
ROS開發筆記(9)——ROS 深度強化學習應用之keras版本dqn程式碼分析
阿新 • • 發佈:2018-12-18
在ROS開發筆記(8)中構建了ROS中DQN演算法的開發環境,在此基礎上,對演算法程式碼進行了分析,並做了簡單的修改:
修改1 : 改變了儲存模型引數在迴圈中的位置,原來是每個10整數倍數回合裡面每一步都修改(相當於修改episode_step次),改成了每個10整數倍數回合修改一次 # if e % 10 == 0: # agent.model.save(agent.dirPath + str(e) + '.h5') # with open(agent.dirPath + str(e) + '.json', 'w') as outfile: # param_keys = ['epsilon'] # param_values = [agent.epsilon] # param_dictionary = dict(zip(param_keys, param_values)) # json.dump(param_dictionary, outfile)
修改2 :改變了agent.updateTargetModel()的位置,原來是每次done都修改,改成了每經過target_up步後修改 # if global_step % agent.target_update == 0: # agent.updateTargetModel() # rospy.loginfo("UPDATE TARGET NETWORK")
結果如下:
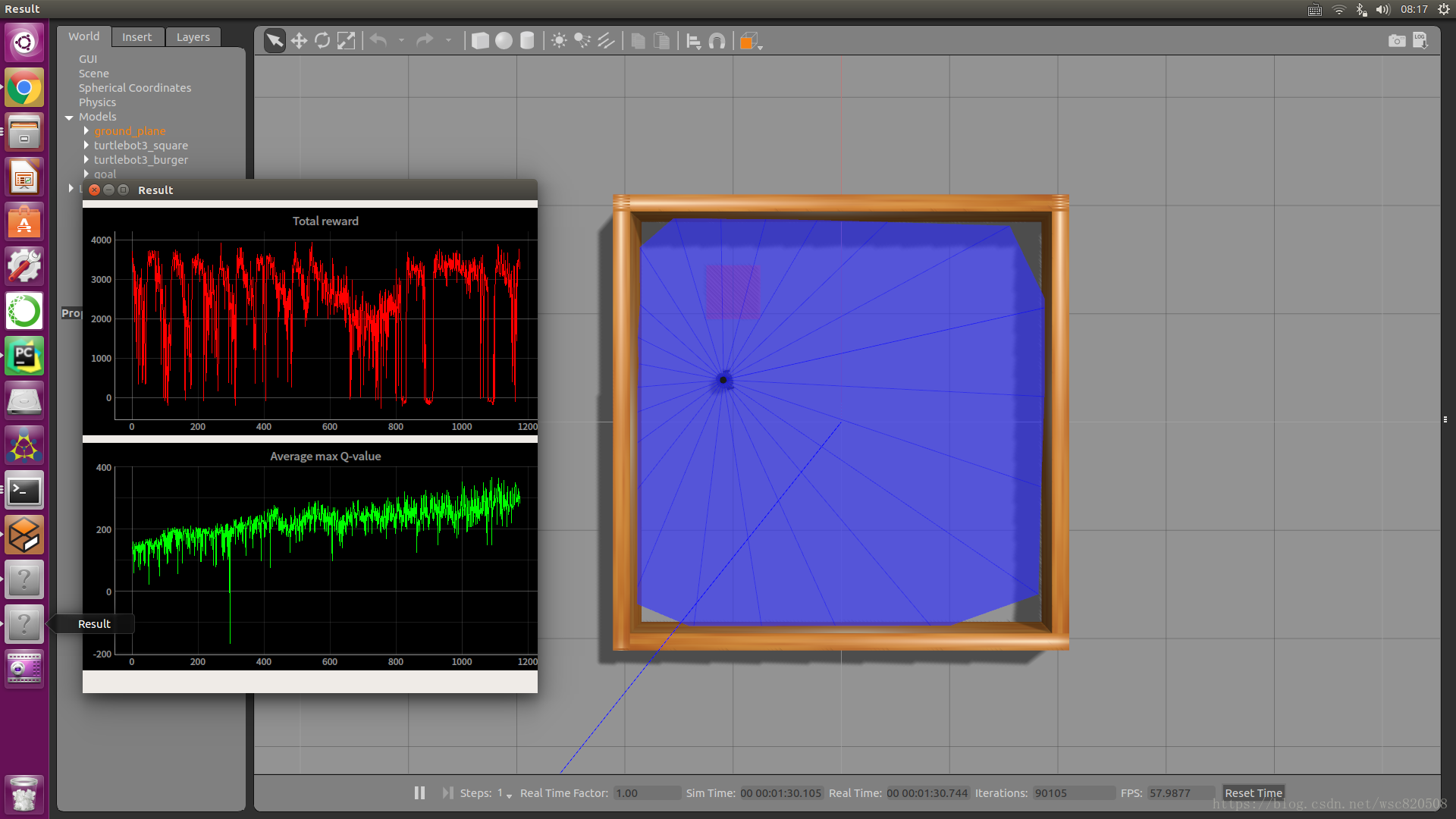
下面是修改後的程式碼及其註釋:
#!/usr/bin/env python #-*- coding:utf-8 -*- ################################################################################# # Copyright 2018 ROBOTIS CO., LTD. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. ################################################################################# # 原作者 # Authors: Gilbert # import rospy import os import json import numpy as np import random import time import sys sys.path.append(os.path.dirname(os.path.abspath(os.path.dirname(__file__)))) from collections import deque from std_msgs.msg import Float32MultiArray from keras.models import Sequential, load_model from keras.optimizers import RMSprop from keras.layers import Dense, Dropout, Activation # 匯入 Env from src.turtlebot3_dqn.environment_stage_1 import Env #最大回合數 EPISODES = 3000 #強化學習網路 class ReinforceAgent(): #初始化函式 def __init__(self, state_size, action_size): # 建立 result 話題 self.pub_result = rospy.Publisher('result', Float32MultiArray, queue_size=5) # 獲取當前檔案完整路徑 self.dirPath = os.path.dirname(os.path.realpath(__file__)) # 基於當前路徑生成模型儲存路徑字首 self.dirPath = self.dirPath.replace('turtlebot3_dqn/nodes', 'turtlebot3_dqn/save_model/stage_1_') # 初始化 result 話題 self.result = Float32MultiArray() #wsc self.load_model = False #wsc self.load_episode = 0 # 匯入前期訓練的模型 self.load_model =True self.load_episode = 150 # self.load_model =False # self.load_episode = 0 #狀態數 self.state_size = state_size #動作數 self.action_size = action_size # 單個回合最大步數 self.episode_step = 6000 # 每2000次更新一次target網路引數 self.target_update = 2000 # 折扣因子 計算reward時用 當下反饋最重要 時間越久的影響越小 self.discount_factor = 0.99 # 學習率learning_rate 學習率決定了引數移動到最優值的速度快慢。 # 如果學習率過大,很可能會越過最優值;反而如果學習率過小,優化的效率可能過低,長時間演算法無法收斂。 self.learning_rate = 0.00025 # 初始ϵ——epsilon # 探索與利用原則 # 探索強調發掘環境中的更多資訊,並不侷限在已知的資訊中; # 利用強調從已知的資訊中最大化獎勵; # greedy策略只注重了後者,沒有涉及前者; # ϵ-greedy策略兼具了探索與利用,它以ϵ的概率從所有的action中隨機抽取一個,以1−ϵ的概率抽取能獲得最大化獎勵的action。 self.epsilon = 1.0 #隨著模型的訓練,已知的資訊越來越可靠,epsilon應該逐步衰減 self.epsilon_decay = 0.99 #最小的epsilon_min,低於此值後不在利用epsilon_decay衰減 self.epsilon_min = 0.05 #batch_size 批處理大小 # 合理範圍內,增大 Batch_Size # 記憶體利用率提高了,大矩陣乘法的並行化效率提高 # 跑完一次epoch(全資料集)所需要的迭代次數減小,對於相同資料量的處理速度進一步加快 # 在一定範圍內,一般來說batch size越大,其確定的下降方向越準,引起的訓練震盪越小 # 盲目增大batch size 有什麼壞處 # 記憶體利用率提高了,但是記憶體容量可能撐不住了 # 跑完一次epoch(全資料集)所需要的迭代次數減少,但是想要達到相同的精度,其所花費的時間大大增加了,從而對引數的修正也就顯得更加緩慢 # batch size 大到一定的程度,其確定的下降方向已經基本不再變化 self.batch_size = 64 # 用於 experience replay 的 agent.memory # DQN的經驗回放池(agent.memory)大於train_start才開始訓練網路(agent.trainModel) self.train_start = 64 # 用佇列儲存experience replay 資料,並設定佇列最大長度 self.memory = deque(maxlen=1000000) # 網路模型構建 self.model = self.buildModel() #target網路構建 self.target_model = self.buildModel() self.updateTargetModel() # 訓練可以載入之前儲存的模型引數進行 if self.load_model: self.model.set_weights(load_model(self.dirPath+str(self.load_episode)+".h5").get_weights()) with open(self.dirPath+str(self.load_episode)+'.json') as outfile: param = json.load(outfile) self.epsilon = param.get('epsilon') #wsc self.epsilon = 0.5 # 網路模型構建 def buildModel(self): # Sequential序列模型是一個線性的層次堆疊 model = Sequential() # 設定dropout,防止過擬合 dropout = 0.2 # 新增一層全連線層,輸入大小為input_shape=(self.state_size,),輸出大小為64,啟用函式為relu,權值初始化方法為lecun_uniform model.add(Dense(64, input_shape=(self.state_size,), activation='relu', kernel_initializer='lecun_uniform')) # 新增一層全連線層,輸出大小為64,啟用函式為relu,權值初始化方法為lecun_uniform model.add(Dense(64, activation='relu', kernel_initializer='lecun_uniform')) # 新增dropout層 model.add(Dropout(dropout)) # 新增一層全連線層,輸出大小為action_size,權值初始化方法為lecun_uniform model.add(Dense(self.action_size, kernel_initializer='lecun_uniform')) # 新增一層linear啟用層 model.add(Activation('linear')) # 優化演算法RMSprop是AdaGrad演算法的改進。鑑於神經網路都是非凸條件下的,RMSProp在非凸條件下結果更好,改變梯度累積為指數衰減的移動平均以丟棄遙遠的過去歷史。 # 經驗上,RMSProp被證明有效且實用的深度學習網路優化演算法。rho=0.9為衰減係數,epsilon=1e-06為一個小常數,保證被小數除的穩定性 model.compile(loss='mse', optimizer=RMSprop(lr=self.learning_rate, rho=0.9, epsilon=1e-06)) # model.summary():打印出模型概況 model.summary() return model # 計算Q值,用到reward(當前env回饋),done,以及有taget_net網路計算得到的next_target def getQvalue(self, reward, next_target, done): if done: return reward else: return reward + self.discount_factor * np.amax(next_target) # eval_net用於預測 q_eval # target_net 用於預測 q_target 值 # 將eval net權重賦給target net def updateTargetModel(self): self.target_model.set_weights(self.model.get_weights()) #基於ϵ——epsilon策略選擇動作 def getAction(self, state): if np.random.rand() <= self.epsilon: self.q_value = np.zeros(self.action_size) return random.randrange(self.action_size) else: q_value = self.model.predict(state.reshape(1, len(state))) self.q_value = q_value return np.argmax(q_value[0]) #將經驗資料存入經驗池 當前狀態state,基於當前狀態選擇的動作action,執行動作獲得的回報reward,執行動作後環境變成的next_state,以及done def appendMemory(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done)) # 訓練網路模型 def trainModel(self, target=False): mini_batch = random.sample(self.memory, self.batch_size) X_batch = np.empty((0, self.state_size), dtype=np.float64) Y_batch = np.empty((0, self.action_size), dtype=np.float64) for i in range(self.batch_size): states = mini_batch[i][0] actions = mini_batch[i][1] rewards = mini_batch[i][2] next_states = mini_batch[i][3] dones = mini_batch[i][4] # 計算q_value q_value = self.model.predict(states.reshape(1, len(states))) self.q_value = q_value #計算next_target if target: next_target = self.target_model.predict(next_states.reshape(1, len(next_states))) else: next_target = self.model.predict(next_states.reshape(1, len(next_states))) # 計算 next_q_value next_q_value = self.getQvalue(rewards, next_target, dones) X_batch = np.append(X_batch, np.array([states.copy()]), axis=0) Y_sample = q_value.copy() Y_sample[0][actions] = next_q_value Y_batch = np.append(Y_batch, np.array([Y_sample[0]]), axis=0) if dones: X_batch = np.append(X_batch, np.array([next_states.copy()]), axis=0) Y_batch = np.append(Y_batch, np.array([[rewards] * self.action_size]), axis=0) self.model.fit(X_batch, Y_batch, batch_size=self.batch_size, epochs=1, verbose=0) if __name__ == '__main__': rospy.init_node('turtlebot3_dqn_stage_1') pub_result = rospy.Publisher('result', Float32MultiArray, queue_size=5) pub_get_action = rospy.Publisher('get_action', Float32MultiArray, queue_size=5) result = Float32MultiArray() get_action = Float32MultiArray() state_size = 26 action_size = 5 env = Env(action_size) agent = ReinforceAgent(state_size, action_size) scores, episodes = [], [] global_step = 0 start_time = time.time() # 迴圈EPISODES個回合 for e in range(agent.load_episode + 1, EPISODES): done = False state = env.reset() score = 0 # 每10個回合儲存一次網路模型引數 if e % 10 == 0: agent.model.save(agent.dirPath + str(e) + '.h5') with open(agent.dirPath + str(e) + '.json', 'w') as outfile: param_keys = ['epsilon'] param_values = [agent.epsilon] param_dictionary = dict(zip(param_keys, param_values)) json.dump(param_dictionary, outfile) # 每個回合迴圈episode_step步 for t in range(agent.episode_step): # 選擇動作 action = agent.getAction(state) # Env動作一步,返回next_state, reward, done next_state, reward, done = env.step(action) # 存經驗值 agent.appendMemory(state, action, reward, next_state, done) # agent.memory至少要收集agent.train_start(64)個才能開始訓練 # global_step 沒有達到 agent.target_update之前要用到target網路的地方由eval代替 if len(agent.memory) >= agent.train_start: if global_step <= agent.target_update: agent.trainModel() else: agent.trainModel(True) # 將回報值累加成score score += reward state = next_state # 釋出 get_action 話題 get_action.data = [action, score, reward] pub_get_action.publish(get_action) # 超過500步時設定為超時,回合結束 if t >= 500: rospy.loginfo("Time out!!") done = True if done: # 釋出result話題 result.data = [score, np.max(agent.q_value)] pub_result.publish(result) scores.append(score) episodes.append(e) # 計算執行時間 m, s = divmod(int(time.time() - start_time), 60) h, m = divmod(m, 60) rospy.loginfo('Ep: %d score: %.2f memory: %d epsilon: %.2f time: %d:%02d:%02d', e, score, len(agent.memory), agent.epsilon, h, m, s) break global_step += 1 # 每經過agent.target_update,更新target網路引數 if global_step % agent.target_update == 0: agent.updateTargetModel() rospy.loginfo("UPDATE TARGET NETWORK") # 更新衰減epsilon值,直到低於等於agent.epsilon_min if agent.epsilon > agent.epsilon_min: agent.epsilon *= agent.epsilon_decay