
《垃圾回收的演算法與實現》 一
一、GC介紹
1.GC就是為了回收物件,物件是GC的基本單位。一般物件由頭和域組成
(1)頭主要包括物件大小,物件種類和執行GC所需要的資訊。
(2) 物件的域就是物件使用者可訪問的部分。比如c語言的結構體成員,java的類成員。域主要包括兩種指標和非指標。對於java就是引用型別和基本型別。
2.物件存放在堆中
堆是用於動態分配記憶體的一個空間,比如在普通linux程序中使用brk()調整堆的大小,然後使用malloc分配堆記憶體,使用free釋放堆記憶體。在jvm中使用了mmap系統呼叫,採用匿名對映方式在mmap區開闢了一段空間做為java堆,由jvm自己維護堆的分配和回收工作。
3.活動物件和非活動物件
活動物件就是可以通過程式引用的物件就是活動物件,不能通過程式引用的物件就是非活動物件,比如java方法中的區域性變數分配的物件,在方法呼叫完成後,就不可能對這個變數在訪問了,此時的物件就是非活動物件就可以回收。GC需要保留活動物件,回收非活動物件。
4.物件分配
物件分配就是對堆記憶體的分配,記憶體分配演算法有很多種,比如linux核心的夥伴系統,slab,slub演算法,首次適應,最佳適應,jvm的碰撞指標。這裡面除了jvm的碰撞指標其他的都是基於類空閒連結串列法,也就是需要使用一個數據結構維護空閒記憶體區。
5.根
類似於樹的根結點,在GC裡就是指向物件的的指標起點,比如全域性變數,區域性變數,暫存器等。在java中靜態變數,方法中區域性變數都可以為根。

二 、GC標記清除演算法
GC標記清除演算法由兩階段構成標記階段和清除階段,標記階段是把所有的活動物件做上標記,清除階段就是把沒有被標記的物件進行清除。
1.標記階段就是從根節點出發進行遍歷,訪問到的結點做上標記遍歷完成後,就將所有的活物件標記成功。一般使用圖的深度優先搜尋演算法或者廣度優先搜尋演算法。
虛擬碼如下,就是圖的深度優先搜尋
mark_phase() {
for(Root root:roots)
mark(root);
}
mark(Object object) {
if(object.visited == false) {
object.visited = true;
for(Object obj : list(object))
mark(obj);
}
}2.清除階段,需要遍歷整個堆,將未被標記的物件回收,已經被標記的物件清除標記位,為下次GC做準備。清除所需的時間和堆的大小成正比。
三、GC引用計數演算法
引用計數演算法引入了計數器概念,也就是當前物件被引用了多少次,第一次分配初始化為1,然後被引用一次就會遞增,引用解除後就會遞減,減到0就會被回收。python垃圾回收使用了引用計數,linux kernel的驅動開發框架物件分配回收也使用了引用計數。
引用計數會在物件頭新增一個計數器,一般為無符號整形。
在標記清除演算法中,GC模組會在一定條件下觸發,去呼叫gc函式,但是引用計數演算法沒有明確的GC函式,一般會呼叫更新引用的函式。
物件分配虛擬碼如下:
new_obj(size){
obj = pickup_chunk(size, free_list)
if(obj == NULL)
allocation_fail()
else
obj.ref_cnt = 1
return obj
}首先會從空閒連結串列尋找合適的記憶體塊,如果分配成功則將引用計數器設定為1並返回。
更新引用計數器虛擬碼如下:
update_ptr(ptr, obj){
inc_ref_cnt(obj)
dec_ref_cnt(*ptr)
*ptr = obj
}當ptr引用指向物件obj時,需要將obj被引用次數加一,ptr原來指向的物件引用數減一,然後將obj賦值給ptr,此處先將obj引用次數加一,後將ptr次數減一,是為防止ptr原本就指向obj,如果是這種情況,先將ptr-1的話可能會將obj的引用計數器減到0,這樣obj會被回收掉,就會變為了null,發生bug。所以必須先將obj的引用次數+1,然後將ptr指向的物件引用數-1。
inc_ref函式虛擬碼如下:
inc_ref_cnt(obj){
obj.ref_cnt++
}直接將obj的引用次數加一。
dec_ref_cnt函式虛擬碼如下:
dec_ref_cnt(obj){
obj.ref_cnt--
if(obj.ref_cnt == 0)
for(child : children(obj))
dec_ref_cnt(*child)
reclaim(obj)
}首先將obj的引用數減一,如果obj的引用數變為0,此時就需要將obj成員指向的物件引用次數減一,所以此時需要遞迴呼叫dec_ref_cnt。然後回收obj。
引用計數演算法優點:
1.可以即刻被回收。在程式執行中每個物件都知道自己被引用次數,當引用次數變為0時立即被回收,重新加入空閒連結串列。好處就是記憶體沒有垃圾,只分為空閒記憶體和正在使用的記憶體,不存在不再使用但是也不能被分配的垃圾。使得記憶體利用率最高。
2.最大暫停時間短。只有在更新引用時才會暫停應用程式執行。
3.不需要沿根指標查詢。
引用技術演算法缺點:
1.計數器的增減處理繁重,只要涉及引用變更的程式碼,都需要更新計數器,所以需要插入大量更新引用程式碼。
2.計數器需要佔很多位,比如在32位機器中,引用計數器佔32位,可以被2^32次方個物件引用,而這個物件只有2個域,那計數器就會佔用1/3的記憶體。
3.迴圈引用無法回收。
class Person{
string name
Person lover
}
xm = new Person(" 曉明")
baby = new Person(" baby ")
xm.lover = baby
baby.lover = xm //圖中第一個圖
taro = null
hanako = null //第二個圖
物件A的成員指向了物件B,物件B的成員指向看物件A,根中有引用變數指向了兩個物件,此時AB的引用計數都是2。會變成圖1,如果根中的引用變數置為null,則變成了圖二,此時AB的引用計數都是1.這樣就不能被回收,會發生記憶體洩漏。
所以基礎版本的引用計數演算法不可用,需要改良。改良版的引用計數演算法包括:延遲引用計數法,Sticky引用計數法,1位引用計數法,部分標記-清除演算法。
四、GC複製演算法——深度優先搜尋
GC 複製演算法是利用 From 空間進行分配的。當 From 空間被完全佔滿時,GC 會將活動物件全部複製到 To 空間。當複製完成後,該演算法會把 From 空間和 To 空間互換,GC 也就結束了。From 空間和 To 空間大小必須一致。這是為了保證能把 From 空間中的所有活動物件都收納到 To 空間裡。如下圖:

