
人臉特徵點檢測(一):深度卷積網路級聯
人臉特徵檢測(face feature detection)也稱為 “facial landmark detection”, “facial keypoint detection” and “face alignment”,是在人臉檢測的基礎上,對人臉上的特徵點例如眼睛、鼻子、嘴巴等進行定位。
人臉關鍵點檢測有很多應用。如下作了一些列舉:
(1)Facial feature detection improves face recognize(面部特徵檢測改善面部識別)
人臉特徵點可以用來將人臉對齊到平均人臉(mean face shape),這樣在對齊之後所有影象中的人臉特徵點位置幾乎相同。有論文驗證了用對齊後的影象訓練的人臉識別演算法更加有效。
(2)Head pose estimation(頭部姿勢估計)
知道特徵點的定向,可以估計頭部姿勢,即人臉朝向問題。
(3)Face Morphing(人臉變形)
人臉特徵點對齊人臉之後,可以有兩張人臉影象生成一張新的融合人臉影象。
(4)Virtual Makeover(虛擬化妝)
現在很多軟體正在用的給影象上的人物化妝的功能就是基於人臉識別的。
(5)Face Replacement(人臉交換)
人臉對換:基於臉部監測點,將一張人臉換成另外一張人臉。
卷積神經網路可以用於分類和迴歸任務,做分類任務時最後一個全連線層的輸出維度為類別數,接著Softmax層採用Softmax Loss計算損失函式,而如果做迴歸任務,最後一個全連線層的輸出維度則是要回歸的座標值的個數,採用的是歐幾裡何損失Euclidean Loss。
這裡基於《Deep Convolutional Network Cascade for Facial Point Detection》論文進行講述,連結地址。



訓練卷積神經網路來回歸特徵點座標。如果只採用一個網路來做迴歸訓練的話,會發現得到的特徵點座標不夠準確,採用級聯迴歸。CNN的方法,進行分段式特徵點定位,可以更快速、準確的定位人臉特徵點。如果採用更大的網路,特徵點的預測會更加準確、魯棒,但耗時會增加;為了在速度和效能上找到一個平衡點,使用較小的網路,所以使用級聯的思想,先進行粗檢測,然後微調特徵點。具體思路如下:

(1)首先在整個人臉影象(紅色方框)上訓練一個網路來對人臉特徵點座標進行粗迴歸,實際採用的網路其輸入大小為39*39的人臉區域灰度圖,預測時可以得到特徵點的大概位置;如上圖level1,在綠色框中,預測出5個點;第一層分為三波,分別是對五個點、左右眼和鼻子、鼻子和嘴巴。
(2)設計另一個迴歸網路,以人臉特徵點(取得是level1訓練之後得到的特徵點)周圍的區域性區域影象(level2和level3中的黃色區域)作為輸入進行訓練,實際採用的網路為其輸入大小為15*15的特徵點區域性區域灰度圖,以預測到更加準確的特徵點位置。這裡level3比level2定義的輸入區域要小一點。
另外需要注意的是,迴歸採用的歐幾里得損失,在計算座標時,使用的是相對座標而不是絕對座標,即每一次座標計算,相對座標是相對於上圖所示的黃色框的邊界進行的,絕對座標是基於綠色邊框邊界進行的。
除此之外,在level1訓練時,還對訓練集進行了增廣。除了做映象之外,還對人臉框進行了兩組縮放和四組平移,以及兩組小角度的旋轉,然後再將人臉框區域裁剪成39*39大小的區域。
下面是level1的實現:
#!/usr/bin/env python2.7
# coding: utf-8
"""
This file convert dataset from http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm
We convert data for LEVEL-1 training data.
all data are formated as (data, landmark), and landmark is ((x1, y1), (x2, y2)...)
"""
import os
import time
import math
from os.path import join, exists
import cv2
import numpy as np
import h5py
from common import shuffle_in_unison_scary, logger, createDir, processImage
from common import getDataFromTxt
from utils import show_landmark, flip, rotate
TRAIN = 'dataset/train'
OUTPUT = 'train'
if not exists(OUTPUT): os.mkdir(OUTPUT)
assert(exists(TRAIN) and exists(OUTPUT))
def generate_hdf5(ftxt, output, fname, argument=False):
data = getDataFromTxt(ftxt) #從txt檔案中生成資料 return [(img_path, bbox, landmark)]
#bbox: [left, right, top, bottom]
#landmark: [(x1, y1), (x2, y2), ...]
