
吳恩達深度學習筆記(34)-你不知道的其他正則化方法
其他正則化方法(Other regularization methods)
除了L2正則化和隨機失活(dropout)正則化,還有幾種方法可以減少神經網路中的過擬合:
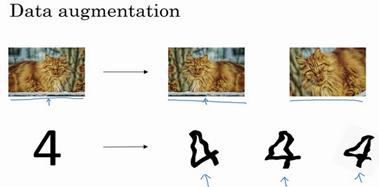
一.資料擴增
假設你正在擬合貓咪圖片分類器,如果你想通過擴增訓練資料來解決過擬合,但擴增資料代價高,而且有時候我們無法擴增資料,但我們可以通過新增這類圖片來增加訓練集。
例如,水平翻轉圖片,並把它新增到訓練集。所以現在訓練集中有原圖,還有翻轉後的這張圖片,所以通過水平翻轉圖片,訓練集則可以增大一倍,因為訓練集有冗餘,這雖然不如我們額外收集一組新圖片那麼好,但這樣做節省了獲取更多貓咪圖片的花費。

除了水平翻轉圖片,你也可以隨意裁剪圖片,這張圖是把原圖旋轉並隨意放大後裁剪的,仍能辨別出圖片中的貓咪。
通過隨意翻轉和裁剪圖片,我們可以增大資料集,額外生成假訓練資料。和全新的,獨立的貓咪圖片資料相比,這些額外的假的資料無法包含像全新資料那麼多的資訊,但我們這麼做基本沒有花費,代價幾乎為零,除了一些對抗性代價。
以這種方式擴增演算法資料,進而正則化資料集,減少過擬合比較廉價。

像這樣人工合成數據的話,我們要通過演算法驗證,圖片中的貓經過水平翻轉之後依然是貓。大家注意,我並沒有垂直翻轉,因為我們不想上下顛倒圖片,也可以隨機選取放大後的部分圖片,貓可能還在上面。
對於光學字元識別,我們還可以通過新增數字,隨意旋轉或扭曲數字來擴增資料,把這些數字新增到訓練集,它們仍然是數字。為了方便說明,我對字元做了強變形處理,所以數字4看起來是波形的,其實不用對數字4做這麼誇張的扭曲,只要輕微的變形就好,我做成這樣是為了讓大家看的更清楚。實際操作的時候,我們通常對字元做更輕微的變形處理。因為這幾個4看起來有點扭曲。所以,資料擴增可作為正則化方法使用,實際功能上也與正則化相似。
二.early stopping
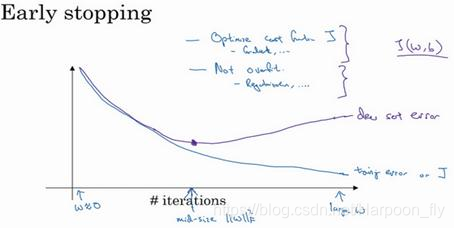
還有另外一種常用的方法叫作early stopping,執行梯度下降時,我們可以繪製訓練誤差,或只繪製代價函式J的優化過程,在訓練集上用0-1記錄分類誤差次數。呈單調下降趨勢,如圖。
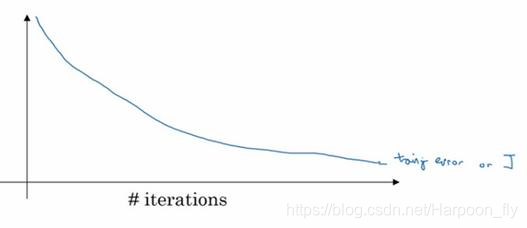
因為在訓練過程中,我們希望訓練誤差,代價函式J都在下降,通過early stopping,我們不但可以繪製上面這些內容,還可以繪製驗證集誤差,它可以是驗證集上的分類誤差,或驗證集上的代價函式,邏輯損失和對數損失等,你會發現,驗證集誤差通常會先呈下降趨勢,然後在某個節點處開始上升,early stopping的作用是,你會說,神經網路已經在這個迭代過程中表現得很好了,我們在此停止訓練吧,得到驗證集誤差,它是怎麼發揮作用的?