灰色表示佔用,白色表示空閒,首先如果from空間佔滿了,就會觸發GC,將存活的物件複製到to空間,然後交換from和to的指標,將to空間清空。
其中最需要注意的是複製完之後物件的地址會發生變化,地址發生變化後我們需要更新各個引用的地址。看虛擬碼:
copying(){
$free = $to_start
for(r : $roots)
*r = copy(*r)
swap($from_start, $to_start)
}首先將to空間的起始地址指向free,然後遍歷根集合呼叫copy函式,copy函式會返回複製後的新的地址,這樣就更新了引用。最後交換from和to的起始地址。再看copy函式虛擬碼:
copy(obj){
if(obj.tag != COPIED)
copy_data($free, obj, obj.size)
obj.tag = COPIED
obj.forwarding = $free
$free += obj.size
for(child : children(obj.forwarding))
*child = copy(*child)
return obj.forwarding
}物件頭有一個tag標記,物件是否複製過,類似深度優先搜尋的是否訪問過,防止有多個指向物件的引用造成重複複製。

1.如果未被複制過,則將obj複製到以free為起始地址的空間,比如物件A複製後在to空間生成物件A'。
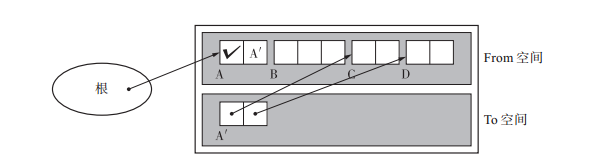
2.將tag標記為已經複製過,然後將forwarding設定為to空間的新地址。將free指向新的空閒起始地址。然後遞迴遍歷從A出發的其它物件。
3.最後返回obj的forwarding值,這樣所有的引用都指向了to空間的新地址。
執行完成後如下圖:
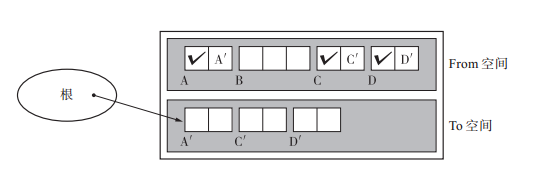
圖中的活動物件 A、C、D 保持著原有的引用關係被從 From 空間複製到了 To 空間。此外,從根指向 A 的指標也被換成了 AꞋ。留在 From 空間裡的物件 A BC D 都被回收了。
優點:
1.優秀的吞吐量,GC標記清除演算法首先要搜尋活動物件標記,然後遍歷整個堆進行清除,而複製演算法只需要遍歷活動物件然後進行復制即可。
2.分配速度快,GC複製演算法不使用空閒連結串列。這是因為分塊是一個連續的記憶體空間。所以只要申請的記憶體小於分塊大小就可以直接分配,直接移動起始地址指標,時間複雜度O(1)。比如jvm的新生代記憶體分配就是使用碰撞指標。而空閒連結串列法需要遍歷連結串列。
3.不會發生碎片,複製演算法在GC的時候把活動物件移動到to區的時候是按照to區的起始地址從小到大複製,然後釋放掉所有的from區空間,所以不存在記憶體縫隙。而空閒連結串列法,回收的時候不能移動物件的地址,所以會存在碎片。
缺點:
1.堆的使用效率低下,GC演算法通常將堆進行二等分,通常只能利用其中的一半來存放物件,1GB的記憶體只能利用500mb,所以空間浪費嚴重,GC複製和GC標記清除演算法搭配可以解決這個缺點,例如hotspot的實現。
2.遞迴呼叫函式,在複製物件的時候需要遞迴的去複製子物件。
五.Cheney的GC複製演算法——廣度優先搜尋
深度優先搜尋會大量使用遞迴,效率低下,而且有爆棧的危險,所以可以使用迭代式的廣度優先搜尋。
copying(){
