專案實戰--知識圖譜初探
實踐了下怎麼建一個簡單的知識圖譜,兩個版本,一個從 0 開始(start from scratch),一個在 CN-DBpedia 基礎上補充,把 MySQL,PostgreSQL,Neo4j 資料庫都嘗試了下。自己跌跌撞撞摸索可能踩坑了都不知道,歡迎討論。
CN-DBpedia 構建流程
知識庫可以分為兩種型別,一種是以 Freebase,Yago2 為代表的 Curated KBs,主要從維基百科和 WordNet 等知識庫中抽取大量的實體及實體關係,像是一種結構化的維基百科。另一種是以 Stanford OpenIE,和我們學校 Never-Ending Language Learning (NELL) 為代表的 Extracted KBs,直接從上億個非結構化網頁中抽取實體關係三元組。與 Freebase 相比,這樣得到的知識更加多樣性
下面以 CN-DBpedia 為例看下知識圖譜大致是怎麼構建的。

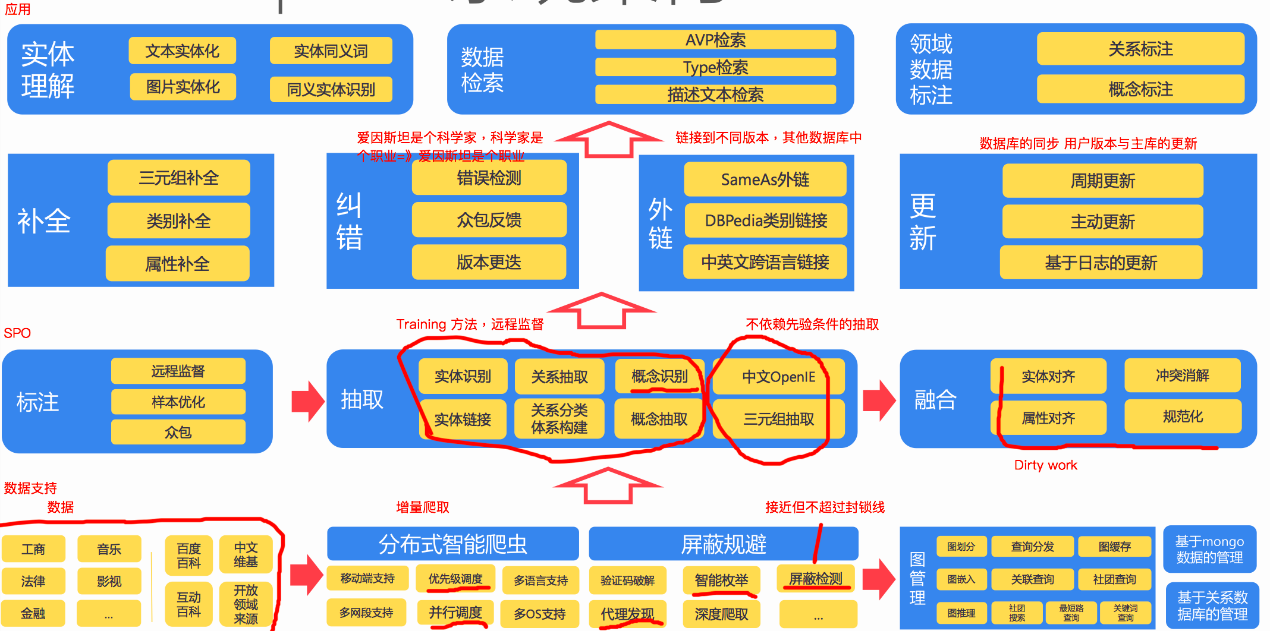
上圖分別是 CN-DBpedia 的構建流程和系統架構。知識圖譜的構建是一個浩大的工程,從大方面來講,分為知識獲取、知識融合、知識驗證、知識計算和應用幾個部分,也就是上面架構圖從下往上走的一個流程,簡單來走一下這個流程。
資料支援層
最底下是知識獲取及儲存,或者說是資料支援層,首先從不同來源、不同結構的資料中獲取
