
分散式架構的演進過程
一、計算機的基石——馮諾依曼模型
馮·諾依曼於1946年提出儲存程式原理,把程式本身當作資料來對待,程式和該程式處理的資料用同樣的方式儲存。 馮·諾依曼體系結構馮·諾依曼理論的要點是:計算機的數制採用二進位制;計算機應該按照程式順序執行。人們把馮·諾依曼的這個理論稱為馮·諾依曼體系結構。
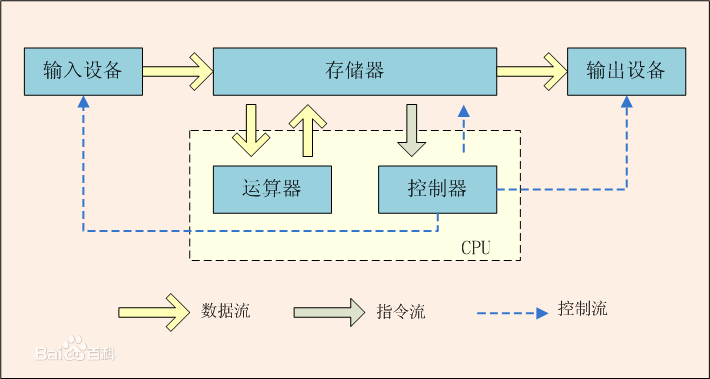
直到現在我們的計算機都屬於這個體系結構,只不過效能大大提升。
二、bigger than bigger——計算機的產生 大型主機時代
世界上第一臺通用計算機“ENIAC”於1946年在美國賓夕法尼亞大學誕生。發明人是美國人莫克利(JohnW.Mauchly)和艾克特(J.PresperEckert)。美國國防部用它來進行彈道計算。它是一個龐然大物,用了18000個電子管,佔地170平方米,重達30噸,耗電功率約150千瓦,每秒鐘可進行5000次運算。 ENIAC之後,電子計算機進入了由IBM這位藍色巨人主導的大型機時代。
大型機之父 吉恩 阿姆達爾在1964年4月7日,製造出第一臺IBM大型機SYSTEM/360,使得IBM在20世紀50-60年代統治整個大型計算機工業。

由於大型機高可靠性和超強的計算能力,即使在X86架構和雲端計算飛速發展的情況下,IBM大型機仍然牢牢佔據著一定的高階市場份額。
在20世紀80年代時,計算機架構同時向兩個方向發展:
(1) 以CISC(微處理器執行的計算機語言指令集)CPU為架構 價格比較便宜 面向個人的計算機(PC)
(2)以RISC(精簡指令集計算機)CPU為架構 架構昂貴 面向企業的小型UNIX 伺服器
之後,雖然大型主機具備超強的計算和I/O處理能力,並且擁有很好的穩定性和安全性。
但是,這種架構日益難以適應人們的需求:
(1)大型機的複雜性,使得其運維人員的培養成本很高
(2)大型機很貴,一般人或者企業根本玩不起,基本上只有政府或者大型國企才能弄一臺
(3)單點問題 一臺大型主機故障,則整個系統癱瘓
(4)PC的效能不斷提升,許多企業完全不必要再使用大型機來搭建系統架構
三、分散式的意義和常見概念
分散式系統的意義
1、升級單機處理效能的價效比越來越低
單機處理能力主要依靠CPU、記憶體和磁碟,通過更換硬體做垂直擴充套件來提升效能的代價越來越高
2、單機處理能力存在瓶頸
3、單機系統存在穩定性和可用性問題
下面以飯店為例,來解釋常見概念
叢集
從前有一個小飯店,客少店小,因此只有一個廚師,而且除了炒菜,洗菜切菜也得自己來,然後客人逐漸多了起來,這時候就多招了兩個廚師,這個廚師也是炒菜洗菜切菜什麼都幹,這三個廚師的關係,就叫做叢集。
