
機器學習 - 正則化方法:L1和L2 regularization、資料集擴增、dropout
正則化方法:防止過擬合,提高泛化能力
常用的正則化方法有:L1正則化;L2正則化;資料集擴增;Droupout方法
(1) L1正則化
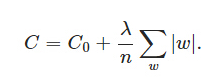
(2) L2正則化
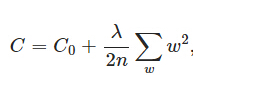
(3) Droupout
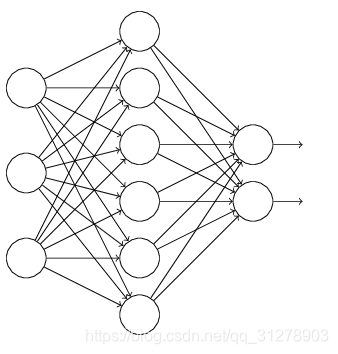
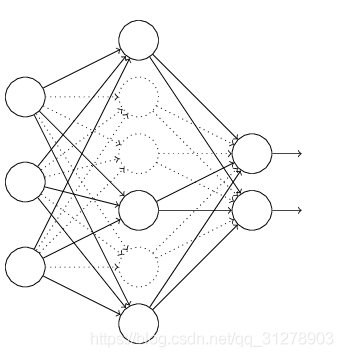
【參考】https://blog.csdn.net/u012162613/article/details/44261657
相關推薦
機器學習 - 正則化方法:L1和L2 regularization、資料集擴增、dropout
正則化方法:防止過擬合,提高泛化能力 常用的正則化方法有:L1正則化;L2正則化;資料集擴增;Droupout方法 (1) L1正則化 (2) L2正則化 (3) Droupout 【參考】https://blog.cs
正則化方法:L1和L2 regularization、資料集擴增、dropout
正則化方法:防止過擬合,提高泛化能力 在訓練資料不夠多時,或者overtraining時,經常會導致overfitting(過擬合)。其直觀的表現例如以下圖所看到的。隨著訓練過程的進行,模型複雜度新增,在training data上的error漸漸減小。可是在驗證集上的error卻反而漸漸增
【深度學習理論】正則化方法:L1、L2、資料擴增、Dropout
正則化 在訓練資料不夠多時,或者過度訓練時,常常會導致overfitting(過擬合)。隨著訓練過程的進行,模型複雜度增加,在train data上的error漸漸減小,但是在驗證集上的err
[機器學習]正則化方法 -- Regularization
首先了解一下正則性(regularity),正則性衡量了函式光滑的程度,正則性越高,函式越光滑。(光滑衡量了函式的可導性,如果一個函式是光滑函式,則該函式無窮可導,即任意n階可導)。 機器學習中幾乎都可以看到損失函式後面會新增一個額外項,常用的額外
正則化方法/防止過擬合提高泛化能力的方法:L1和L2 regularization、資料集擴增、dropout
正則化方法:防止過擬合,提高泛化能力 在訓練資料不夠多時,或者overtraining時,常常會導致overfitting(過擬合)。其直觀的表現如下圖所示,隨著訓練過程的進行,模型複雜度增加,在training data上的error漸漸減小,但是在驗證集上的e
機器學習——正則化-L2
學了線性迴歸和邏輯迴歸後不得不提一下正則化 正則化是解決過擬合問題,是機器學習演算法中為防止資料過擬合而採取的“懲罰”措施。 擬合:通俗的講就是貼近的關係,擬合的三種狀態,欠擬合(貼的不夠緊),just right(剛剛好,恰到好處),過擬合(貼的太緊,以至於很容易出錯,不能泛化) 故事: 校服的故事
機器學習正則化
正則化項可以是模型引數向量的範數 首先,範數是指推廣到高維空間中的模,給定向量x=(x1,x2,x3,...,xn),常用的向量的範數如下: L0範數:向量非零元素的個數 L1範數:向量各個元素絕對值之和 ,也被稱為“稀疏規則運算元” L2範數:向量各個元素的平方和然
深度學習:正則化方法
正則化是機器學習中非常重要並且非常有效的減少泛華誤差的技術,特別是在深度學習模型中,由於其模型引數非常多非常容易產生過擬合。因此研究者也提出很多有效的技術防止過擬合,比較常用的技術包括: 引數新增約束,例如L1、L2範數等訓練集合擴充,例如新增噪聲、資料變換等D
機器學習:正則化