scan = $free = $to_start
for(r : $roots)
*r = copy(*r)
while(scan != $free)
for(child : children(scan))
*child = copy(*child)
scan += scan.size
swap($from_start, $to_start)
}初始化scan和free指向to區的起始地址,首先複製所有根引用物件,複製完後free指向新的空閒空間起始地址,然後開始複製剛才加入to區的物件的孩子。再看copy函式
copy(obj){
if(is_pointer_to_heap(obj.forwarding, $to_start) == FALSE)
copy_data($free, obj, obj.size)
obj.forwarding = $free
$free += obj.size
return obj.forwarding
}首先判斷obj.forwardin是否屬於to區,如果是則說明已經複製過了直接返回,否則複製obj到to區,然後將obj.forwarding指向to區的新地址,更新to區free指標。然後返回。在廣度優先搜尋中不需要tag標籤標記是否複製,只需要使用forwarding欄位即可。
執行過程:
1.根指向了B和G,B指向了A,G指向了B和E

2.首先複製根直接引用的物件,將B和G複製到to區,scan 仍然指著 To 空間的開頭, $free 從 To 空間的開頭向右移動了 B 和 G 個長度,關鍵是 scan 每次對複製完成的物件進行搜尋時,以及 $free 每次對沒複製的物件進行復制時,都會向右移動。剩下就是重複搜尋物件和複製,直到 scan 和 $free 一致。

3.然後對B'開始搜尋,將B'指向的物件A複製到to區,同時把 scan 和 $free 分別向右移動了。

4.然後對G'開始搜尋,將G'指向的物件E複製到to區,注意G'也指向B,但是B已經複製過了所以此時直接把B的forawrding指標賦值給G',然後搜尋A'和E',他們沒有指向的物件直接退出迴圈返回。然後複製完成後如下圖所示

在一般的圖的廣度搜索演算法中,會需要一個FIFO的佇列儲存上一層遍歷的頂點,在這個演算法中沒發現,是因為while(scan != $free)直接把to區當做了一個佇列。因為to區的插入就是一個FIFO的類陣列。直接使用scan指標當做下標即可。
優點:
Cheney的GC複製演算法既沒有遞迴呼叫棧帶來的額外時間消耗,也沒有普通廣度優先搜尋的佔用記憶體(需要一個FIFO的佇列)。
缺點:
深度優先搜尋會將兩個相鄰的引用放到一塊,這樣可以充分利用cache(cache是成塊替換的),比如A引用B,在深度優先搜尋下會將AB放到堆中相鄰的位置,在快取到cache的時候,AB可能會快取到同一個cache塊,這樣在A訪問B的時候不會發生cache miss,但是廣度優先搜尋,會將引用的兩個物件放到不相鄰的地址,不能充分利用cache。
六.GC標記壓縮演算法
GC複製演算法和GC標記清除演算法相結合就是GC標記壓縮演算法,GC標記壓縮演算法在標記階段和GC標記清除演算法一樣,在壓縮階段和GC複製演算法的結果類似就是將物件按照地址從小到大的順序排列,不會產生記憶體碎片。
Lisp2演算法
lisp2演算法通過操作物件頭forwarding指標達到壓縮。