F_imgs = []
F_landmarks = []
EN_imgs = []
EN_landmarks = []
NM_imgs = []
NM_landmarks = []
for (imgPath, bbox, landmarkGt) in data:
img = cv2.imread(imgPath, cv2.CV_LOAD_IMAGE_GRAYSCALE)
assert(img is not None)
logger("process %s" % imgPath)
# F
f_bbox = bbox.subBBox(-0.05, 1.05, -0.05, 1.05)
f_face = img[f_bbox.top:f_bbox.bottom+1,f_bbox.left:f_bbox.right+1] #人臉框影象
##針對訓練集,對資料集進行了增廣,除了做映象之外,還對人臉框位置做了兩組縮放和四組平移
## data argument
if argument and np.random.rand() > -1: #argument=false時,不做資料增廣
### flip#人臉映象
face_flipped, landmark_flipped = flip(f_face, landmarkGt) #將人臉框影象和關鍵點座標同時映象
face_flipped = cv2.resize(face_flipped, (39, 39)) #人臉框影象縮放到統一大小,預設雙線性插值
F_imgs.append(face_flipped.reshape((1, 39, 39))) #opencv讀取的影象shape為(h,w,c),轉變為(c,h,w)
F_landmarks.append(landmark_flipped.reshape(10)) #將5x2的標籤reshape成一維
### rotation ##對人臉框做兩組隨機的小角度旋轉,但最後對特徵點位置預測的準確性並沒有多大提高。
if np.random.rand() > 0.5:
face_rotated_by_alpha, landmark_rotated = rotate(img, f_bbox, \
bbox.reprojectLandmark(landmarkGt), 5) #採用相對座標,促進模型收斂,避免網路訓練時發散
landmark_rotated = bbox.projectLandmark(landmark_rotated) ##在做資料增廣時,對應的特徵點座標要轉化為相對座標
face_rotated_by_alpha = cv2.resize(face_rotated_by_alpha, (39, 39))
F_imgs.append(face_rotated_by_alpha.reshape((1, 39, 39)))
F_landmarks.append(landmark_rotated.reshape(10))
### flip with rotation
face_flipped, landmark_flipped = flip(face_rotated_by_alpha, landmark_rotated)
face_flipped = cv2.resize(face_flipped, (39, 39))
F_imgs.append(face_flipped.reshape((1, 39, 39)))
F_landmarks.append(landmark_flipped.reshape(10))
### rotation
if np.random.rand() > 0.5:
face_rotated_by_alpha, landmark_rotated = rotate(img, f_bbox, \
bbox.reprojectLandmark(landmarkGt), -5)
landmark_rotated = bbox.projectLandmark(landmark_rotated)
face_rotated_by_alpha = cv2.resize(face_rotated_by_alpha, (39, 39))
F_imgs.append(face_rotated_by_alpha.reshape((1, 39, 39)))
F_landmarks.append(landmark_rotated.reshape(10))
### flip with rotation
face_flipped, landmark_flipped = flip(face_rotated_by_alpha, landmark_rotated)
face_flipped = cv2.resize(face_flipped, (39, 39))
F_imgs.append(face_flipped.reshape((1, 39, 39)))
F_landmarks.append(landmark_flipped.reshape(10))
f_face = cv2.resize(f_face, (39, 39))
en_face = f_face[:31, :]
nm_face = f_face[8:, :]
f_face = f_face.reshape((1, 39, 39))
f_landmark = landmarkGt.reshape((10))
F_imgs.append(f_face)
F_landmarks.append(f_landmark)
# EN
# en_bbox = bbox.subBBox(-0.05, 1.05, -0.04, 0.84)
# en_face = img[en_bbox.top:en_bbox.bottom+1,en_bbox.left:en_bbox.right+1]
## data argument
if argument and np.random.rand() > 0.5:
### flip
face_flipped, landmark_flipped = flip(en_face, landmarkGt)
face_flipped = cv2.resize(face_flipped, (31, 39)).reshape((1, 31, 39))
landmark_flipped = landmark_flipped[:3, :].reshape((6))
EN_imgs.append(face_flipped)
EN_landmarks.append(landmark_flipped)
en_face = cv2.resize(en_face, (31, 39)).reshape((1, 31, 39))
en_landmark = landmarkGt[:3, :].reshape((6))