至於資料儲存,要考慮的是選什麼樣的資料庫以及怎麼設計 schema。選關係資料庫還是NoSQL 資料庫?要不要用記憶體資料庫?要不要用圖資料庫?這些都需要根據資料場景慎重選擇。CN-DBpedia 實際上是基於 mongo 資料庫,參與開發的謝晨昊提到,一般只有在基於特定領域才可能會用到圖資料庫,就知識圖譜而言,基於 json(bson) 的 mongo 就足夠了。用到圖查詢的領域如徵信,一般是需要要找兩個公司之間的關聯交易,會用到最短路徑/社群計算等。
schema 的重要性不用多說,高質量、標準化的 schema 能有效降低領域資料之間對接的成本。我們希望達到的效果是,對於任何資料,進入知識圖譜後後續流程都是相同的。換言之,對於不同格式、不同來源、不同內容的資料,在接入知識圖譜時都會按照預定義的 schema 對資料進行轉換和清洗,無縫使用已有元資料和資源。
知識融合層
我們知道,目前分佈在網際網路上的知識常常以分散、異構、自治的形式存在,另外還具有冗餘、噪音、不確定、非完備的特點,清洗並不能解決這些問題,因此從這些知識出發,通常需要融合和驗證的步驟,來將不同源不同結構的資料融合成統一的知識圖譜,以保證知識的一致性。所以資料支援層往上一層實際上是融合層,主要工作是對獲取的資料進行標註、抽取,得到大量的三元組,並對這些三元組進行融合,去冗餘、去衝突、規範化,
第一部分 SPO 三元組抽取,對不同種類的資料用不同的技術提取
- 從結構化資料庫中獲取知識:D2R
難點:複雜表資料的處理 - 從連結資料中獲取知識:圖對映
難點:資料對齊 - 從半結構化(網站)資料中獲取知識:使用包裝器
難點:方便的包裝器定義方法,包裝器自動生成、更新與維護 - 從文字中獲取知識:資訊抽取
難點:結果的準確率與覆蓋率
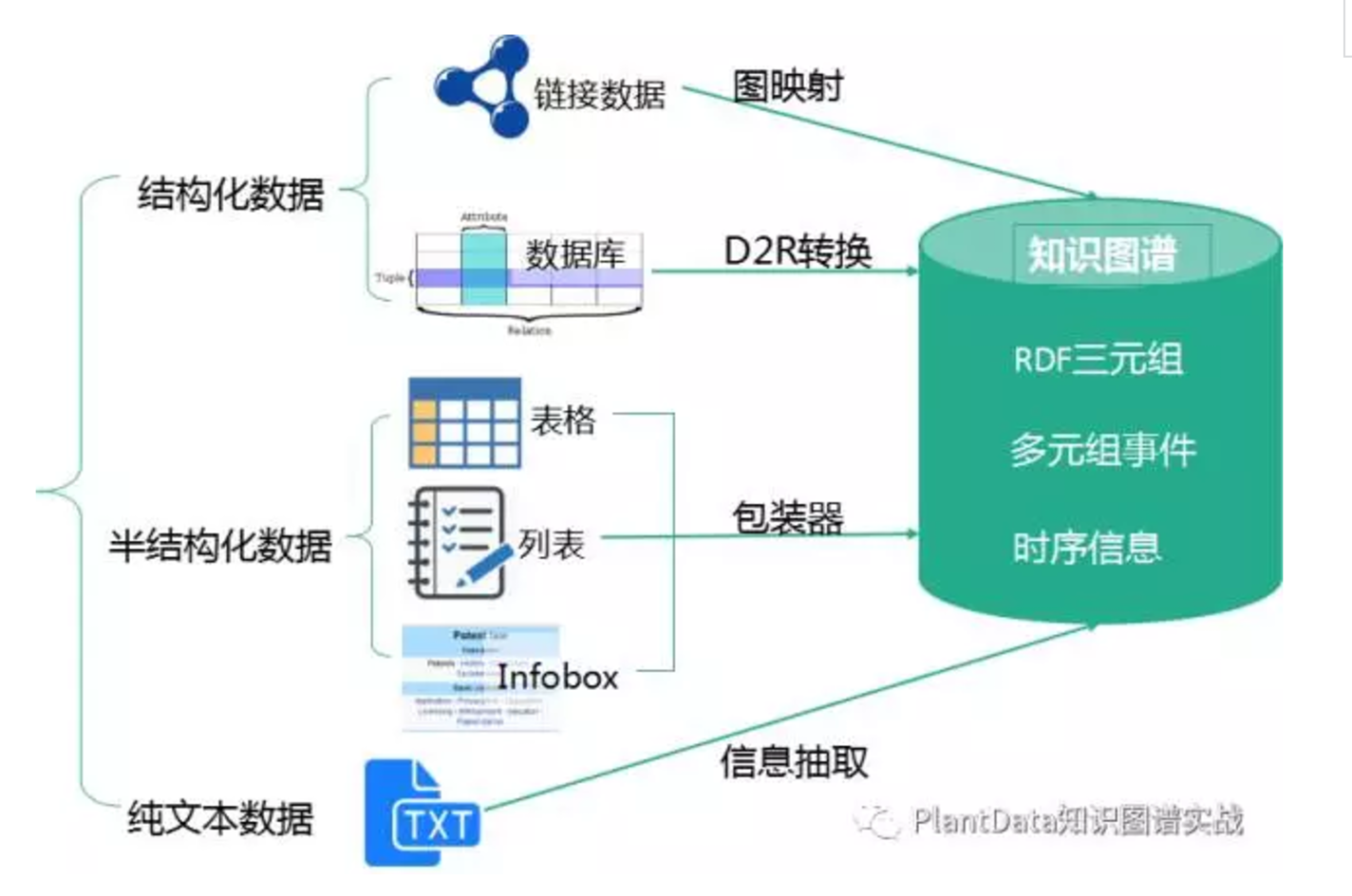