初始狀態
標記完成後狀態
壓縮完成後狀態
標記階段和標記清除演算法標記階段一樣,看壓縮階段偽碼:
compaction_phase(){
set_forwarding_ptr()
adjust_ptr()
move_obj()
}主要有三個步驟:1.設定forwarding指標。2.更新指標。3.移動物件
程式會搜尋整個堆,給活動的物件設定forwarding指標。forwarding初始狀態是null。看set_forwarding_ptr函式。
set_forwarding_ptr(){
scan = new_address = $heap_start
while(scan < $heap_end)
if(scan.mark == TRUE)
scan.forwarding = new_address
new_address += scan.size
scan += scan.size
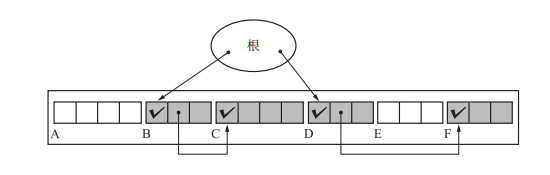
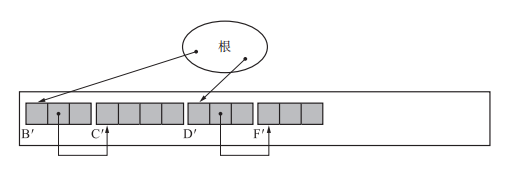
}scan 是用來搜尋堆中的物件的指標, new_address 是指向目標地點的指標。一旦 scan 指標找到活動物件,就會將物件的 forwarding 指標的引用目標從 NULL 更新到new_address,將 new_address 按物件長度移動。set_forwarding_ptr() 函式執行完畢後,堆的狀態如圖所示:

這裡處理forwarding和複製演算法有不同,複製演算法設定完forwarding之後,就開始移動,這裡不行,因為標記清除是在同一個空間內進行,如果此時進行移動會把原來的域覆蓋掉,比如B先移動,此時C的新位置還未確定,當c移動之後,再去更新B指向C的指標就找不到C了。所以第一輪遍歷先確定各個物件的新地址。
下面看更新指標:
adjust_ptr(){
for(r : $roots)
*r = (*r).forwarding
scan = $heap_start
while(scan < $heap_end)
if(scan.mark == TRUE)
for(child : children(scan))
*child = (*child).forwarding
scan += scan.size
}首先更新根結點的引用。然後對堆進行搜尋,將所有標記為活的物件的引用更新。
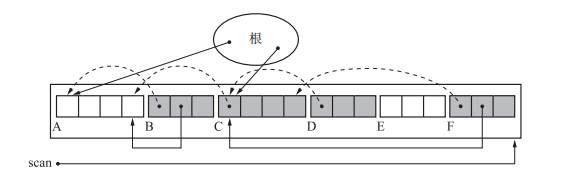
更新完如圖所示
最後開始移動物件:
move_obj(){
scan = $free = $heap_start
while(scan < $heap_end)
if(scan.mark == TRUE)
new_address = scan.forwarding
copy_data(new_address, scan, scan.size)
new_address.forwarding = NULL
new_address.mark = FALSE
$free += new_address.size
scan += scan.size
}將堆中活動的物件移動到新地址處,移動完成後將forwarding指標置為null,將標記為活動的標誌恢復。更新空閒區起始地址。
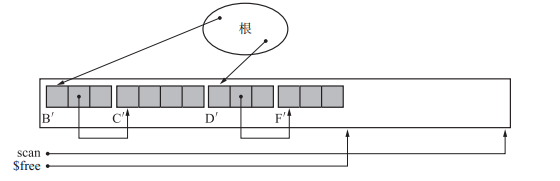
物件移動完成後狀態
優點:堆的利用效率高
缺點:壓縮耗費時間長,需要三次遍歷整個堆。堆越大耗時越長。
GC標記壓縮演算法還有Two-Finger 演算法,表格演算法,ImmixGC演算法。
七.分代垃圾回收——Ungar的分代垃圾回收
由於大部分物件分配後馬上又變成了垃圾,很少有物件能活很久。所以需要引入年齡的概念。把剛生成的物件叫做新生代物件,達到一定年齡的物件稱為老年代物件。
新生代的GC叫做minorGC。另外新生代GC將存活了一定次數的新生代物件做為老年代去處理,新生代物件上升為老年代物件叫做晉升。因為老年代的物件很少成為垃圾,所以老年代GC的頻率很低,老年代GC叫做major GC。
分代垃圾回收不能單獨用來進行GC,需要和以上演算法結合使用,這樣可以提高以上演算法的效率。也就是說,分代垃圾回收不是跟 GC 標記 - 清除演算法和 GC 複製演算法並列在一起供我們選擇的演算法,而是需要跟這些基本演算法一併使用。
David Ungar美國的電腦科學家發表的一篇論文,描述了分代垃圾回收的演算法過程,在 Ungar 的分代垃圾回收中,堆的結構我們總共需要利用 4 個空間,分別是生成空間、2 個大小相等的倖存空間以及老年代空間,並分別用$new_start、$survivor1_start、 $survivor2_start、$old_start 這 4 個變數引用它們的開頭。我們將生成空間和倖存空間合稱為新生代空間。新生代物件會被分配到新生代空間,老年代物件則會被分配到老年代空間裡。Ungar 在論文裡把生成空間、倖存空間以及老年代空間的大小分別設成了 140K位元組、28K 位元組和 940K 位元組。堆結構如下圖:

圖中生成空間就是進行物件分配的空間。當生成空間滿的時候新生代GC就會啟動,將生成空間的所有物件進行復制,目標是倖存空間,和GC複製演算法原理一樣。2 個倖存空間和 GC 複製演算法裡的 From 空間、To 空間很像,我們經常只利用其中的一個。在每次執行新生代 GC 的時候,活動物件就會被複制到另一個倖存空間裡。在此我們將正在使用的倖存空間作為 From 倖存空間,將沒有使用的倖存空間作為 To 倖存空間。不過新生代 GC 也必須複製生成空間裡的物件。也就是說,生成空間和 From 倖存空間這兩個空間裡的活動物件都會被複制到 To 倖存空間裡去。這就是新生代 GC。只有從一定次數的新生代 GC 中存活下來的物件才會得到晉升,也就是會被複制到老年代空間去。
新生代GC過程如下圖:

GC將生成空間和from區活物件複製到to,然後交換from和to。
在執行新生代 GC 時有一點需要注意,那就是我們必須考慮到從老年代空間到新生代空間的引用。新生代物件不只會被根和新生代空間引用,也可能被老年代物件引用。因此,除了一般 GC 裡的根,我們還需要將從老年代空間的引用當作根(像根一樣的東西)來處理。
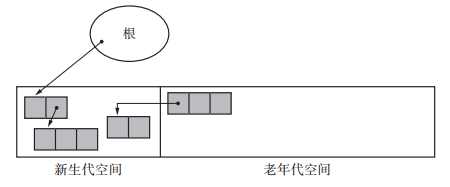
老年代物件指向新生代物件
分代垃圾回收的優點是隻將垃圾回收的重點放在新生代物件身上,以此來縮減 GC 所需要的時間。不過考慮到從老年代物件的引用,結果還是要搜尋堆中的所有物件,這樣一來就大大削減了分代垃圾回收的優勢。所以需要將老年代引用新生代的物件記錄下來,這樣就只需要搜尋這類物件。
記錄集就是存放記錄老年代引用新生代的老年代物件,這樣就能通過記錄集搜尋發出引用的物件,進而晉升引用的目標物件,再將發出引用的物件的指標更新到目標空間。