EN_imgs.append(en_face)
EN_landmarks.append(en_landmark)
# NM
# nm_bbox = bbox.subBBox(-0.05, 1.05, 0.18, 1.05)
# nm_face = img[nm_bbox.top:nm_bbox.bottom+1,nm_bbox.left:nm_bbox.right+1]
## data argument
if argument and np.random.rand() > 0.5:
### flip
face_flipped, landmark_flipped = flip(nm_face, landmarkGt)
face_flipped = cv2.resize(face_flipped, (31, 39)).reshape((1, 31, 39))
landmark_flipped = landmark_flipped[2:, :].reshape((6))
NM_imgs.append(face_flipped)
NM_landmarks.append(landmark_flipped)
nm_face = cv2.resize(nm_face, (31, 39)).reshape((1, 31, 39))
nm_landmark = landmarkGt[2:, :].reshape((6))
NM_imgs.append(nm_face)
NM_landmarks.append(nm_landmark)
#imgs, landmarks = process_images(ftxt, output)
F_imgs, F_landmarks = np.asarray(F_imgs), np.asarray(F_landmarks)
EN_imgs, EN_landmarks = np.asarray(EN_imgs), np.asarray(EN_landmarks)
NM_imgs, NM_landmarks = np.asarray(NM_imgs),np.asarray(NM_landmarks)
F_imgs = processImage(F_imgs) #影象預處理:去均值、歸一化
shuffle_in_unison_scary(F_imgs, F_landmarks) #亂序
EN_imgs = processImage(EN_imgs)
shuffle_in_unison_scary(EN_imgs, EN_landmarks)
NM_imgs = processImage(NM_imgs)
shuffle_in_unison_scary(NM_imgs, NM_landmarks)
# full face
base = join(OUTPUT, '1_F')
createDir(base)
output = join(base, fname) #拼接成h5檔案全路徑
logger("generate %s" % output)
with h5py.File(output, 'w') as h5:
h5['data'] = F_imgs.astype(np.float32)
h5['landmark'] = F_landmarks.astype(np.float32)
# eye and nose
base = join(OUTPUT, '1_EN')
createDir(base)
output = join(base, fname)
logger("generate %s" % output)
with h5py.File(output, 'w') as h5:
h5['data'] = EN_imgs.astype(np.float32)#資料轉換成float32型別,存影象
h5['landmark'] = EN_landmarks.astype(np.float32) #資料轉換成float32型別,存座標標籤
# nose and mouth
base = join(OUTPUT, '1_NM')
createDir(base)
output = join(base, fname)
logger("generate %s" % output)
with h5py.File(output, 'w') as h5:
h5['data'] = NM_imgs.astype(np.float32)
h5['landmark'] = NM_landmarks.astype(np.float32)
if __name__ == '__main__':
# train data
train_txt = join(TRAIN, 'trainImageList.txt') #join函式相當於matlab中的fullfile函式,用來連線目錄和檔名,得到完整檔案路徑
generate_hdf5(train_txt, OUTPUT, 'train.h5', argument=True) #輸入引數:(原始影象和關鍵點座標標籤文字,h5檔案輸出目錄,h5檔名,是否資料增廣)
test_txt = join(TRAIN, 'testImageList.txt')
generate_hdf5(test_txt, OUTPUT, 'test.h5') #驗證集不需要取大量值,沒有旋轉
with open(join(OUTPUT, '1_F/train.txt'), 'w') as fd:
fd.write('train/1_F/train.h5')
with open(join(OUTPUT, '1_EN/train.txt'), 'w') as fd:
fd.write('train/1_EN/train.h5')
with open(join(OUTPUT, '1_NM/train.txt'), 'w') as fd:
fd.write('train/1_NM/train.h5')
with open(join(OUTPUT, '1_F/test.txt'), 'w') as fd:
fd.write('train/1_F/test.h5')
with open(join(OUTPUT, '1_EN/test.txt'), 'w') as fd:
fd.write('train/1_EN/test.h5')
with open(join(OUTPUT, '1_NM/test.txt'), 'w') as fd:
fd.write('train/1_NM/test.h5')
# Done
因為lmdb不支援多標籤,所以這裡使用的是hdf5格式,支援多標籤。
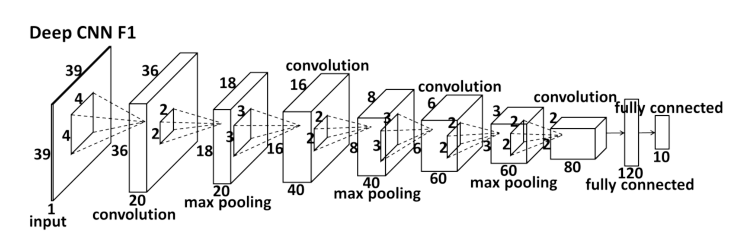
