
ELMo模型的理解與實踐(1)
阿新 • • 發佈:2018-12-18
論文:2018 NAACL 《Deep Contextualized Word Representations》
一、優點
1.學習單詞的複雜特徵,包括語法、語義
2.學習在不同上下文下的一詞多義
二、模型
1.Bidirectional language models(BLM)
首先給定N個單詞的序列,
1)前向語言模型,已知前k-1個單詞 ,預測第k個單詞
的概率:

2)後向語言模型,已知下文 ,預測第k個單詞
:
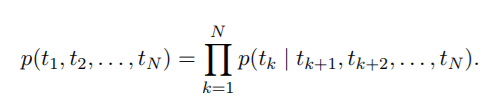
雙向語言模型(biLM)即將前向和後向語言模型聯合起來,並最大化前後向語言模型的聯合似然函式:
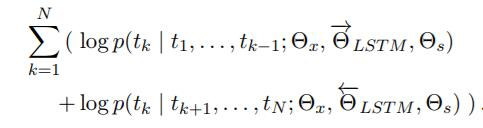
其中,公式中有兩個LSTM 單元, \theta_{x} 為輸入的初始詞向量引數,
\theta_{s} 為輸出的softmax層引數(即,在LSTM的每一個步長輸出的隱藏層h,再作為softmax的輸入)。
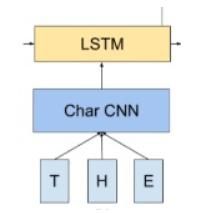
2. char-level(CNN) 初始詞向量
在第一點中輸入的初始詞向量通過 char-level(CNN)獲得(即,對單詞內的字元通過CNN卷積操作得到詞向量),如下圖:
3. ELMo
ELMo為多個雙向語言模型biLM的多層表示
對於某一個單詞t_k,一個L層的雙向語言模型biLM由2L+1個向量表示:
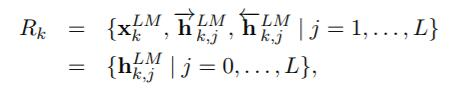
為char-level初始詞向量,前後向
![]()
再將 R_{k} 向量正則化後,輸入softmax層,作為學到的一組權重

結構如下圖所示
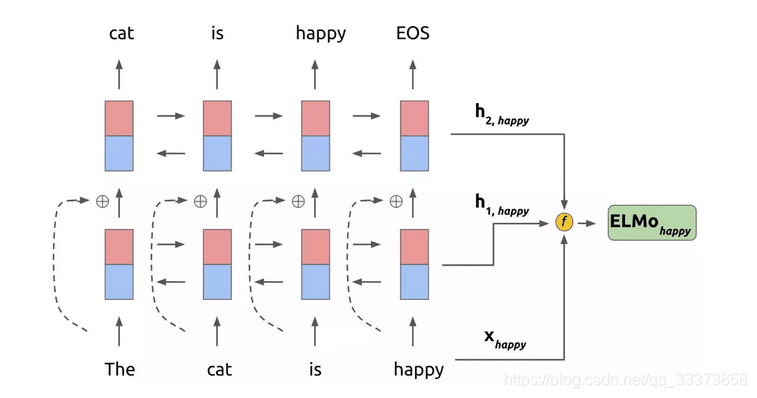
三、ELMo詞向量在NLP任務中的使用
1.和初始詞向量
(char-level詞向量)直接拼接

2. 和隱藏層輸出
直接拼接

四、理解
即char-level+多層BLM的組合,再將輸出向量整合為權值
解決了多義性(char-level)和上下文語義(bi-lstm)的問題