尤其是純文字資料會涉及到的 實體識別、實體連結、實體關係識別、概念抽取 等,需要用到許多自然語言處理的技術,包括但不僅限於分詞、詞性標註、分散式語義表達、篇章潛在主題分析、同義詞構建、語義解析、依存句法、語義角色標註、語義相似度計算等等。
第二部分才到融合,目的是將不同資料來源獲取的知識進行融合構建資料之間的關聯。包括 實體對齊、屬性對齊、衝突消解、規範化 等,這一部分很多都是 dirty work,更多的是做一個數據的對映、實體的匹配,可能還會涉及的是本體的構建和融合。最後融合而成的知識庫存入上一部分提到的資料庫中。如有必要,也需要如 Spark 等大資料平臺提供高效能運算能力,支援快速運算。
知識融合的四個難點:
- 實現不同來源、不同形態資料的融合
- 海量資料的高效融合
- 新增知識的實時融合
- 多語言的融合
知識驗證
再往上一層主要是驗證,分為補全、糾錯、外鏈、更新各部分,確保知識圖譜的一致性和準確性。一個典型問題是,知識圖譜的構建不是一個靜態的過程,當引入新知識時,需要判斷新知識是否正確,與已有知識是否一致,如果新知識與舊知識間有衝突,那麼要判斷是原有的知識錯了,還是新的知識不靠譜?這裡可以用到的證據可以是權威度、冗餘度、多樣性、一致性等。如果新知識是正確的,那麼要進行相關實體和關係的更新。
知識計算和應用
這一部分主要是基於知識圖譜計算功能以及知識圖譜的應用。知識計算主要是根據圖譜提供的資訊得到更多隱含的知識,像是通過本體或者規則推理技術可以獲取資料中存在的隱含知識;通過連結預測預測實體間隱含的關係;通過社群計算在知識網路上計算獲取知識圖譜上存在的社群,提供知識間關聯的路徑……通過知識計算知識圖譜可以產生大量的智慧應用如專家系統、推薦系統、語義搜尋、問答等。