如上圖所示為Deep CNN F1 的卷積網路結構,level1網路的輸入層使用的是39*39的單通道灰色影象,經過四個帶池化層的卷積層,最後經過全連線層,輸出一個維度為10的結果,代表5個特徵點的座標值,,,在最後一層是歐幾里得損失層,計算的是網路預測的座標值與真實值(都是相對值)之間的均值誤差的積累。以下為網路結構
# This file gives the CNN model to predict all landmark in LEVEL-1
name: "landmark_1_F"
layer {
name: "hdf5_train_data"
type: "HDF5Data"
top: "data"
top: "landmark"
include {
phase: TRAIN
}
hdf5_data_param {
source: "train/1_F/train.txt"
batch_size: 64
}
}
layer {
name: "hdf5_test_data"
type: "HDF5Data"
top: "data"
top: "landmark"
include {
phase: TEST
}
hdf5_data_param {
source: "train/1_F/test.txt"
batch_size: 64
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 4
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 40
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 60
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4"
type: "Convolution"
bottom: "pool3"
top: "conv4"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 80
kernel_size: 2
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "pool3_flat"
type: "Flatten"
bottom: "pool3"
top: "pool3_flat"
}
layer {
name: "conv4_flat"
type: "Flatten"
bottom: "conv4"
top: "conv4_flat"
}
layer {
name: "concat"
type: "Concat"
bottom: "pool3_flat"
bottom: "conv4_flat"
top: "faker"
concat_param {
concat_dim: 1
}
}
layer {
name: "fc1"
type: "InnerProduct"
bottom: "faker"
top: "fc1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 120
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu_fc1"
type: "ReLU"
bottom: "fc1"
top: "fc1"
}
layer {
name: "fc2"
type: "InnerProduct"
bottom: "fc1"
top: "fc2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu_fc2"
type: "ReLU"
bottom: "fc2"
top: "fc2"
}
#計算的是網路預測的座標值與真實值(都是相對值)之間的均方誤差的累積
layer {
name: "error"
type: "EuclideanLoss"
bottom: "fc2"
bottom: "landmark"
top: "error"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "EuclideanLoss"
bottom: "fc2"
bottom: "landmark"
top: "loss"
include {
phase: TRAIN
}
}
solver超引數檔案如下,CPU/GPU模式依情況選擇:
net: "prototxt/1_F_train.prototxt"
test_iter: 25
test_interval: 1000
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
lr_policy: "inv"
gamma: 0.0001
power: 0.75
#lr_policy: "step"
#gamma: 0.1
#stepsize: 50000
display: 200
max_iter: 1000000
snapshot: 50000
snapshot_prefix: "model/1_F/"
test_compute_loss: true
solver_mode: CPU
第一層訓練完成之後,得到預測結果,這是已經得到預測的特徵點位置,但可能不夠精確,接下來進入第二、三層訓練,得到更加精確的結構。第一層使用的是一個較深一點的網路,估計關鍵點的位置;第二、三層共享一個較淺一點的網路,實現高精度。
第二層訓練,以第一層訓練得到的5個特徵點為基礎,每個特徵點做兩組資料集,即以第一組資料集特徵點為中心,區域性框大小為(2*0.18*W,2*0.18*H),其中W和H為人臉框的寬和高,並對此區域性框做隨機的微小平移使得特徵點在區域性框中的位置隨機,裁剪出一個大小為15*15的區域性框影象,第二組資料和第一組資料一樣,只是框比例取0.16(第三層的兩組資料比例為0.11、0.12,其餘和第二層一樣)。對每個特徵點,針對這兩組資料集採用同樣的網路,得到兩組模型;預測時,採用兩組模型預測的均值作為預測結果,提高預測的準確度。以下為第二層網路程式碼:
#!/usr/bin/env python2.7
# coding: utf-8
"""
This file convert dataset from http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm
We convert data for LEVEL-2 training data.
all data are formated as (patch, delta landmark), and delta landmark is ((x1, y1), (x2, y2)...)