我們需要將老年代引用新生代物件的物件放到記錄集,這個函式和引用計數的update_ptr函式類似,需要在引用賦值的時候呼叫虛擬碼如下:
write_barrier(obj, field, new_obj){
if(obj >= $old_start && new_obj < $old_start && obj.remembered == FALSE)
$rs[$rs_index] = obj
$rs_index++
obj.remembered = TRUE
*field = new_obj
}引數 obj 是發出引用的物件, obj 記憶體在要更新的指標,而 field 指的就是 obj 內的域,new_obj 是在指標更新後成為引用目標的物件。 首先判斷obj是否在老年代,並且new_obj是否在新生代,並且obj未被放到記錄集(防止重複放置)。如果obj在老年代並且new_obj在新生代,並且obj未被放置到老年代。則將obj的引用放到記錄集,記錄集遊標++,將obj放置到記錄集的標記置為true,最後將new_obj賦值給obj的filed域。
記憶體分配是在生成空間分配的,虛擬碼:
new_obj(size){
if($new_free + size >= $survivor1_start)
minor_gc()
if($new_free + size >= $survivor1_start)
allocation_fail()
obj = $new_free
$new_free += size
obj.age = 0
obj.forwarded = FALSE
obj.remembered = FALSE
obj.size = size
return obj
}如果空間不夠則觸發minor_gc,如果還不夠則分配失敗。否則將空閒空間的首地址賦值給obj,更新空閒空間首地址,obj的年齡為0,forwarded標誌(是否進行了複製標誌,防止重複複製)是false,rembered標誌(是否存在記錄集)是false。
新生代GC需要呼叫minor_gc,然後minor_gc呼叫copy函式,虛擬碼如下:
copy(obj){
if(obj.forwarded == FALSE)
if(obj.age < AGE_MAX)
copy_data($to_survivor_free, obj, obj.size)
obj.forwarded = TRUE
obj.forwarding = $to_survivor_free
$to_survivor_free.age++
$to_survivor_free += obj.size
for(child : children(obj))
*child = copy(*child)
else
promote(obj)
return obj.forwarding
}遍歷生成空間的物件,1.如果物件還未發生過複製,如果物件的年齡小於晉升到老年代的年齡:則把物件複製到倖存者區的to空間,設定forwarded複製標誌位true,forwarding指標為to空間新地址,obj年齡+1。更新to空間的空閒起始地址。然後遞迴遍歷obj的所引用的結點。
2.如果物件還未發生過複製,如果物件的年齡大於等於晉升到老年代的年齡:則直接將obj晉升到老年代。
3.最後返回obj新地址。
再看晉升函式虛擬碼:
promote(obj){
new_obj = allocate_in_old(obj)
if(new_obj == NULL)
major_gc()
new_obj = allocate_in_old(obj)
if(new_obj == NULL)
allocation_fail()
obj.forwarding = new_obj
obj.forwarded = TRUE
for(child : children(new_obj))
if(*child < $old_start)
$rs[$rs_index] = new_obj
$rs_index++
new_obj.remembered = TRUE
return
}1.在老年代分配一個和obj一樣的物件。2.如果空間不夠則啟動major_gc()。3.再次分配。4.如果還不夠則分配失敗。5.如果分配成功則將obj在老年代的新地址賦值給forwarding指標,複製標誌置為true。6.遍歷obj引用的物件如果在新生代則將obj加入記錄集,加入記錄集標誌為true,更新記錄集下標,最後返回。
再看minor gc函式:
minor_gc(){
$to_survivor_free = $to_survivor_start
for(r : $roots)
if(*r < $old_start)
*r = copy(*r)
i = 0
while(i < $rs_index)
has_new_obj = FALSE
for(child : children($rs[i]))
if(*child < $old_start)
*child = copy(*child)
if(*child < $old_start)
has_new_obj = TRUE
if(has_new_obj == FALSE)
$rs[i].remembered = FALSE
$rs_index--
swap($rs[i], $rs[$rs_index])
else
i++
swap($from_survivor_start, $to_survivor_start)
}1.將to區首地址給$to_survivor_free。2.複製根指向新生代的存活物件。3.遍歷記錄集複製老年代指向新生代的物件。4.如果還有老年代指向的物件還在新生代則複製,如果複製完還是在新生代則將has_new_obj置為true。5.如果has_new_obj是false說明當前老年代物件已經沒有指向新生代物件了。所以需要將記錄集當前老年代物件刪除。首先將remebered標誌設定為false。然後將記錄集大小減一,最後將記錄集最後一個物件和當前物件調換位置。6.全部複製完成後,交換form和to指標。
minor gc過程如下圖:

老年代GC演算法:Ungar使用的GC標記清除。