
Navicat Premium怎麼設定欄位的唯一性(UNIQUE)?
1、開啟你想要設計的表

2、清楚你想要設計哪個欄位為唯一的,例如我這裡是設計name欄位唯一,然後點選索引

3、然後設定相關內容
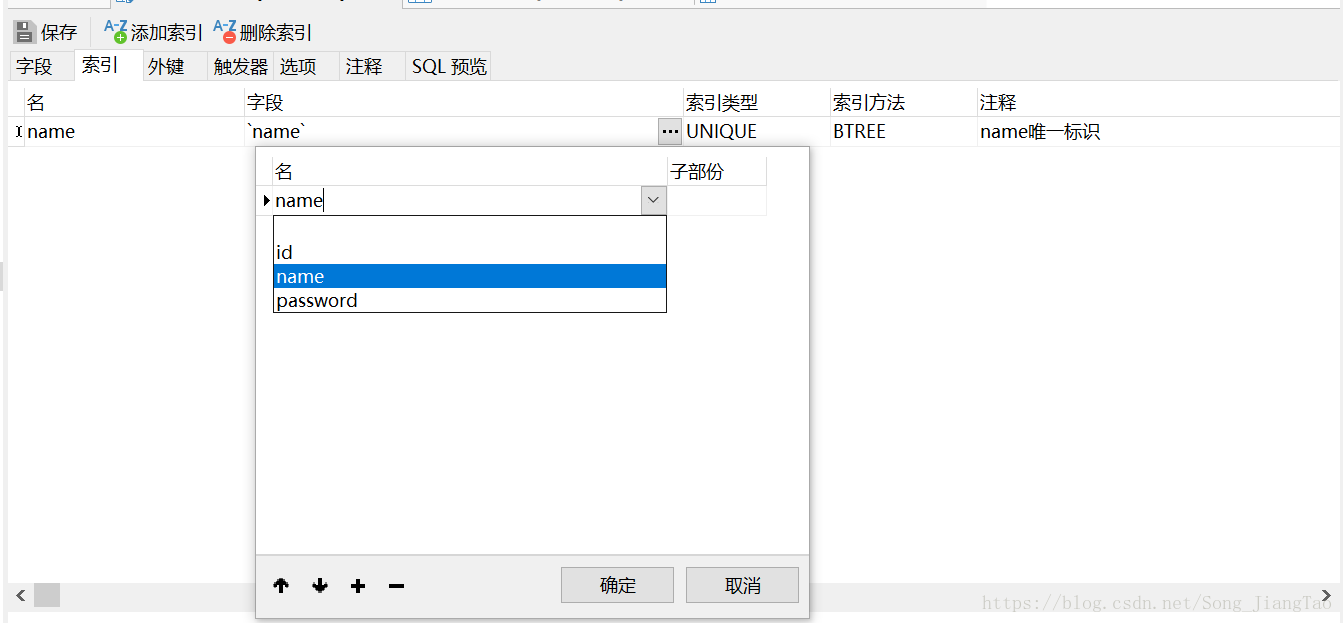
說明:
- 名:索引名
- 欄位:想要設計的那個UNIQUE欄位名,這裡可以選擇,也可以直接輸入
- 索引型別:當然是選擇UNIQUE啦
- 索引方法:可以不寫,預設如圖
- 註釋:就是註釋啦
4、點選左上角的儲存。
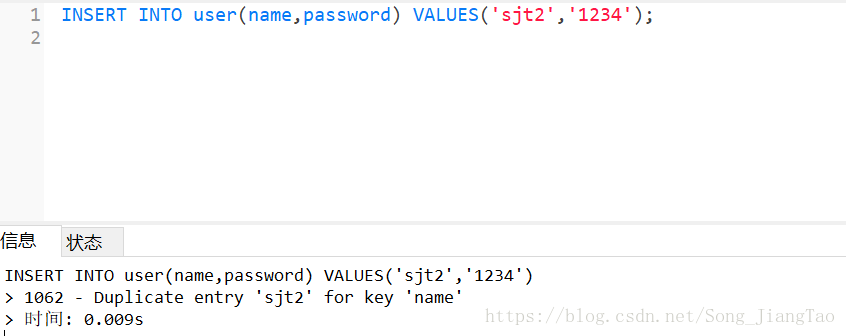
5、測試,當你插入相同name值的記錄時,就會報出如下錯誤
相關推薦
Navicat Premium怎麼設定欄位的唯一性(UNIQUE)?