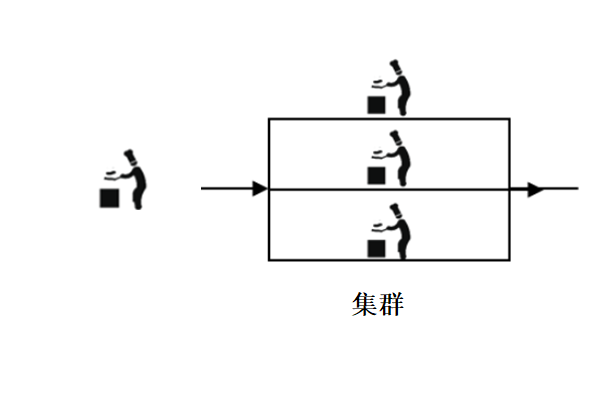
分散式
小飯店生意越來越好了,為了增加效率,專人幹專事,給每一位廚師配一個配菜員一個切菜員,這個時候廚師和配菜師 切菜員是分散式的關係,而配菜師與配菜師之間的關係還是叢集
在這個過程中,一個配菜師因故請假了,但是其餘的配菜師還是該啥就幹啥,可能沒請假的配菜師任務會被均勻的加量了,但是他們的任務和職責是不變的

節點
節點是指一個可以獨立按照分散式完成一組邏輯的程式個體。在具體的專案中,一個節點表示的是一個作業系統上的程序。
副本機制
副本(replica/copy)指在分散式系統中為資料或服務提供的冗餘。
資料副本指在不同的節點上持久化同一份資料,當出現某一個節點的資料丟失時,可以從副本上讀取到資料。資料副本是分散式系統中解決資料丟失問題的唯一手段。
服務副本表示多個節點提供相同的服務,通過主從關係來實現服務的高可用方案
中介軟體
中介軟體位於作業系統提供的服務之外,又不屬於應用,他是位於應用和系統層之間為開發者方便的處理通訊,輸入輸出的一類軟體,能夠讓使用者關心自己應用的部分。
即:分散式:一個業務拆分為多個子業務,部署在不同的伺服器上
叢集:同一個業務,部署在多個伺服器上
分散式結構:將一個完整的系統,按照業務功能,拆分成一個個獨立的子系統,在分散式結構中,每個子系統就被稱為"服務"。這些子系統能夠獨立執行在web容器中,他們之間通過RPC方式通訊。
下面我們將電商系統為例,詳細介紹分散式發展過程
假設我們的電商系統中只有三個模組:使用者模組,交易模組和商品模組
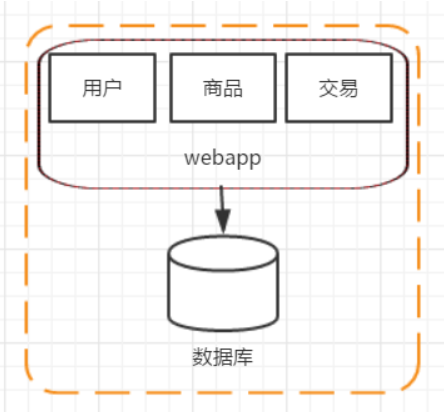
階段一:單應用架構
在網站建立初期,經常把所有的東西都在一臺機器上部署,這個時候的架構是單應用架構,優點是效率非常高
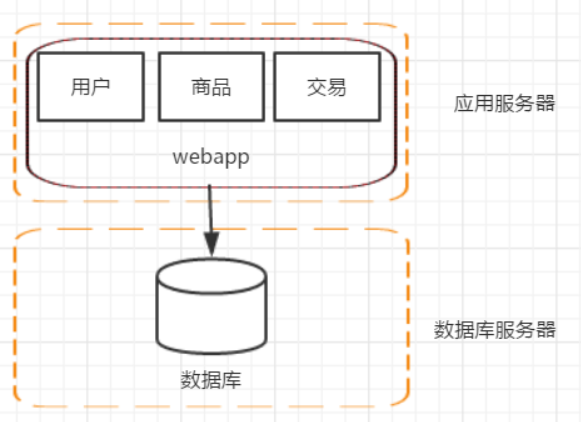
階段二:應用伺服器和資料庫伺服器分離
網站上線了,隨著時間推移,訪問量開始逐漸增大,伺服器逐漸的就扛不住了,這個時候就要考慮加機器了,這就進入了第二階段。
這個階段增加機器的主要目的是將web伺服器和資料庫伺服器進行拆分,這樣不僅提高了單機的負載能力,也提高了容災能力
第三階段:應用伺服器叢集
然而隨著訪問量的持續增加,單臺伺服器已經無法滿足需求。假設資料庫伺服器的還未遇到效能問題
此時可以增加應用伺服器,這就進入第三階段——應用伺服器叢集。
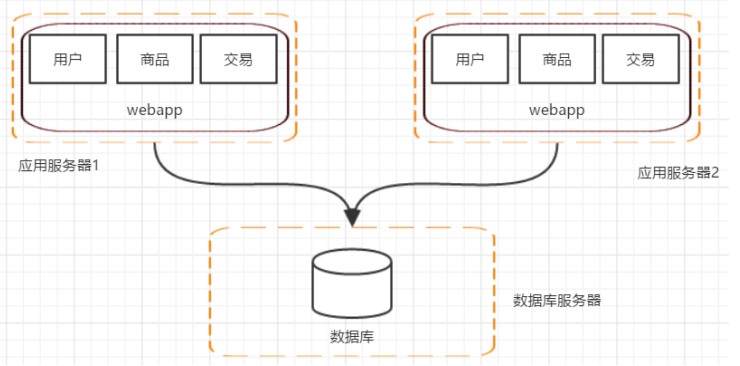
在這個階段有些問題就逐漸顯現出來了,比如:
(1)使用者的請求該由哪一臺機器進行處理? ——負載均衡(F5/apache/nginx)
(2)如果使用者每次請求的機器不同,那麼session如何維護?
