ha:2888:3888
server.2=b.cloud.ha:2888:3888
server.3=c.cloud.ha:2888:3888
其中dataLogDir為日誌檔案位置,後者格式如下:
server.serverid=host:tickpot:electionport
server:固定寫法
serverid:每個伺服器的指定ID(必須處於1-255之間,必須每一臺機器不能重複)
host:主機名
tickpot:心跳通訊埠
electionport:選舉埠
5. 分發檔案
操作節點:cloud1、cloud2、cloud3
將cloud2配置好的zookeeper檔案傳送至cloud1和cloud3,然後分別在對應節點建立資料目錄及日誌目錄。步驟不再重複。
分發完檔案後,我們需要在資料資料夾下建立一個名為myid的檔案,內容為當前節點對應得serverid,如下圖:

6. 配置環境變數
操作節點 cloud1、cloud2、cloud3
sudo vim /etc/profile
文末新增
export ZOOKEEPER_HOME=/home/hadoop/apps/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
載入環境變數
source /etc/profile
至此,zookeeper叢集配置完成
二. 部署Hadoop
1. Hadoop的下載及安裝
操作節點:cloud1
Hadoop各版本官方下載連結:https://archive.apache.org/dist/hadoop/common/,請選擇合適的版本下載。本叢集統一採用Hadoop-2.6.5版本。
2. 解壓及建立連線檔案
操作節點:cloud1
將下載後的壓縮檔案移到/home/hadoop/apps/目錄下,執行解壓命令:
cd /home/hadoop/apps/
tar -zxvf hadoop-2.6.5.tar.gz
建立連線檔案:
ln -s hadoop-2.6.5 hadoop
3. 配置hadoop
操作節點:cloud1
hadoop的配置檔案預設位於hadoop安裝目錄的etc/hadoop目錄下,本例為/home/hadoop/apps/hadoop/etc/hadoop。
a. 修改hadoop-env.sh
[email protected]:~/apps/hadoop/etc/hadoop$ echo $JAVA_HOME
/usr/java/jdk
[email protected]:~/apps/hadoop/etc/hadoop$ vim hadoop-env.sh

b. 修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice為mycloud -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycloud/</value>
</property>
<!-- 指定hadoop臨時目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>a.cloud.ha:2181,b.cloud.ha:2181,c.cloud.ha:2181</value>
</property>
<!-- hadoop連結zookeeper的超時時長設定 -->
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>1000</value>
<description>ms</description>
</property>
</configuration>
c. 配置hdfs-site.xml。按照計劃,namenode配置在域名為a.cloud.ha和b.cloud.ha兩臺節點上。配置中設計到的相關目錄需要自己根據自己情況建立。
<configuration>
<!-- 指定副本數 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 配置namenode和datanode的工作目錄-資料儲存目錄 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/data/hadoop/hdfs/data</value>
</property>
<!-- 啟用webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定hdfs的nameservice為mycloud,需要和core-site.xml中的保持一致,
dfs.ha.namenodes.[nameservice id]為在nameservice中的每一個NameNode設定唯一標示符。
配置一個逗號分隔的NameNode ID列表。這將是被DataNode識別為所有的NameNode。
例如,如果使用"myha01"作為nameservice ID,並且使用"nn1"和"nn2"作為NameNodes標示符
-->
<property>
<name>dfs.nameservices</name>
<value>mycloud</value>
</property>
<!-- myha01下面有兩個NameNode,分別是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycloud</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通訊地址 -->
<property>
<name>dfs.namenode.rpc-address.mycloud.nn1</name>
<value>a.cloud.ha:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycloud.nn1</name>
<value>a.cloud.ha:50070</value>
</property>
<!-- nn2的RPC通訊地址 -->
<property>
<name>dfs.namenode.rpc-address.mycloud.nn2</name>
<value>b.cloud.ha:9000</value>
</property>
<!-- nn2的http通訊地址 -->
<property>
<name>dfs.namenode.http-address.mycloud.nn2</name>
<value>b.cloud.ha:50070</value>
</property>
<!-- 指定NameNode的edits元資料的共享儲存位置。也就是JournalNode列表
該url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId
journalId推薦使用nameservice,預設埠號是:8485 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://a.cloud.ha:8485;b.cloud.ha:8485;c.cloud.ha:8485/mycloud</value>
</property>
<!-- 指定JournalNode在本地磁碟存放資料的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/hadoop/journal/data</value>
</property>
<!-- 開啟NameNode失敗自動切換 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失敗自動切換實現方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycloud</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔離機制方法,多個機制用換行分割,即每個機制暫用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔離機制時需要ssh免登陸 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔離機制超時時間 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
</configuration>
d. 修改mapred-site.xml
[email protected]:~/apps/hadoop/etc/hadoop$ cp mapred-site.xml.template mapred-site.xml
[email protected]:~/apps/hadoop/etc/hadoop$ vim mapred-site.xml
<configuration>
<!-- 指定mr框架為yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定mapreduce jobhistory地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>a.cloud.ha:10020</value>
</property>
<!-- 任務歷史伺服器的web地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>a.cloud.ha:19888</value>
</property>
</configuration>
e. 修改yarn-site.xml。按照計劃,ResourceManager配置在域名為a.cloud.ha和b.cloud.ha兩臺節點上。
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 開啟RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分別指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>b.cloud.ha</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>c.cloud.ha</value>
</property>
<!-- 指定zk叢集地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>a.cloud.ha:2181,b.cloud.ha:2181,c.cloud.ha:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 啟用自動恢復 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的狀態資訊儲存在zookeeper叢集上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
f. 修改slave。按照計劃,在域名為b.cloud.ha,c.cloud.ha的兩臺節點部署namenode和nodemanager。
b.cloud.ha
c.cloud.ha
g. 分發檔案。此處將整個hadoop資料夾分發到剩餘兩臺節點。所有節點hadoop資料夾皆在/home/hadoop/apps/目錄下。
4. 配置環境變數
操作節點:cloud1、cloud2、cloud3
在/etc/profile末尾追加:
export HADOOP_HOME=/home/hadoop/apps/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
載入環境變數
source /etc/profile
執行hadoop version驗證環境變數配置,無異常表示配置完成
三. 初始化hadoop叢集
請務必按步驟依次操作,需要在兩個及以上節點操作的,一定要在所有節點操作進行完成後,再繼續下一個步驟,否則會產生不可預知錯誤。
1. 初始化zookeeper叢集
操作節點:cloud1、cloud2、cloud3
依次在所有節點手動執行zkServer.sh start來啟動zookeeper節點。使用zkServer.sh status和jps命令檢視啟動狀態。

2. 初始化journalNode
操作節點:cloud1、cloud2、cloud3
按照計劃,我們會在所有節點啟動journalNode,因此以下命令需要在三臺節點分別執行。
hadoop-daemon.sh start journalnode
同理執行jps檢視。
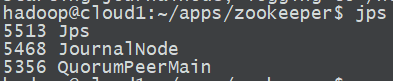
3. 格式化NameNode
操作節點:cloud1或cloud2
按照計劃,我們會在cloud1和cloud2啟動一主一備NameNode,任一節點操作即可。此處選用cloud1
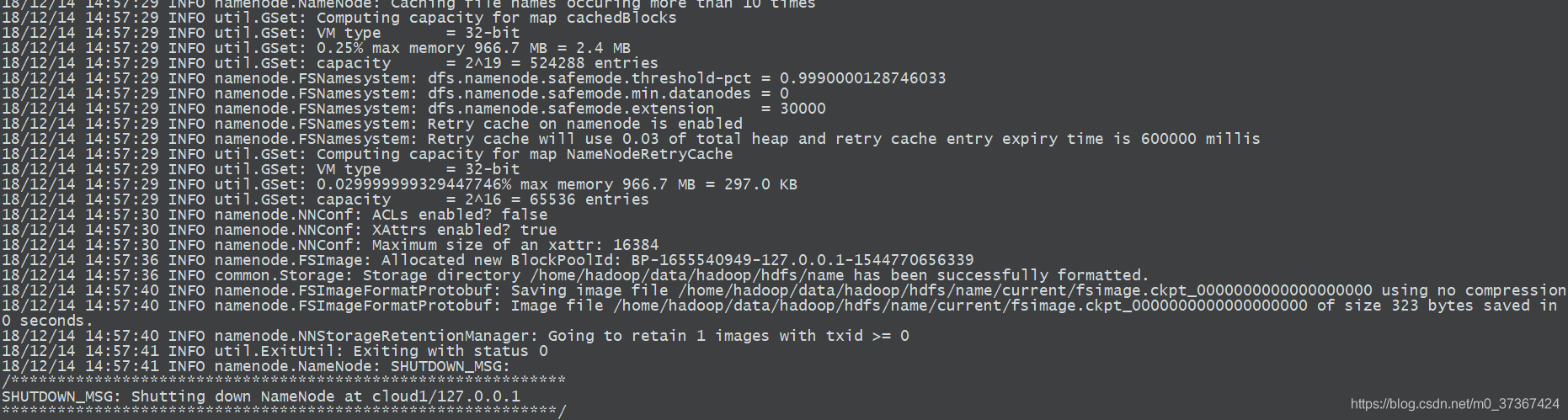
hadoop namenode -format
如圖表示格式化完成。
4. 複製元資料
第三步在cloud1進行了NameNode格式化,之後我們需要將該節點生成的元資料複製到cloud2,因為cloud2為另一臺NameNode。
元資料儲存位置在hadoop的配置檔案hdfs-site.xml–>dfs.namenode.name.dir項中定義,此處為/home/hadoop/data/hadoop/hdfs/name。
我們需要將該資料夾整體複製到cloud2相同位置。需要注意的是,下面的scp -r後的路徑名後面沒有/。
[email protected]:~/data/hadoop/hdfs$ tree
.
