
機器學習實戰——SVD(奇異值分解)
與PCA一樣的學習過程,在學習SVD時同樣補習了很多的基礎知識,現在已經大致知道了PCA的應用原理,SVD個人感覺相對要難一點,但主要步驟還是能勉強理解,所以這裡將書本上的知識和個人的理解做一個記錄。主要關於(SVD原理、降維公式、重構原矩陣、SVD的兩個實際應用),當然矩陣的分解和相對的公式我會給出寫的更好的文章對於說明(個人基礎有限)。
(最後給出兩條SVD最重要的公式)
SVD(奇異值分解):
- 優點:簡化資料,去除噪聲點,提高演算法的結果;
- 缺點:資料的轉換可能難以理解;
- 適用於資料型別:數值型。
通過SVD對資料的處理,我們可以使用小得多的資料集來表示原始資料集,這樣做實際上是去除了噪聲和冗餘資訊,以此達到了優化資料、提高結果的目的。
隱形語義索引:最早的SVD應用之一就是資訊檢索,我們稱利用SVD的方法為隱性語義檢索(LSI)或隱形語義分析(LSA)
推薦系統:SVD的另一個應用就是推薦系統,較為先進的推薦系統先利用SVD從資料中構建一個主題空間,然後再在該空間下計算相似度,以此提高推薦的效果。
SVD與PCA不同,PCA是對資料的協方差矩陣進行矩陣的分解,而SVD是直接在原始矩陣上進行的矩陣分解。並且能對非方陣矩陣分解,得到左奇異矩陣U、sigma矩陣Σ、右奇異矩陣VT。
奇異性分解可以將一個矩陣分解成3個矩陣
、
、
,其中U、VT都是單式矩陣(unitary matrix),Σ是一個對角矩陣,也就是說只有對角線有值。對角元素稱為奇異值,它們對應了原始矩陣Data的奇異值,如下:
[[2 0 0] [0 3 0] [0 0 4] [0 0 0]]
一般奇異值我們只選擇某一部分,選擇的規則很多種,主要的一種為:
選擇奇異值中佔總奇異值總值90%的那些奇異值。(下面有演示如何選擇)
SVD分解公式如下(類似於因式分解):
=
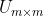
圖形化表示奇異值分解:

在PCA中我們根據協方差矩陣得到特徵值,它們告訴我們資料集中的重要特徵,Σ中的奇異值亦是如此。奇異值和特徵值是有關係的,這裡的奇異值就是矩陣特徵值的平方根。
SCV實現的相關線性代數,但我們無需擔心SVD的實現,在Numpy中有一個稱為線性代數linalg的線性代數工具箱能幫助我們。下面演示其用法對於一個簡單的矩陣:
[[1 1] [1 7]]
from numpy import *
from numpy import linalg as la
df = mat(array([[1,1],[1,7]]))
U,Sigma,VT = la.svd(df)
print(U)
# [[ 0.16018224 0.98708746]
# [ 0.98708746 -0.16018224]]
print(Sigma)
# [7.16227766 0.83772234]
print(VT)
# [[ 0.16018224 0.98708746]
# [ 0.98708746 -0.16018224]]通過簡單的使用該工具就能得到運算的結果,所以我們著重應該理解的應該是這些結果的含義以及後續對它們的使用,下面通過推薦系統這個示例來進行實際的操作(資料集降維、重構資料集)。
基於協同過濾的搜尋引擎:
我之前在集體程式設計智慧中學習了該演算法,大致有兩種方法來實現:
- 基於使用者的協作型過濾
- 基於物品的協作型過濾
兩種方法大致相同,但是在不同的環境下,使用最佳的方法能最大化的提升演算法的效果。如下圖(後面的示例資料)所示,對兩樣商品直接的距離進行計算,這稱為基於物品的相似度。而對行與行(使用者之間)進行距離的計算,這稱為基於使用者的相似度。到底該選用那種方法呢?這取決與使用者或物品的數量,基於物品相似度的計算時間會隨著物品數量的增加而增加。基於使用者相似度則取決於使用者數量,例如:一個最大的商店擁有大概100000種商品,而它的使用者可能有500000人,這時選擇基於物品相似度可能效果好很多。
用上面的資料解釋瞭如何選擇基於協同過濾,下面使用基於物品相似度的方法來構建推薦系統(先直接使用原始矩陣來構建,然後再將處理函式換為SVD的處理函式,以便作比較)。
