
GloVe模型的理解及實踐(2)
阿新 • • 發佈:2018-11-10
一、執行環境
Ubuntu16.04 + python 3.5
二、安裝gensim
兩種安裝方式
1)開啟終端
sudo easy_install --upgrade gensim2)開啟終端
pip install gensim三、Git官方GitHub程式碼
https://github.com/stanfordnlp/GloVe
四、生成詞向量
1.在glove檔案下開啟終端進行編譯:
make編譯後生成 bin 資料夾,資料夾內有四個檔案:
Readme中有關於四個檔案的介紹。
1)vocab_count:計算原文字的單詞統計(生成vocab.txt檔案)
格式為“單詞 詞頻”如下圖:

2)cooccur:用於統計詞與詞的共現(生成二進位制檔案 cooccurrence.bin )
3)shuffle:生成二進位制檔案 cooccurrence.shuf.bin
4)glove:Glove演算法的訓練模型,生成vectors.txt和vectors.bin
2.執行 sh demo.sh
sh demo.sh 如下圖,下載預設語料庫並訓練模型:

最後得到 vectors.txt

五、詞向量生成模型並載入
1.在目錄下建一個 load_model.py 檔案,程式碼如下
#!usr/bin/python # -*- coding: utf-8 -*- import shutil import gensim def getFileLineNums(filename): f = open(filename,'r') count = 0 for line in f: count += 1 return count def prepend_line(infile, outfile, line): """ Function use to prepend lines using bash utilities in Linux. (source: http://stackoverflow.com/a/10850588/610569) """ with open(infile, 'r') as old: with open(outfile, 'w') as new: new.write(str(line) + "\n") shutil.copyfileobj(old, new) def prepend_slow(infile, outfile, line): """ Slower way to prepend the line by re-creating the inputfile. """ with open(infile, 'r') as fin: with open(outfile, 'w') as fout: fout.write(line + "\n") for line in fin: fout.write(line) def load(filename): # Input: GloVe Model File # More models can be downloaded from http://nlp.stanford.edu/projects/glove/ # glove_file="glove.840B.300d.txt" glove_file = filename dimensions = 50 num_lines = getFileLineNums(filename) # num_lines = check_num_lines_in_glove(glove_file) # dims = int(dimensions[:-1]) dims = 50 print num_lines # # # Output: Gensim Model text format. gensim_file='glove_model.txt' gensim_first_line = "{} {}".format(num_lines, dims) # # # Prepends the line. #if platform == "linux" or platform == "linux2": prepend_line(glove_file, gensim_file, gensim_first_line) #else: # prepend_slow(glove_file, gensim_file, gensim_first_line) # Demo: Loads the newly created glove_model.txt into gensim API. model=gensim.models.KeyedVectors.load_word2vec_format(gensim_file,binary=False) #GloVe Model model_name = gensim_file[6:-4] model.save('./' + model_name) return model #load(glove.6B.300d.txt)#生成模型 if __name__ == '__main__': myfile=open('vectors.txt') myfile.read() #################################### model_name='model\.6B.300d' model = gensim.models.KeyedVectors.load('./'+model_name) print len(model.vocab) word_list = [u'girl',u'dog'] for word in word_list: print word,'--' for i in model.most_similar(word, topn=10): print i[0],i[1] print ''
在目錄下終端執行
python load_model.py 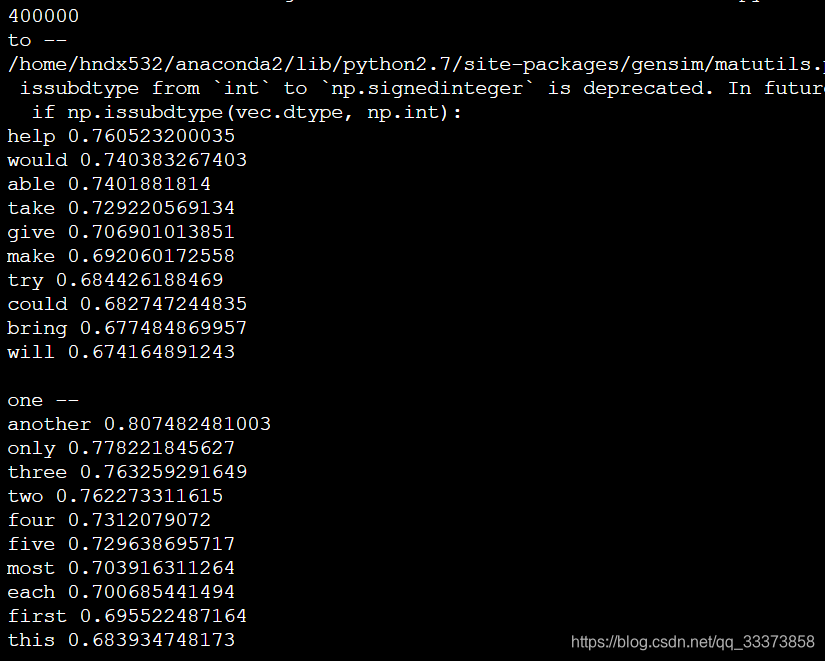
以上輸出結果為:
詞彙行數:400000
以及與 word_list = [u'girl',u'dog'] 最相近的Top 10 單詞
六、測試
測試程式碼如下:
import shutil
import gensim
model_name='model\.6B.300d'
model = gensim.models.KeyedVectors.load('./'+model_name)
print len(model.vocab)
word_list = [u'person',u'pet']
for word in word_list:
print word,'--'
for i in model.most_similar(word, topn=10):
print i[0],i[1]
print '' 結果:
person --
someone 0.690635979176
man 0.64434415102
anyone 0.627825558186
woman 0.617089629173
one 0.591174006462
actually 0.579971313477
persons 0.577681422234
people 0.571225821972
else 0.562521100044
somebody 0.560000300407
pet --
pets 0.686407566071
dog 0.629159927368
cat 0.58703649044
dogs 0.545046746731
cats 0.526196360588
animal 0.516855597496
animals 0.507143497467
puppy 0.486273795366
toy 0.430860459805
rabbits 0.420677244663