Coursera公開課筆記: 斯坦福大學機器學習第七課“正則化(Regularization)” 斯坦福大學機器學習第七課"正則化“學習筆記,本次課程主要包括4部分: 1) The Problem of Overfitting(過擬合問題) 2) Cost Fu
python機器學習——正則化
我們在訓練的時候經常會遇到這兩種情況: 1、模型在訓練集上誤差很大。 2、模型在訓練集上誤差很小,表現不錯,但是在測試集上的誤差很大 我們先來分析一下這兩個問題: 對於第一個問題,明顯就是沒有訓練好,也就是模型沒有很好擬合數據的能力,並沒有學會如何擬合,可能是因為在訓練時我們選擇了較少的特徵,或者是我們選擇的
l1正則化的稀疏表示和l2正則化的協同表示
這些天一直在看稀疏表示和協同表示的相關論文,特此做一個記錄: 這篇文章將主要討論以下的問題: 1.稀疏表示是什麼? 2.l1正則化對於稀疏表示的幫助是什麼,l0,l1,l2,無窮範數的作用? 3.稀疏表示的robust為什麼好? 4.l2正則化的協同表
【機器學習】正則化方法
正則化方法:L1和L2 regularization、資料集擴增、dropout 正則化方法:防止過擬合,提高泛化能力,減少部分特徵的權重,進而忽略部分無關緊要的特徵。因為考慮全部特徵會將噪聲加入進去,也就導致過擬合。 在訓練資料不夠多時,或者overtraining時,常常會導致overf
機器學習中的正則化方法
引數範數懲罰 L1 L2 regularization 正則化一般具有如下形式:(結構風險最小化) 其中,第一項是經驗風險,第二項是正則化項,lambda>=0為調整兩者之間關係的係數。 正則化項可以取不同的形式,如引數向量w的L2範數:
正則化方法 L1和L2 regularization 資料集擴增 dropout
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
深度學習基礎--正則化與norm--L1範數與L2範數的聯絡
L1範數與L2範數的聯絡 假設需要求解的目標函式為:E(x) = f(x) + r(x) 其中f(x)為損失函式,用來評價模型訓練損失,必須是任意的可微凸函式,r(x)為規範化約束因子,用來對模型進行限制。 根據模型引數的概率分佈不同,r(x)一般有: 1)L1正規化
深度學習正則化-引數範數懲罰(L1,L2範數)
L0範數懲罰 機器學習中最常用的正則化措施是限制模型的能力,其中最著名的方法就是L1和L2範數懲罰。 假如我們需要擬合一批二次函式分佈的資料,但我們並不知道資料的分佈規律,我們可能會先使用一次函式去擬合,再
吳恩達深度學習筆記(34)-你不知道的其他正則化方法
其他正則化方法(Other regularization methods) 除了L2正則化和隨機失活(dropout)正則化,還有幾種方法可以減少神經網路中的過擬合: 一.資料擴增 假設你正在擬合貓咪圖片分類器,如果你想通過擴增訓練資料來解決過擬合,但擴增資料代價高,而且有
深度學習正則化---提前終止
VM bsp jsb img tle 過程 部分 pos mdf 提前終止 ??在對模型進行訓練時,我們可以將我們的數據集分為三個部分,訓練集、驗證集、測試集。我們在訓練的過程中,可以每隔一定量的step,使用驗證集對訓練的模型進行預測,一般來說,模型在訓練集和驗證集的損失
深度學習正則化---數據增強
clas pos 深度 偏移 噪聲 不同 更多 種類 圖片尺寸 在深度學習應用中訓練數據往往不夠,可以通過添加噪聲、裁剪等方法獲取更多的數據。另外,考慮到噪聲的多樣性,可以通過添加不同種類的噪聲獲取更多類型的數據,比如裁剪、旋轉、扭曲、拉伸等不同的方法生成不同的數據。 主要
損失函式正則化方法
正則化方法 為防止模型過擬合,提高模型的泛化能力,通常會在損失函式的後面新增一個正則化項。L1正則化和L2正則化可以看做是損失函式的懲罰項。所謂【懲罰】是指對損失函式中的某些引數做一些限制 L1正則化(ℓ1 -norm) 使用L1正則化的模型建叫做Lasso Regulariza