├── data
└── name
└── current
├── fsimage_0000000000000000000
├── fsimage_0000000000000000000.md5
├── seen_txid
└── VERSION
3 directories, 4 files
[email protected]:~/data/hadoop/hdfs$ scp -r name [email protected]:`pwd`
fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
fsimage_0000000000000000000 100% 323 0.3KB/s 00:00
VERSION
5. 格式化zkfc並啟動zkfc
操作節點:cloud1、cloud2
按照計劃,zkfc在cloud1、cloud2執行。事實上,zkfc也只能在NameNode上執行。啟動之前,我們需要首先格式化zkfc。
a. 格式化zkfc,在任一NameNode節點操作即可。
hdfs zkfc -formatZK
b. 啟動zkfc,此步驟需要在兩個NameNode操作。
hadoop-daemon.sh start zkfc
啟動完成後,使用jps命令應該可以看到DFSZKFailoverController程序。
四. 啟動叢集
1. 啟動HDFS和Yarn
操作節點:cloud2
在cloud2執行以下命令啟動HDFS及Yarn。啟動相應服務需要在相應服務的主節點上啟動。因為ResourceManager和Namenode在cloud2上皆有服務,故在cloud2啟動
start-dfs.sh;start-yarn.sh
2. 啟動MapReduce歷史作業伺服器
操作節點:cloud1
mr-jobhistory-daemon.sh start historyserver
3. 檢查
操作節點:任一節點即可
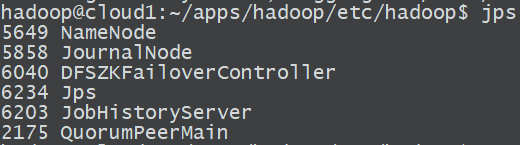
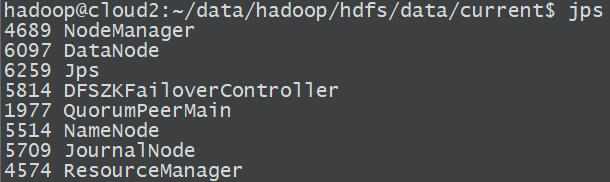
a. 經過以上所有步驟之後,各個節點包含的服務應該如下圖:分別與計劃中規劃的服務對應
- cloud1
- cloud2
- cloud3
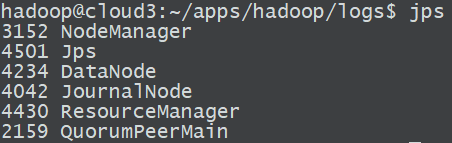
對於任意節點沒有起來的程序,可通過hadoop-daemon.sh啟動HDFS系列元件或通過yarn-daemon.sh啟動Yarn相關元件,但啟動之前應該首先將錯誤排除。
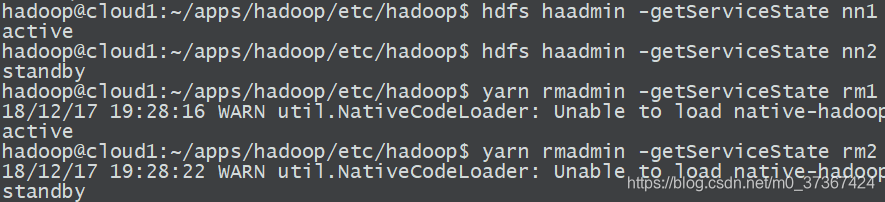
b. 命令列檢查主服務節點狀態:
[email protected]:~/apps/hadoop/etc/hadoop$ hdfs haadmin -getServiceState nn1
active