(說明:資料間的距離計算採用餘玄相似、歐式距離、皮爾遜相關度其中任一種,這裡不再解釋,提供連結自行學習)
程式碼:
from numpy import *
from numpy import linalg as la
# (使用者x商品) # 為0表示該使用者未評價此商品,即可以作為推薦商品
def loadExData():
return [[0, 0, 0, 2, 2],
[0, 0, 0, 3, 3],
[0, 0, 0, 1, 1],
[1, 1, 1, 0, 0],
[2, 2, 2, 0, 0],
[5, 0, 5, 0, 0],
[1, 1, 1, 0, 0]]
# !!!假定匯入資料都為列向量,若行向量則需要對程式碼簡單修改
# 歐幾里德距離 這裡返回結果已處理 0,1 0最大相似,1最小相似 歐氏距離轉換為2範數計算
def ecludSim(inA,inB):
return 1.0 / (1.0 + la.norm(inA-inB))
# 皮爾遜相關係數 numpy的corrcoef函式計算
def pearsSim(inA,inB):
if(len(inA) < 3):
return 1.0
return 0.5 + 0.5*corrcoef(inA,inB,rowvar=0)[0][1] # 使用0.5+0.5*x 將-1,1 轉為 0,1
# 餘玄相似度 根據公式帶入即可,其中分母為2範數計算,linalg的norm可計算範數
def cosSim(inA,inB):
num = float(inA.T * inB)
denom = la.norm(inA) * la.norm(inB)
return 0.5 + 0.5*(num/denom) # 同樣操作轉換 0,1
# 對物品評分 (資料集 使用者行號 計算誤差函式 推薦商品列號)
def standEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1] # 獲得特徵列數
simTotal = 0.0; ratSimTotal = 0.0 # 兩個計算估計評分值變數初始化
for j in range(n):
userRating = dataMat[user,j] #獲得此人對該物品的評分
if userRating == 0: # 若此人未評價過該商品則不做下面處理
continue
overLap = nonzero(logical_and(dataMat[:,item].A>0,dataMat[:,j].A>0))[0] # 獲得相比較的兩列同時都不為0的資料行號
if len(overLap) == 0:
similarity = 0
else:
# 求兩列的相似度
similarity = simMeas(dataMat[overLap,item],dataMat[overLap,j]) # 利用上面求得的兩列同時不為0的行的列向量 計算距離
# print('%d 和 %d 的相似度是: %f' % (item, j, similarity))
simTotal += similarity # 計算總的相似度
ratSimTotal += similarity * userRating # 不僅僅使用相似度,而是將評分當權值*相似度 = 貢獻度
if simTotal == 0: # 若該推薦物品與所有列都未比較則評分為0
return 0
else:
return ratSimTotal/simTotal # 歸一化評分 使其處於0-5(評級)之間
# 給出推薦商品評分
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
unratedItems = nonzero(dataMat[user,:].A==0)[1] # 找到該行所有為0的位置(即此使用者未評價的商品,才做推薦)
if len(unratedItems) == 0:
return '所有物品都已評價...'
