
第二篇:基於深度學習的人臉特徵點檢測
在上一篇博文中,我們瞭解了人臉檢測與面部特徵點檢測的背景,並提到了當前技術方案存在特徵點位置不穩定的缺點,需要新的解決方案。那麼,目前又有哪些方案可以用呢?
Github rocks!
在程式設計師眼中,Github恐怕是比微信還要重要的存在了吧!以“face landmark”為關鍵詞,在Github中一共檢索到171項結果。有兩項repo吸引了我的注意力,一項是OpenFace[1],在Github上有1.7k多star數;另一項為face-landmark-localization[2],作者是復旦大學的一名博士。
OpenFace
OpenFace來自CMU大學,在簡介中它是這樣描述的:
OpenFace – a state-of-the art tool intended for facial landmark detection, head pose estimation, facial action unit recognition, and eye-gaze estimation.
此言不假,經過我的實際測試,OpenFace可以實時穩定的對人臉的面部特徵點進行檢測。不僅如此,它還提供了表情檢測與注視點檢測的功能,非常強大。
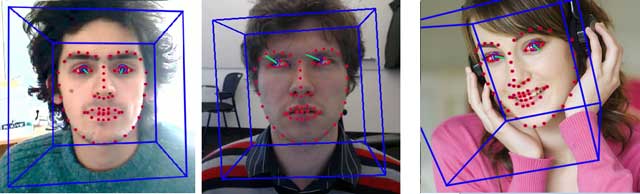
OpenFace的原理可以參見他們發表的論文,在repo主頁可以看到。
face-landmark-localization
從說明與程式碼來看,作者用dlib作為人臉面部檢測器,使用深度學習框架caffe作為特徵提取以及特徵點的檢測器,同時姿態的輸出也是基於神經網路。並且在較早的一項issue
哈?300-W又是神馬?
人臉特徵點檢測大賽300-W
經過一番檢索,終於在Imperial College London(帝國理工學院)的網站上找到了真身[4]。300-W是300 Faces In-The-Wild Challenge的簡稱,該項競賽專注於人臉特徵點的檢測,並且與ICCV這類著名的計算機視覺活動相伴舉行。在該競賽中,參賽隊伍需要從600張圖片中檢出人臉,並且將面部的68個特徵點全部標記出來。更加幸運的是,2016的這篇論文[5]中,作者對現有的9個人臉特徵點公開資料庫以及2015年300-W競賽的結果做了詳細的描述,一下子節省了我大量的時間。
站在前人肩膀上大概就是這種感覺吧!
人臉特徵點資料庫
論文中工涉及到了9個人臉特徵點資料庫,並分成兩類。
- 可控環境下獲得的資料:Multi-PIE、XM2VTS、FRGC-V2和AR。
- 不可控環境下獲得的資料:LFPW、HELEN、AFW、AFLW和IBUG。
這些資料庫的來源多種多樣,並且每個從資料庫都採用了不同的標記策略和標記數量,導致各個庫之間根本不具可比性。幸運的是,作者採用了一種半監督的方法,重新對這些資料庫進行了標記!你以為這就很了不起的時候,他們把標記後的資料[6]免費放出來了...
不過,公開的標記資料並不包含全部9個數據庫,僅僅包含7個,且有一些資料庫僅僅提供了特徵點的座標,不包含影象資料。我簡單整理了一下。
- 300-W:圖片+資料。
- XM2VTS:僅資料,圖片需要付費購買。
- FRGC Ver.2:僅資料,圖片需要獲得授權才能拿到。
- LFPW:圖片+資料。
- HELEN:圖片+資料。
- AFW:圖片+資料。
- IBUG:圖片+資料。
所以,最後拿到手的有效資料集只有5個:300-W、LFPW、HELEN、AFW和IBUG。總共3.2GB,大約有4000多份樣本。這個數量的樣本恐怕是不夠的。
在瀏覽官網的時候有一個意外的發現:300-W競賽的進階版300-VW[7],同樣是面部特徵點的檢測,只不過檢測的物件從圖片變成了視訊。資料集提供了幾乎每一幀的人臉特徵點資料。所以一段20秒的視訊可以提取出約500張畫面,300-VW裡大約有500多段視訊,所以理論上可以提取出大概250000份圖片樣本!
啊!此刻心中的感覺複雜而難以描述。
檢測方法
除了資料集意外,論文還對2015年提交的TOP5檢測方法做了總結概括。其中一篇採用深度學習的方案吸引了我的注意力。論文題為”Approaching Human Level Facial Landmark Localization by Deep Learning[8]”,作者來自國內一家知名的公司曠視科技[9]。
這篇論文中,作者採用了兩級神經網路級聯的方式,實現了由粗到細的landmark檢測。
第一級網路負責從圖片中初步檢出68個特徵點的大致位置。不算pooling layer共計10層,輸入層大小為128x128,8個卷積層,2個全連線層。在第一級網路完成檢測後,根據檢測到的68個特徵點計算人臉姿態,然後將姿態“矯正”到接近正臉,然後把矯正後的、分別包含68個點的較小一點的影象區域輸入到第二級神經網路。
第二級神經網路負責對檢測結果進行細化,輸出最終的座標。這一級不算pooling layer共計7層,輸入層大小28x28,5個卷積層,2個全連線層。需要注意的是,第二級神經網路的數量眾多,每一個特徵點對應了一個神經網路。
曠視科技應該是將該方法用在人臉識別上。如果需求精度不高,可以考慮僅僅使用第一級網路結構輸出68個特徵點的位置。
接下來的計劃
資料有了,方法上神經網路看起來有戲。接下來就該動手了!在下一篇文章中,我們將對現有資料進行分析,嘗試找到適合神經網路訓練的資料集表示方法。