1、開啟你想要設計的表 2、清楚你想要設計哪個欄位為唯一的,例如我這裡是設計name欄位唯一,然後點選索引 3、然後設定相關內容 說明: 名:索引名 欄位:想要設計的那個U
pymysql獲取要查詢的欄位名(列名)
使用pymysql連線資料庫進行查詢時,獲取的只是查詢的結果,並不包含列名。 可以使用cursor.description來獲取列名的相關資訊。執行結果如下所示。 #!/usr/bin/env/python # -*- coding:utf-8 -*- import pymysql
解析ArcGis的欄位計算器(二)——有玄機的要素Geometry屬性,在屬性表就能查出孔洞、多部件
ArcGis裡多部件要素一般有兩種,一種是孔洞、一種是Merge在一起的兩個面。有時候為了便於賦屬性或者其他的一些原因,我們在操作中會故意Merge一些本不在一起的面,造成上述的第二種情況。藉助欄位計算器可以在屬性表中直接把它們標識出來,信不?注:以下語句需要使用Python解析。先上!shape.isMul
解析ArcGis的欄位計算器(三)——文字型欄位計算,編號那些事兒
實際操作中我們一般會將編號欄位定義為文字型,因為編號不是序號,序號是一個遞增數值,而編號往往是一個數字串程式碼。1、怎麼編號?最簡單的編號—>直接在編號欄位使用欄位計算器將FID欄位值+1計算過來便是。 BH=[FID]+1 這應該只能叫做序號值,還不夠,還有一個問題需要我們去解決,因為編
C#Winform+AE開發 空間連線(SpatialJoin)以及欄位對映(FieldMapping)(新手記錄)
1,佈局 連線要素的欄位對映控制元件使用的是列表框ListBox 2,獲取目標要素和連線要素 使用兩種方式,一是自動獲取當前地圖載入的圖層 #region 獲取主視窗圖層並新增到控制元件中 &n
postgresql獲取表結構,表名、表註釋、欄位名、欄位型別及長度和欄位註釋(轉載)
轉載地址:https://blog.csdn.net/weixin_38924323/article/details/80982760 場景描述:navicate 將postgresql表結構匯出到Excel。 1、查詢表名和表註釋 select relna
sqlserver 編輯、修改欄位說明(備註) sp_addextendedproperty
0(成功)或 1(失敗) EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'0:取消,1:已到,2:未到,3:預訂違約' ,@level0type=N'SCHEMA', @level0name=N'dbo', @level1
JDBC--獲得ResultSet的記錄個數、欄位個數(轉載)
1.獲得ResultSet的記錄個數 因為ResultSet沒有方法可直接得到記錄數,只有另想方法,可採用如下方法: Statement stmt = conn.createStatement(ResultSet.TYPE_SCROLL_INSE
oracle系統表v$session、v$sql欄位說明(轉)
在本檢視中,每一個連線到資料庫例項中的 session都擁有一條記錄。包括使用者 session及後臺程序如 DBWR, LGWR, arcchiver等等。 V$SESSION中的常用列 V$SESSION是基礎資訊檢視,用於找尋使用者 SID或 SADDR。不過,它也有一些列會動態的變化,可用於檢查
sql server新增、修改欄位語句(整理)
新增欄位的SQL語句的寫法:通用式: alter table [表名] add [欄位名] 欄位屬性 default 預設值 default 是可選引數增加欄位: alter table [表名] add 欄位名 smallint default 0 增加數字欄位,整型,預設值為0alter table [表
欄位解析(3)