[email protected]:~/apps/hadoop/etc/hadoop$ hdfs haadmin -getServiceState nn2
standby
[email protected]:~/apps/hadoop/etc/hadoop$ yarn rmadmin -getServiceState rm1
18/12/17 19:28:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active
[email protected]:~/apps/hadoop/etc/hadoop$ yarn rmadmin -getServiceState rm2
18/12/17 19:28:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
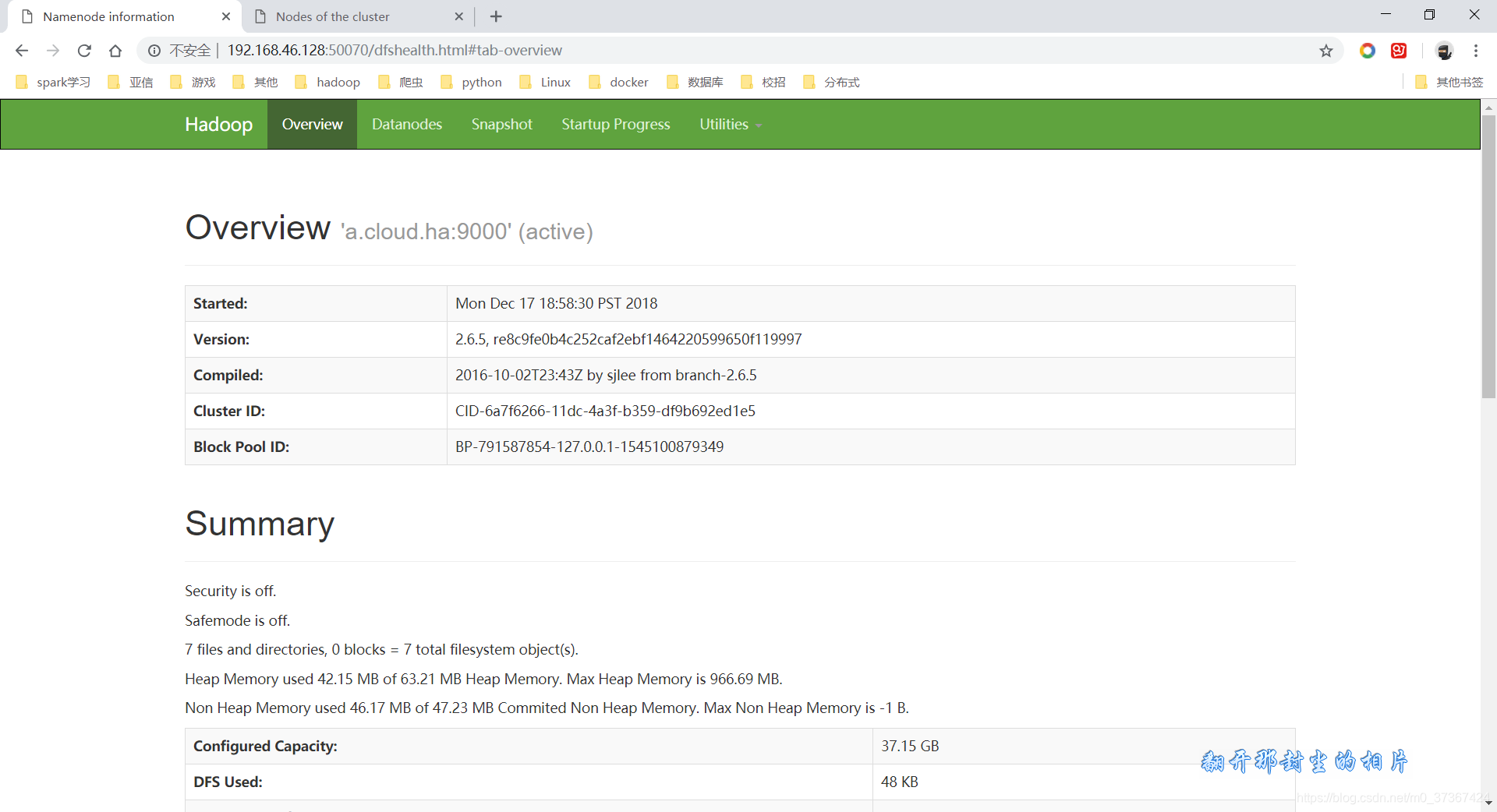
c. 網頁端檢查
- HDFS
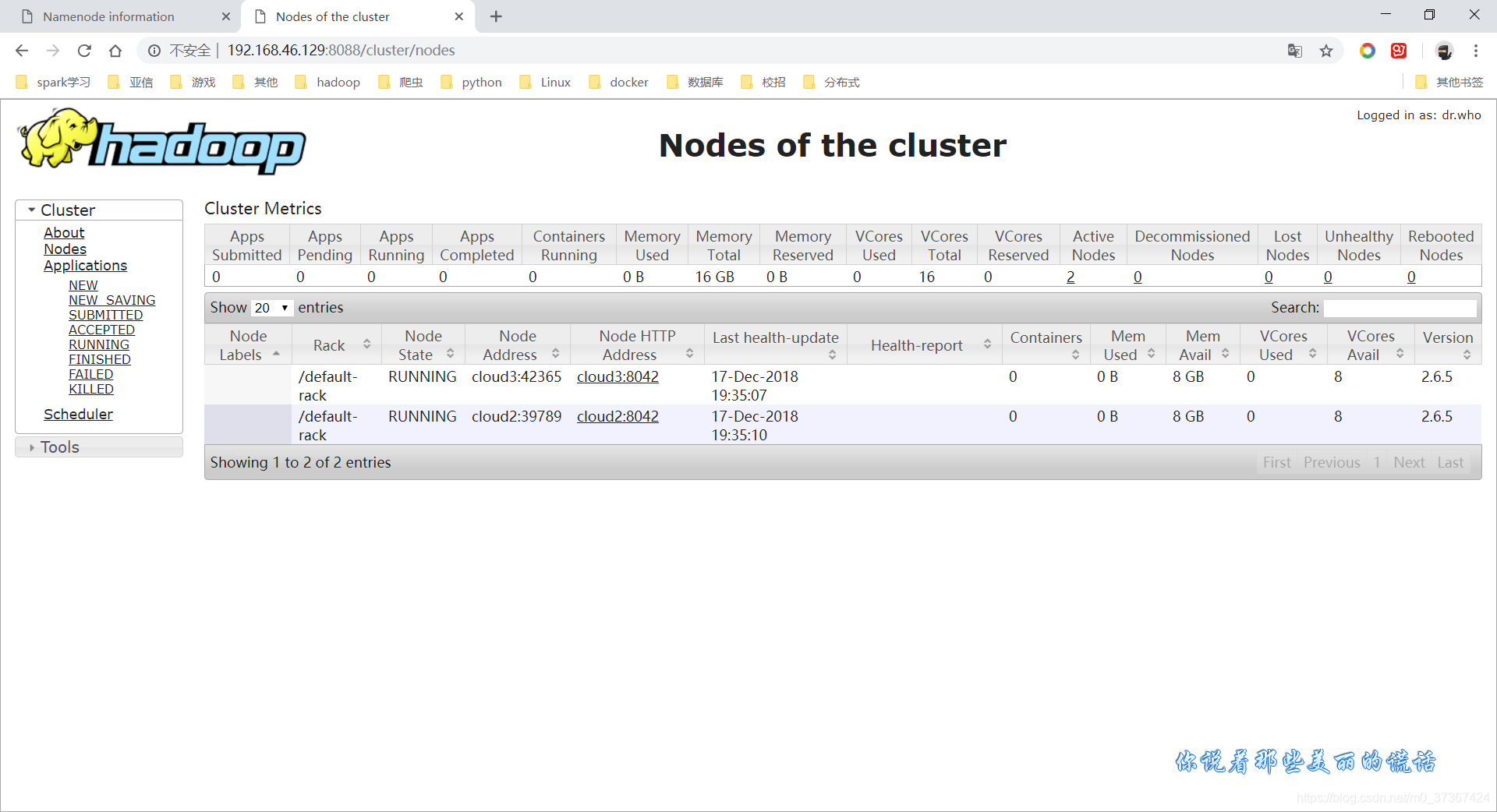
- YARN
至此,HA叢集搭建完畢。關於叢集的kill測試,可以根據以下幾方面測試,此處不再敘述。
- 叢集空閒時kill掉任意一臺NM,測試檔案寫入
- 寫入大檔案時,kill掉任意一臺NM,檢視檔案是否丟失
- 任務執行時,kill掉任意一臺RM,檢視任務是否失敗
- 無任務執行時,kill掉任意一臺RM,檢視任務能否提交