知識圖譜涉及到的技術非常多,每一項技術都需要專門去研究,而且已經有很多的研究成果。Anyway 這章不是來論述知識圖譜的具體技術,而是講怎麼做一個 hello world 式的行業知識圖譜。這裡講兩個小 demo,一個是 爬蟲+mysql+d3 的小型知識圖譜,另一個是 基於 CN-DBpedia+爬蟲+PostgreSQL+d3 的”增量型”知識圖譜,要實現的是某行業上市公司與其高管之間的關係圖譜。
Start from scratch
資料獲取
第一個重要問題是,我們需要什麼樣的知識?需要爬什麼樣的資料?一般在資料獲取之前會先做個知識建模,建立知識圖譜的資料模式,可以採用兩種方法:一種是自頂向下的方法,專家手工編輯形成資料模式;另一種是自底向上的方法,基於行業現有的標準進行轉換或者從現有的高質量行業資料來源中進行對映。資料建模都過程很重要,因為標準化的 schema 能有效降低領域資料之間對接的成本。
作為一個簡單的 demo,我們只做上市公司和高管之間的關係圖譜,企業資訊就用公司註冊的基本資訊,高管資訊就用基本的姓名、出生年、性別、學歷這些。然後開始寫爬蟲,爬蟲看著簡單,實際有很多的技巧,怎麼做優先順序排程,怎麼並行,怎麼遮蔽規避,怎麼在遵守網際網路協議的基礎上最大化爬取的效率,有很多小的 trick,之前部落格裡也說了很多,就不展開了,要注意的一點是,高質量的資料來源是成功的一半!
來扯一扯爬取建議:
- 從資料質量來看,優先考慮權威的、穩定的、資料格式規整且前後一致、資料完整的網頁