物件的定義順序和佈局順序是不一樣的。我們在寫程式碼的時候不用關心記憶體對齊問題,但是如果記憶體按照原始碼定義順序進行佈局的話,由於cpu讀取記憶體時是按暫存器(64位)大小單位載入的,如果載入的資料橫跨兩個64位,要操作該資料的話至少需要兩次讀取,加上組合移位,會產生效率問題,甚至會引發異常。比如在一些ARM
資料庫欄位唯一性約束設定(總結一)
突然看到資料庫表設計中的幾個屬性,記錄一下 restrict--限制,指的是如果字表引用父表的某個欄位的值,那麼不允許直接刪除父表的該值; cascade--級聯,刪除父表的某條記錄,子表中引用該值的記錄會自動被刪除; no action--無參照完整性關係,有了也不生效。
Elasticsearch如何實現篩選功能(設定欄位不分詞和聚合操作)
0 起因 中文分詞中比較常用的分詞器是es-ik,建立索引的方式如下: 這裡我們為index personList新建了兩個欄位:name和district,注意索引名稱必須是小寫 (以下格式都是在kibana上做的) PUT /person_list { "mappings
es站內站內搜尋筆記(一) Mysql 如何設定欄位自動獲取當前時間
es站內站內搜尋筆記(一) 第一節: 概述 使用elasticsearch進行網站搜尋,es是當下最流行的分散式的搜尋引擎及大資料分析的中介軟體,搜房網的主要功能:強大的搜尋框,與百度地圖相結合,實現地圖找房,包括前臺模組和後臺模組。 elasticsearch + mysql +kafka實
navicat mysql查資料庫中表名、表數量,欄位名、欄位數量(持續更新中)
1.查資料庫中表數量 (紅色標記的是常用到的重要的表結構資訊表) mysql> use information_schema;Database changedmysql> show tables;+-------------------------------
Mysql設定欄位自動獲取當前時間
一、應用場景 實際開發中,要記錄每條資料是什麼時候建立的或者記錄每條資料是什麼時候修改的,不需要應用程式去特意記錄,而由資料資料庫獲取當前時間自動記錄修改時間; 二、解決方法 1、將欄位型別設為 TIMESTAMP 2、將預設值設為 CUR
RDD使用程式設計介面方式轉換為DataFrame的工具類(針對欄位特別多的)
在使用Spark-Sql 時,需要把RDD型別轉換為DataFrame,再使用一些SQL操作,在轉換為DataFrame時有兩種方式一種是通過反射方式,一種是通過程式設計介面方式 程式設計介面的方式比較常用,但是這種方式程式碼量可能比較大,特別是在你的欄位特別多的時候,你需要先把RDD中的型
navicat premium 12 破解版下載(百度雲盤)
最近發現網上的一些 破解版的 navicat 下載地址都被 河蟹了,還好之前我儲存了一份到百度雲裡面。現在共享出來,方便開發人員除錯。 該版本是64位的簡體中文版,破解補丁請選擇 64位簡中 安裝包和破解補丁: https://pan.baidu.com/s
excel oracle欄位命名(大寫下劃線分詞)轉 駝峰命名
(帕斯卡) =LEFT(C251,1)&MID(SUBSTITUTE(PROPER(C251),"_",""),2,100) (駝峰) =LOWER(LEFT(A:A,1))&MID(SUBSTITUTE(PROPER(A:A),"_",""),2,10
shell命令以及執行原理、檢視或修改掩碼(umask)、Linux許可權管理、Linux設定檔案訪問許可權(chmod)、粘滯位、修改檔案的擁有者(chown)、修改檔案的所屬組(chgrp)
shell命令以及執行原理: Linux嚴格意義上說的是一個作業系統,我們稱之為”核心”,但是我們普通使用者,不能直接使用核心,而是通過核心的”外殼”程式,也就是所謂的shell,來與核心溝通。 Linux中的命令大多數都是可執行程式。但其實捕捉我們