1、session同步
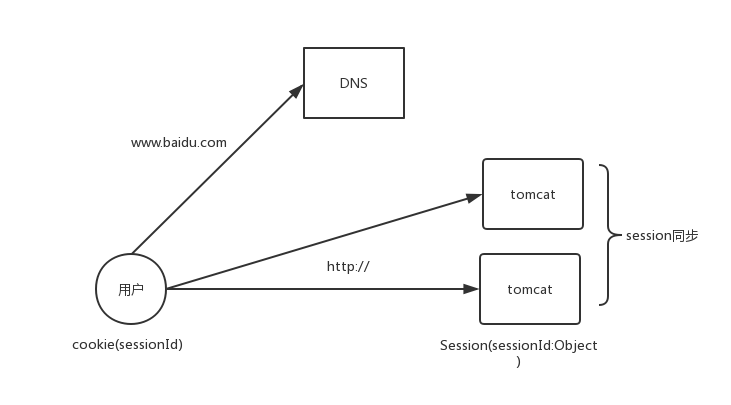
2、通過第三方儲存(redis等)儲存session
3、跳過容器物件
這樣架構就變為了以下模式。
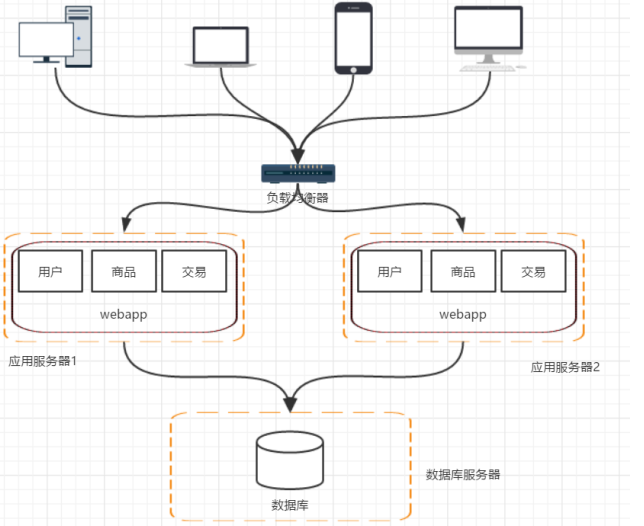
階段四:資料庫讀寫分離
隨著業務量進一步增加,資料庫伺服器的I/O能力會存在瓶頸。
首先考慮的是加機器,但是如果直接一分為二,每次讀寫還要額外判斷資料應該在哪臺機器上。
基於電商系統資料庫讀多寫少的特點,可以將一個伺服器作為寫庫,另一個庫設為讀庫,並設定主從同步進行複製。
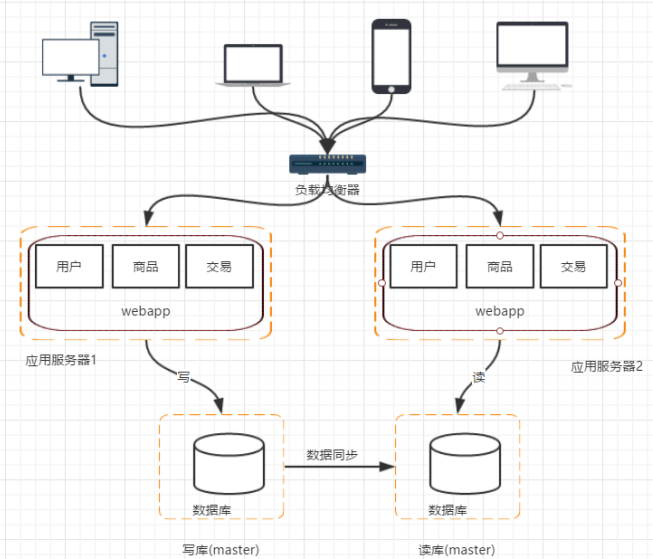
這樣也會帶來資料庫不一致的問題
1.主從資料庫之間的資料同步;可以使用mysql自帶的master-slave方式實現主從複製
2.對應資料來源的選擇;採用第三方資料庫中介軟體,例如mycat