itemScores = []
for item in unratedItems: # 迴圈所有沒有評價的商品列下標
estimatedScore = estMethod(dataMat, user, simMeas, item) # 計算當前產品的評分
itemScores.append((item, estimatedScore))
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N] # 將推薦商品排序
# 結果測試如下:
myMat = mat(loadExData())
myMat[0,1] = myMat[0,0] = myMat[1,0] = myMat[2,0] = 4 # 將資料某些值替換,增加效果
myMat[3,3] = 2
result1 = recommend(myMat,2) # 餘玄相似度
print(result1)
result2 = recommend(myMat,2,simMeas=ecludSim) # 歐氏距離
print(result2)
result3 = recommend(myMat,2,simMeas=pearsSim) # 皮爾遜相關度
print(result3)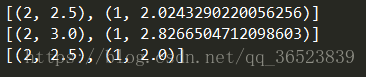
上面程式碼種用了三種計算距離的函式,經過測試後使用其中一種便可以了。然後對於物品評分函式中的nonzero(logical_and)不是很明白的請看這篇專門講解的文章。以上為普通的處理方式,下面使用SVD來做基於物品協同過濾。
SVD方法,用下面函式(svdEst)來替換上面的物品評價函式(standEst)即可,並且這裡使用更復雜的資料集:
# (使用者x商品) # 為0表示該使用者未評價此商品,即可以作為推薦商品
def loadExData2():
return [[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]
# 替代上面的standEst(功能) 該函式用SVD降維後的矩陣來計算評分
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U,Sigma,VT = la.svd(dataMat)
Sig4 = mat(eye(4)*Sigma[:4]) #將奇異值向量轉換為奇異值矩陣
xformedItems = dataMat.T * U[:,:4] * Sig4.I # 降維方法 通過U矩陣將物品轉換到低維空間中 (商品數行x選用奇異值列)
for j in range(n):
userRating = dataMat[user,j]
if userRating == 0 or j == item:
continue
# 這裡需要說明:由於降維後的矩陣與原矩陣代表資料不同(行由使用者變為了商品),所以在比較兩件商品時應當取【該行所有列】 再轉置為列向量傳參
similarity = simMeas(xformedItems[item,:].T,xformedItems[j,:].T)
# print('%d 和 %d 的相似度是: %f' % (item, j, similarity))
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0:
return 0
else:
return ratSimTotal/simTotal
# 結果測試如下:
myMat = mat(loadExData2())
result1 = recommend(myMat,1,estMethod=svdEst) # 需要傳參改變預設函式
print(result1)
result2 = recommend(myMat,1,estMethod=svdEst,simMeas=pearsSim)
print(result2)
上面的之所以使用4這個數字,是因為通過預先計算得到能滿足90%的奇異值能量的前N個奇異值。判斷計算如下:
# 選出奇異值能量大於90%的所有奇異值
myMat = mat(loadExData2())
U,sigma,VT = linalg.svd(myMat)
sigma = sigma**2 # 對奇異值求平方
cnt = sum(sigma) # 所有奇異值的和