- 從爬取成本來看,優先考慮免登入、免驗證碼、無訪問限制的頁面
- 爬下來的資料務必儲存好爬取時間、爬取來源(source)或網頁地址(url)
source 可以是新浪財經這類的簡單標識,url 則是網頁地址,這些在後續資料清洗以及之後的糾錯(權威度計算)、外鏈和更新中非常重要
企業資訊可以在天眼查、啟信寶、企查查各種網站查到,資訊還蠻全的,不過有訪問限制,需要註冊登入,還有驗證碼的環節,當然可以過五關斬六將爬到我們要的資料,然而沒這個必要,換別個網站就好。
推薦兩個資料來源:
其中巨潮資訊還可以同時爬取高管以及公告資訊。看一下資料
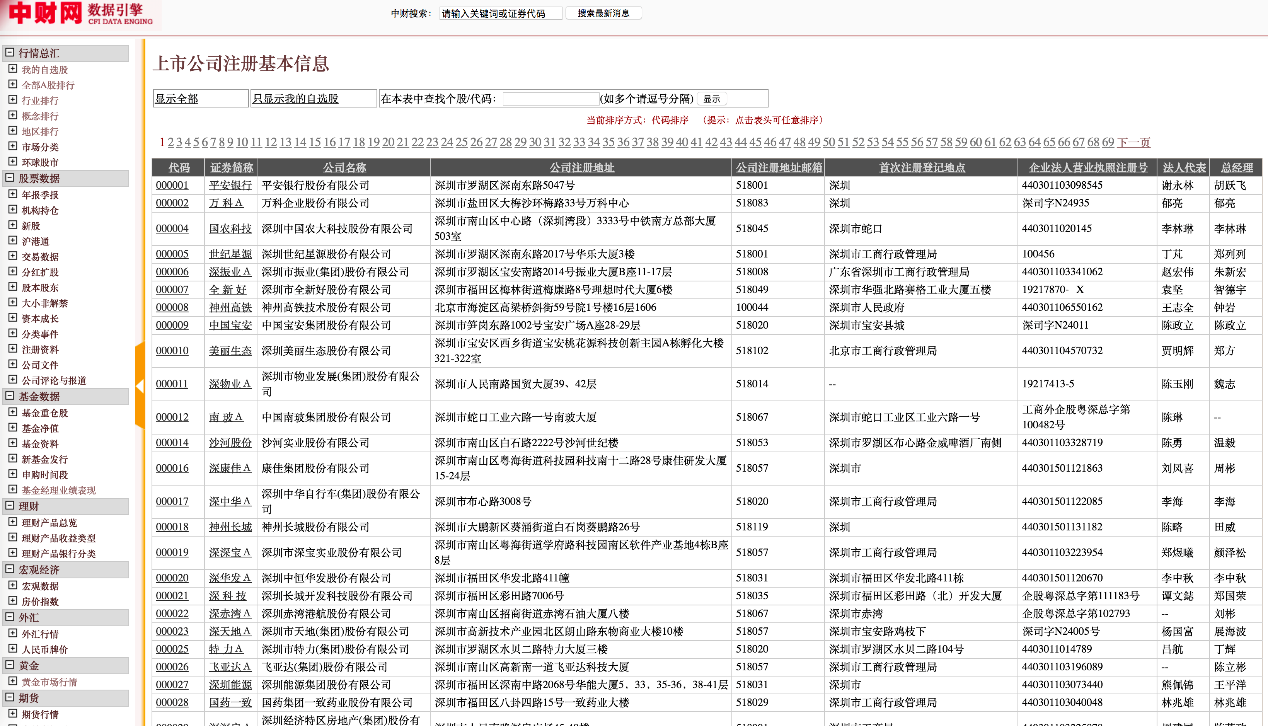
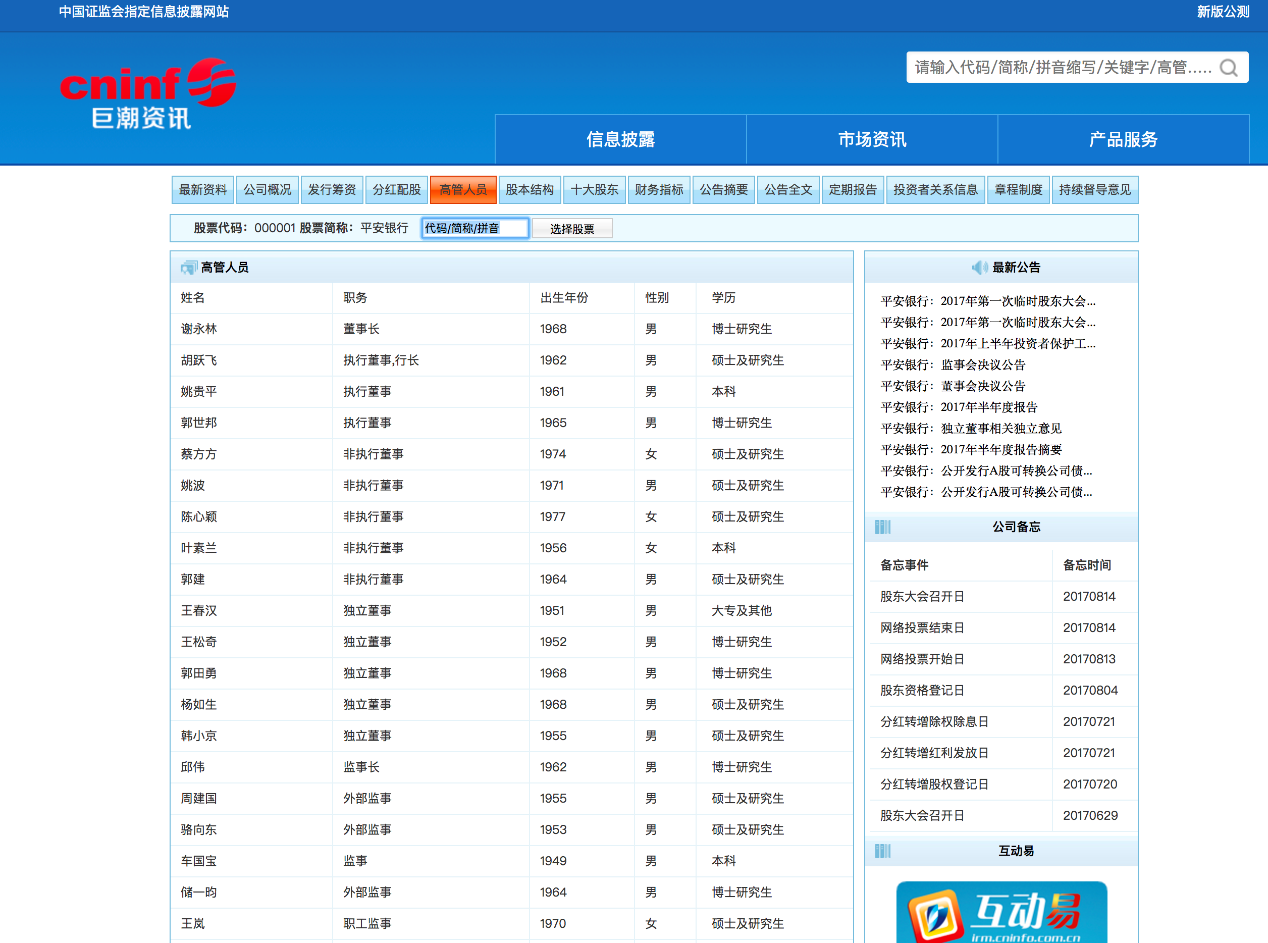
換句話說,我們直接能得到規範的實體(公司、人),以及規範的關係(高管),當然也可以把高管展開,用下一層關係,董事長、監事之類,這就需要做進一步的清洗,也可能需要做關係的對齊。
這裡爬蟲框架我用的是 scrapy+redis 分散式,每天可以定時爬取,爬下來的資料寫好自動化清洗指令碼,定時入庫。
資料儲存
資料儲存是非常重要的一環,第一個問題是選什麼資料庫,這裡作為 starter,用的是關係型資料庫 MySQL。設計了四張表,兩張實體表分別存公司(company)和人物(person)的資訊,一張關係表存公司和高管的對應關係(management),最後一張 SPO 表存三元組。
為什麼爬下來兩張表,儲存卻要用 4 張表?