實際上,如果讀庫的量遠大於寫庫的訪問量,需要設定多個讀庫時,可以採取以下的結構
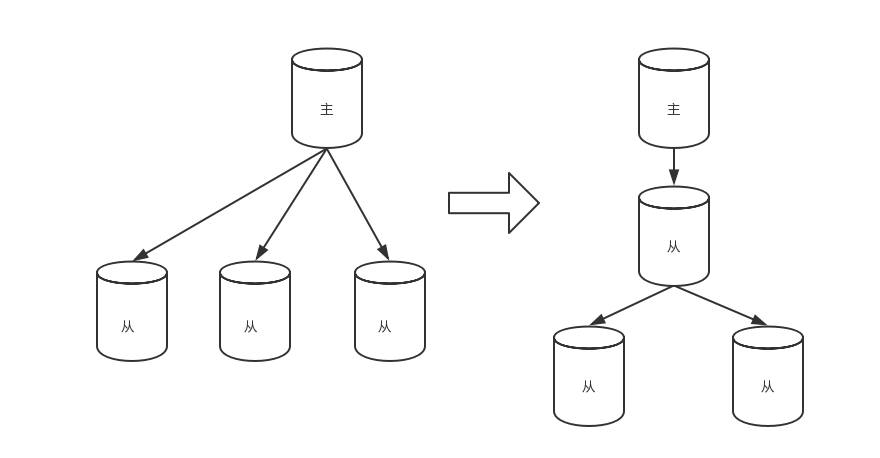
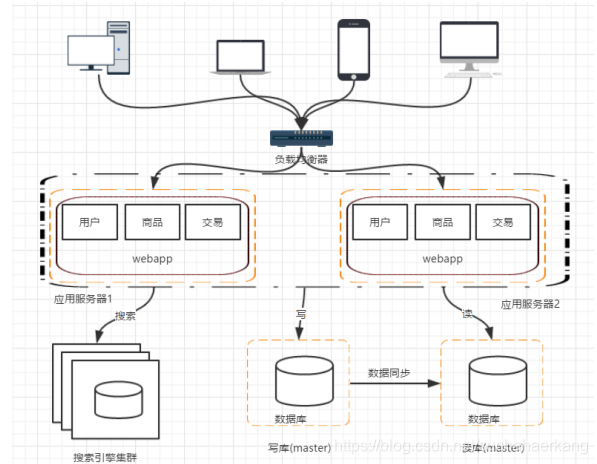
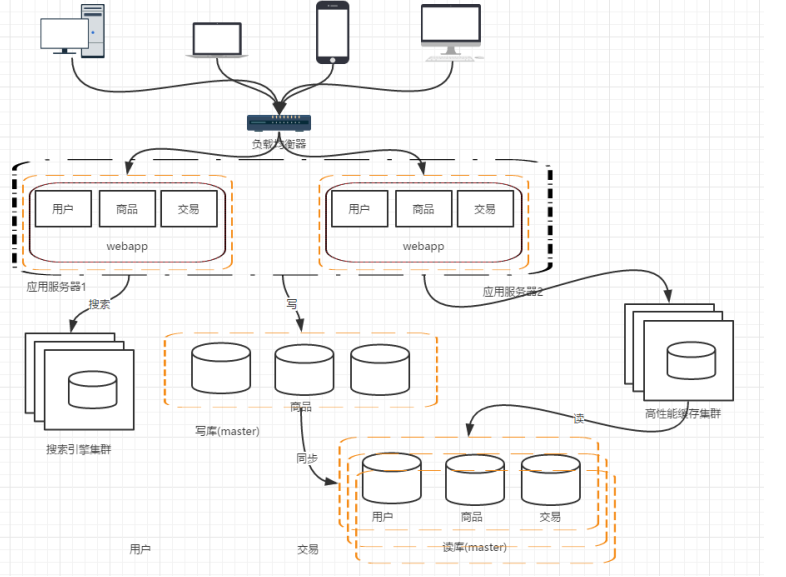
階段五:使用搜索引擎緩解讀庫的壓力
資料庫做讀庫的話,常常對模糊查詢效率不是特別好,像電商類的網站,搜尋是非常核心的功能,即便是做了讀寫分離,這個問題也不能有效的解決。那麼這個時候就需要引入搜尋引擎了。
使用搜索引擎能夠大大提高我們的查詢速度,但是同時也會帶來一些附加的問題,比如維護索引構建。
階段六:引入快取機制
隨著訪問量的持續增加,逐漸出現許多使用者訪問統一部分內容的情況,對於這些熱點資料,沒必要每次都從資料庫去讀取,我們可以使用快取技術,比如memcache,redis來作為我們應用層的快取;另外在某寫場景下,比如我們對