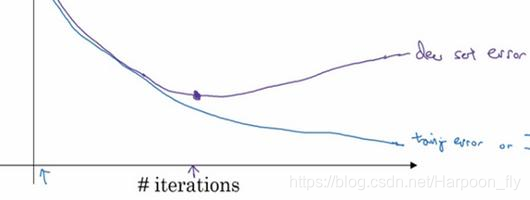
當你還未在神經網路上執行太多迭代過程的時候,引數w接近0,因為隨機初始化w值時,它的值可能都是較小的隨機值,所以在你長期訓練神經網路之前w依然很小,在迭代過程和訓練過程中w的值會變得越來越大,比如在這兒,神經網路中引數w的值已經非常大了,所以early stopping要做就是在中間點停止迭代過程,我們得到一個w值中等大小的弗羅貝尼烏斯範數,與L2正則化相似,選擇引數w範數較小的神經網路,但願你的神經網路過度擬合不嚴重。
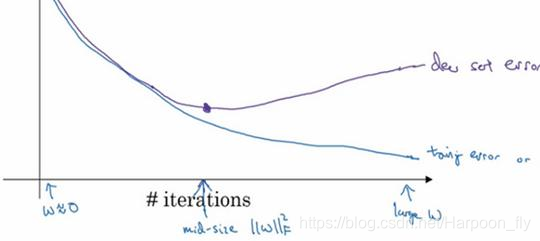
術語early stopping代表提早停止訓練神經網路,訓練神經網路時,我有時會用到early stopping,但是它也有一個缺點,我們來了解一下。
我認為機器學習過程包括幾個步驟,
其中一步是選擇一個演算法來優化代價函式J,我們有很多種工具來解決這個問題,如梯度下降,後面我會介紹其它演算法,例如Momentum,RMSprop和Adam等等,但
是優化代價函式J之後,我也不想發生過擬合,也有一些工具可以解決該問題,比如正則化,擴增資料等等。
在機器學習中,超級引數激增,選出可行的演算法也變得越來越複雜。
發現,如果我們用一組工具優化代價函式J,機器學習就會變得更簡單,在重點優化代價函式J時,你只需要留意w和b,J(w,b)的值越小越好,你只需要想辦法減小這個值,其它的不用關注。
然後,預防過擬合還有其他任務,換句話說就是減少方差,這一步我們用另外一套工具來實現,這個原理有時被稱為“正交化”。思路就是在一個時間做一個任務,後面課上我會具體介紹正交化,如果你還不瞭解這個概念,不用擔心。
但對我來說early stopping的主要缺點就是你不能獨立地處理這兩個問題,因為提早停止梯度下降,也就是停止了優化代價函式J,因為現在你不再嘗試降低代價函式J,所以代價函式J的值可能不夠小,同時你又希望不出現過擬合,你沒有采取不同的方式來解決這兩個問題,而是用一種方法同時解決兩個問題,這樣做的結果是我要考慮的東西變得更復雜。
如果不用early stopping,另一種方法就是L2正則化,訓練神經網路的時間就可能很長。我發現,這導致超級引數搜尋空間更容易分解,也更容易搜尋,但是缺點在於,你必須嘗試很多正則化引數λ的值,這也導致搜尋大量λ值的計算代價太高。
Early stopping的優點是,只執行一次梯度下降,你可以找出w的較小值,中間值和較大值,而無需嘗試L2正則化超級引數λ的很多值。
如果你還不能完全理解這個概念,沒關係,下節課我們會詳細講解正交化,這樣會更好理解。
雖然L2正則化有缺點,可還是有很多人願意用它。吳恩達老師個人更傾向於使用L2正則化,嘗試許多不同的λ值,假設你可以負擔大量計算的代價。而使用early stopping也能得到相似結果,還不用嘗試這麼多λ值。
這節課我們講了如何使用資料擴增,以及如何使用early stopping降低神經網路中的方差或預防過擬合。