一個考慮是知識圖譜裡典型的一詞多義問題,相同實體名但有可能指向不同的意義,比如說 Paris 既可以表示巴黎,也可以表示人名,怎麼辦?讓作為地名的 “Paris” 和作為人的 “Paris” 有各自獨一無二的ID。“Paris1”(巴黎)通過一種內在關係與埃菲爾鐵塔相聯,而 “Paris2”(人)通過取消關係與各種真人秀相聯。這裡也是一樣的場景,同名同姓不同人,需要用 id 做唯一性標識,也就是說我們需要對原來的資料格式做一個轉換,不同的張三要標識成張三1,張三2… 那麼,用什麼來區別人呢?拍腦袋想用姓名、生日、性別來定義一個人,也就是說我們需要一張人物表,需要 (name, birth, sex) 來作composite unique key 表示每個人。公司也是相同的道理,不過這裡只有上市公司,股票程式碼就可以作為唯一性標識。
Person 表和 company 表是多對多的關係,這裡需要做 normalization,用 management 這張表來把多對多轉化為兩個一對多的關係,(person_id, company_id) 就表示了這種對映。management 和 spo 表都表示了這種對映,為什麼用兩張表呢?是出於實體對齊的考慮。management 儲存了原始的關係,”董事”、監事”等,而 spo 把這些關係都對映成”高管”,也就是說 management 可能需要通過對映才能得到 SPO 表,SPO 才是最終成型的表。
可能有更簡單的方法來處理上述問題,思考中,待更新—-
我們知道知識庫裡的關係其實有兩種,一種是屬性(property),一種是關係(relation)。那麼還有一個問題是 SPO 需不需要儲存屬性?