使用者的某些IP的訪問頻率做限制,那這個放記憶體中又不合適,放資料庫又太麻煩,這個時候可以使用Nosql的方式比如mongDB來代替傳統的關係型資料庫。
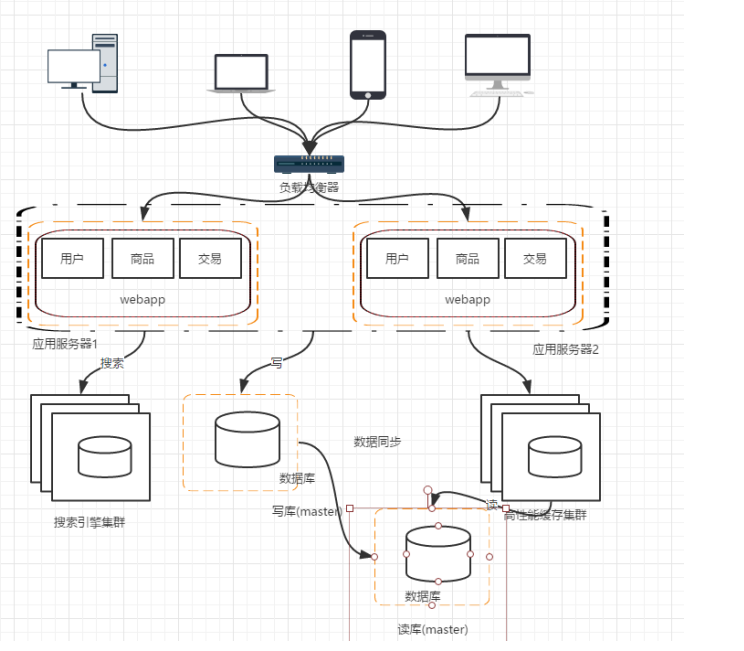
至此,分散式架構的基本框架已經形成。
階段七:資料庫的水平、垂直拆分
資料庫永遠是最容易造成瓶頸的地方之一,例如阿里巴巴09年“去IOE運動”就是為了解決資料庫擴充套件性瓶頸問題。
在整個架構的編號過程中,所有的資料還是在同一個資料庫中的,因此我們可以考慮對資料進行拆分
其中:
垂直拆分就是把不同業務的資料拆分到不同的資料庫中
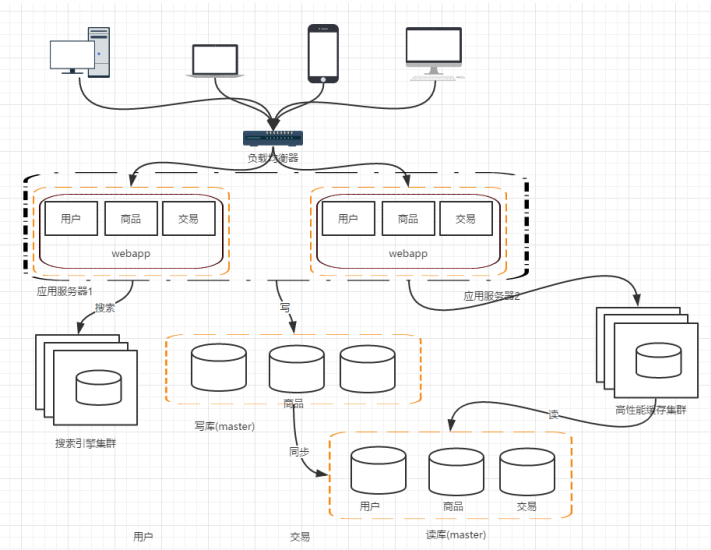
水平拆分則是把同一個表中的資料拆分到兩個甚至更多的資料庫中,有些公司的資料庫是按照日期分為31*N個數據庫
階段七:應用拆分階段
隨著需求的不斷提出,應用的體量也越來越大,因此需要按照領域對業務進行拆分