print(cnt)
value = cnt*0.9 # 90%奇異值能量
print(value)
cnt2 = sum(sigma[:3]) # 2小於90%,前3個則大於90%,所以這裡選擇前三個奇異值
print(cnt2)
# 541.9999999999995
# 487.7999999999996
# 500.5002891275793在函式svdEst中使用SVD方法,將資料集對映到低緯度的空間中,再做運算。其中的xformedItems = dataMat.T*U[:,:4]*Sig4.I可能不是很好理解,它就是SVD的降維步驟,通過U矩陣和Sig4逆矩陣將商品轉換到低維空間(得到 商品行,選用奇異值列)。
以上是SVD的一個示例,但是對此有幾個問題:
- 我們不必在每次評分是都做SVD分解,大規模資料上可能降低效率,可以在程式呼叫時執行一次,在大型系統中每天執行一次或頻率不高,還要離線執行;
- 矩陣中有很多0,實際系統中0更多,可以通過只儲存非0元素來節省空間和計算開銷;
- 計算資源浪費來自於相似度的計算,每次一個推薦時都需要計算多個物品評分(即相似度),在需要時此記錄可以被使用者重複使用。實際中,一個普遍的做法是離線計算並儲存相似度得分,這一點在之前學習集體程式設計智慧中有說明。
基於SVD的影象壓縮:
這裡不採用書中的例子來講解,因為無趣所以這裡換作我們的男神來做一個簡單的SVD圖片壓縮作為一個示例:
首先放上男神圖片:

基於SVD圖片壓縮原理其實很簡單,圖片其實就是數字矩陣,通過SVD將該矩陣降維,只使用其中的重要特徵來表示該圖片從而達到了壓縮的目的。
直接上程式碼:
# 男神老吳SVD處理
from skimage import io
import matplotlib.pyplot as plt
path = 'male_god.jpg'
data = io.imread(path)
data = mat(data) # 需要mat處理後才能在降維中使用矩陣的相乘
U,sigma,VT = linalg.svd(data)
# 在重構之前,依據前面的方法需要選擇達到某個能量度的奇異值
cnt = sum(sigma)
print(cnt)
cnt90 = 0.9*cnt # 達到90%時的奇異總值
print(cnt90)
count = 50 # 選擇前50個奇異值
cntN = sum(sigma[:count])
print(cntN)
# 重構矩陣
dig = mat(eye(count)*sigma[:count]) # 獲得對角矩陣
# dim = data.T * U[:,:count] * dig.I # 降維 格外變數這裡沒有用
redata = U[:,:count] * dig * VT[:count,:] # 重構
plt.imshow(redata,cmap='gray') # 取灰
plt.show() # 可以使用save函式來儲存圖片
原圖片為870x870,儲存畫素點值為870x870 = 756900,使用SVD,取前50個奇異值則變為:
儲存量大大減小,僅50個奇異值就已經能很好的反應原資料了。
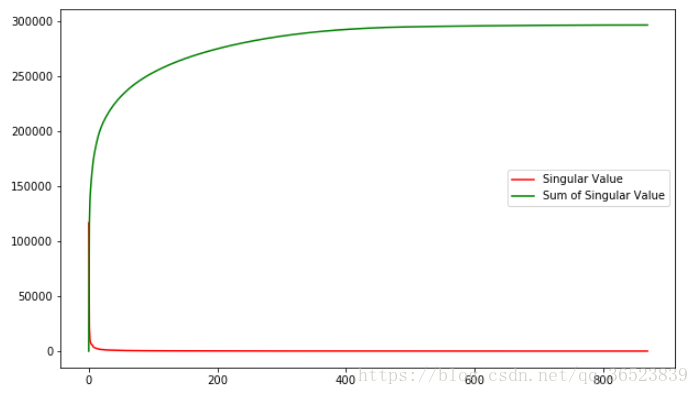
值得一提的是,奇異值從大到小衰減得特別快,在很多情況下,前 10% 甚至 1% 的奇異值的和就佔了全部的奇異值之和的 99% 以上了。這對於資料壓縮來說是個好事。下面這張圖展示了本例中奇異值和奇異值累加的分佈(參考部落格下面附上鍊接):
SVD兩個個人覺得最重要的計算步驟這裡說一下:
- 資料集降維:
這裡的sigma為對角矩陣(需要利用原來svd返回的sigma向量構建矩陣,構建需要使用count這個值)。U為svd返回的左奇異矩陣,count為我們指定的多少個奇異值,這也是sigma矩陣的維數。
- 重構資料集:
這裡的sigma同樣為對角矩陣(需要利用原來svd返回的sigma向量構建矩陣,構建需要使用count這個值),VT為svd返回的右奇異矩陣,count為我們指定的多少個奇異值(可以按能量90%規則選取)。
以上為兩個個人覺得最重要的公式,如果有不明白的可以參考上面的程式碼,有使用到這兩個公式。(雖然不負責任,但還是說一下:如果你不能立刻理解SVD的原理,可以先記下這兩個公式來使用,後面有時間了在來深入瞭解哈哈)
參考書籍:《機器學習實戰》