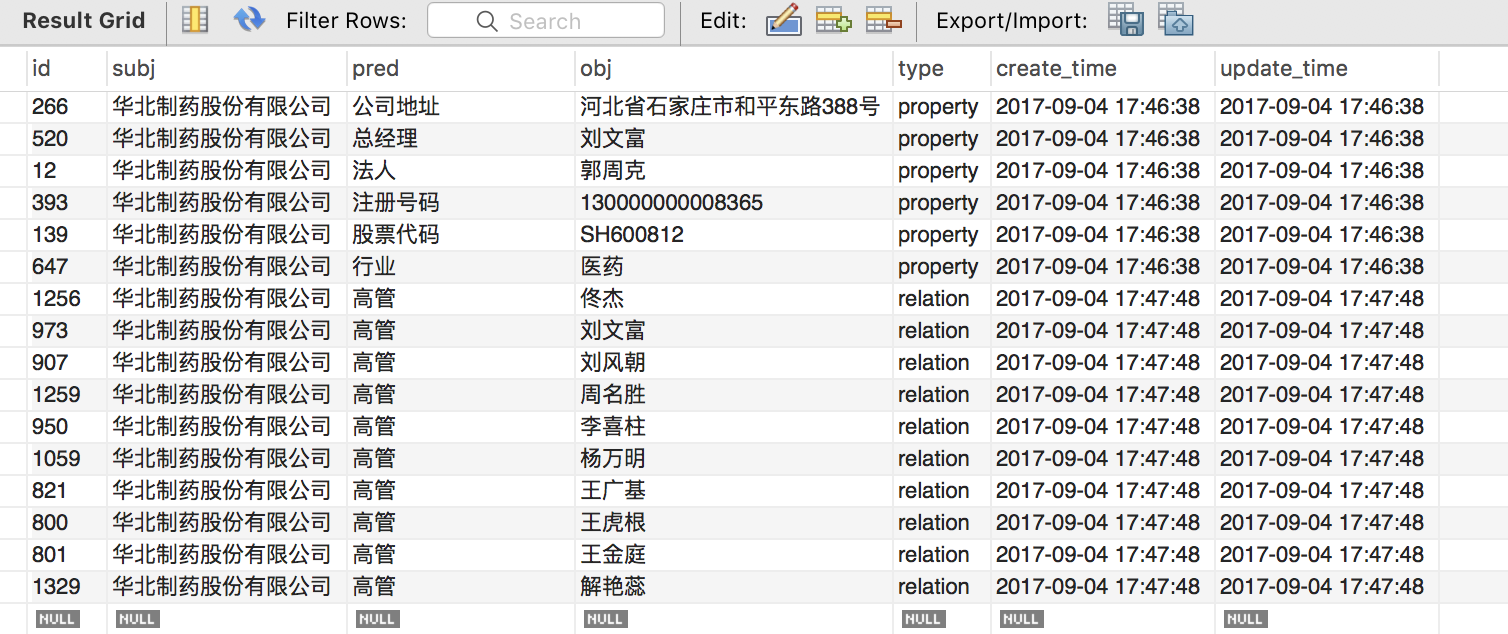
最後要注意的一點是,每條記錄要儲存建立時間以及最後更新時間,做一個簡單的版本控制。
資料視覺化
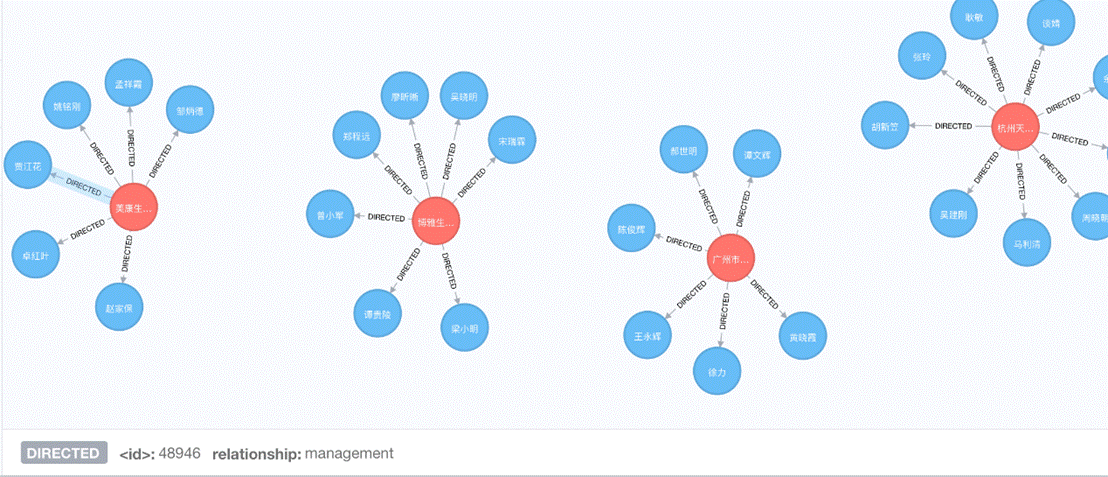
Flask 做 server,d3 做視覺化,可以檢索公司名/人名獲取相應的圖譜,如下圖。之後會試著更新有向圖版本。

Start from CN-DBpedia
把 CN-DBpedia 的三元組資料,大概 6500 萬條,匯入資料庫,這裡嘗試了 PostgreSQL。然後檢索了 112 家上市公司的註冊公司名稱,只有 69 家公司返回了結果,屬性、關係都不是很完善,說明了通用知識圖譜有其不完整性(也有可能需要先做一次 mention2entity,可能它的標準實體並不是註冊資訊的公司名稱,不過 API 小範圍試了下很多是 Unknown Mention)。
做法也很簡單,把前面 Start from scratch 中得到的 SPO 表插入到這裡的 SPO 表就好了。這麼簡單?因為這個場景下不用做實體對齊和關係對齊。
拓展
