
大資料基礎環境之kafka(3臺虛擬機器)
Kafka叢集:
首先,下載解壓壓縮包 kafka_2.11-2.0.0.tgz
到 /usr/kafka/
配置/usr/kafka/kafka_2.11-2.0.0/config/server.properties檔案:
開啟監聽埠(開啟這一行註釋):
![]()
修改zookeeper.connect:
![]()
配置 broker 的ID:
![]()
修改 log 的目錄:
![]()
然後就配置完成了
接著使用遠端複製將/usr/下的kafka目錄分發到其他節點
之後進入其他節點的server.properties檔案修改如:
![]()
其他節點的broker.id=2 ....依次遞增就好。
然後在每個節點上啟動kafka命令如下:
![]()
/usr/kafka/kafka_2.11-2.0.0/bin/kafka-server-start.sh /usr/kafka/kafka_2.11-2.0.0/config/server.properties &
建立topic(命令):
kafka-topics.sh --create --zookeeper spark1:2181,spark2:2181,spark3:2181 --replication-factor 3 --partitions 3 --topic xxx (rf引數副本數,par引數分割槽數,xxx是topic的名稱)建立topic
檢視topic(命令):
/usr/kafka/kafka_2.11-2.0.0/bin/kafka-topics.sh -list --zookeeper spark1:2181,spark2:2181,spark3:2181
測試kafka是否可用:
建立生產者(在kafka的根目錄下執行):
bin/kafka-console-producer.sh --broker-list spark1:9092,spark2:9092,spark3:9092 --topic test
建立消費者:
bin/kafka-console-consumer.sh --bootstrap-server spark1:9092 --topic test --from-beginning
生產者中輸入訊息:
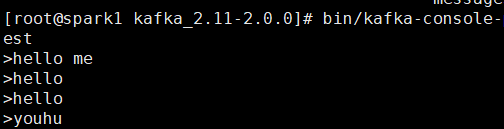
消費者實時接收訊息:
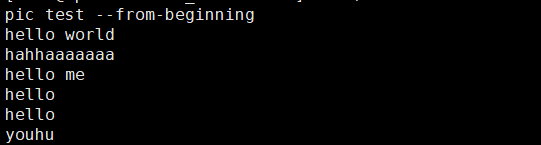
完成測試