這只是個 hello world 專案,在此基礎上可以進行很多有趣的拓展,最相近的比如說加入企業和股東的關係,可以進行企業最終控制人查詢(e.g.,基於股權投資關係尋找持股比例最大的股東,最終追溯至自然人或國有資產管理部門)。再往後可以做企業社交圖譜查詢、企業與企業的路徑發現、企業風險評估、反欺詐等等等等。具體來說:
- 重新設計資料模型 引入”概念”,形成可動態變化的“概念—實體—屬性—關係”資料模型,實現各類資料的統一建模
- 擴充套件多源、異構資料,結合實體抽取、關係抽取等技術,填充資料模型
- 展開知識融合(實體連結、關係連結、衝突消解等)、驗證工作(糾錯、更新等)
最後補充一下用 Neo4j 方式產生的視覺化圖,有兩種方法。一是把上面說到的 MySQL/PostgreSQL 裡的 company 表和 person 表存成 node,node 之間的關係由 spo 表中 type == relation 的 record 中產生;二是更直接的,從 spo 表中,遇到 type == property 就給 node(subject) 增加屬性({predicate:object}),遇到 type == relation 就給 node 增加關係((Nsubject) - [r:predicate]-> node(Nobject)),得到下面的圖,移動滑鼠到相應位置就可以在下方檢視到關係和節點的屬性。