"""
import os
from os.path import join, exists
import time
from collections import defaultdict
import cv2
import numpy as np
import h5py
from common import logger, createDir, getDataFromTxt, getPatch, processImage
from common import shuffle_in_unison_scary
from utils import randomShift, randomShiftWithArgument
#兩組資料集:(1)區域性框大小為(2*0.18*W,2*0.18*H);(2)區域性框大小為(2*0.16*W,2*0.16*H)
types = [(0, 'LE1', 0.16),
(0, 'LE2', 0.18),
(1, 'RE1', 0.16),
(1, 'RE2', 0.18),
(2, 'N1', 0.16),
(2, 'N2', 0.18),
(3, 'LM1', 0.16),
(3, 'LM2', 0.18),
(4, 'RM1', 0.16),
(4, 'RM2', 0.18),] #5個關鍵點,兩種padding
for t in types:
d = 'train/2_%s' % t[1]
createDir(d) #建立資料夾存放train和test的txt和h5檔案
def generate(ftxt, mode, argument=False):
"""
Generate Training Data for LEVEL-2
mode = train or test
"""
data = getDataFromTxt(ftxt) #取得image_path、bbox、landmark
trainData = defaultdict(lambda: dict(patches=[], landmarks=[])) #資料字典
for (imgPath, bbox, landmarkGt) in data:
img = cv2.imread(imgPath, cv2.CV_LOAD_IMAGE_GRAYSCALE)
assert(img is not None)
logger("process %s" % imgPath)
landmarkPs = randomShiftWithArgument(landmarkGt, 0.05) #對關鍵點相對座標的位置做2組隨機平移,得到2組“新的關鍵點”
if not argument:
landmarkPs = [landmarkPs[0]]#測試集只做一組隨機平移
#對做的2組隨機平移,將所有區域性框影象和關鍵點相對於區域性框的相對座標送入到資料字典trainData
for landmarkP in landmarkPs:
for idx, name, padding in types:
patch, patch_bbox = getPatch(img, bbox, landmarkP[idx], padding) #根據隨機平移過的關鍵點相對座標和padding得到區域性框影象和區域性框
patch = cv2.resize(patch, (15, 15)) #區域性框影象縮放到15x15
patch = patch.reshape((1, 15, 15)) #每個patch為c,h,w,append之後就變成了n,c,h,w
trainData[name]['patches'].append(patch)
_ = patch_bbox.project(bbox.reproject(landmarkGt[idx])) #‘真’關鍵點 ,再投影到區域性框得到相對區域性框的相對座標
trainData[name]['landmarks'].append(_)
for idx, name, padding in types:
logger('writing training data of %s'%name)
patches = np.asarray(trainData[name]['patches']) #從資料字典中取出
landmarks = np.asarray(trainData[name]['landmarks'])
patches = processImage(patches) #預處理,去均值、歸一化
shuffle_in_unison_scary(patches, landmarks)
with h5py.File('train/2_%s/%s.h5'%(name, mode), 'w') as h5: #生成mode.h5(train/test)
h5['data'] = patches.astype(np.float32)
h5['landmark'] = landmarks.astype(np.float32)
with open('train/2_%s/%s.txt'%(name, mode), 'w') as fd: #生成mode.txt(train/test),寫入h5檔案路徑
fd.write('train/2_%s/%s.h5'%(name, mode))
if __name__ == '__main__':
np.random.seed(int(time.time())) #seed指定隨機數生成時所用演算法開始的整數值,使隨機值的產生隨時間而變化,而不會每次產生的隨機數都相同
# trainImageList.txt
generate('dataset/train/trainImageList.txt', 'train', argument=True) #生成train.h5和train.txt,訓練集做資料增強(實際上只是多做了一組隨機平移)
# testImageList.txt
generate('dataset/train/testImageList.txt', 'test')#生成test.h5和test.txt
# Done
網路配置:
# This file gives the CNN model to predict landmark in LEVEL-2
name: "landmark_2_LE1"
layer {
name: "hdf5_train_data"
type: "HDF5Data"
top: "data"
top: "landmark"
include {
phase: TRAIN
}
hdf5_data_param {
source: "train/2_LE1/train.txt"
batch_size: 64
}
}
layer {
name: "hdf5_test_data"
type: "HDF5Data"
top: "data"
top: "landmark"
include {
phase: TEST
}
hdf5_data_param {
source: "train/2_LE1/test.txt"
batch_size: 64
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 4
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 40
kernel_size: 3
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc1"
type: "InnerProduct"
bottom: "pool2"
top: "fc1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 60
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu_fc1"
type: "ReLU"
bottom: "fc1"
top: "fc1"
}
layer {
name: "fc2"
type: "InnerProduct"
bottom: "fc1"
top: "fc2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 2
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "relu_fc2"
type: "ReLU"
bottom: "fc2"
top: "fc2"
}
layer {
name: "error"
type: "EuclideanLoss"
bottom: "fc2"
bottom: "landmark"
top: "error"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "EuclideanLoss"
bottom: "fc2"
bottom: "landmark"
top: "loss"
include {
phase: TRAIN
}
}
net: "prototxt/2_LE1_train.prototxt"
test_iter: 25
test_interval: 1000
base_lr: 0.005
momentum: 0.9
weight_decay: 0.0005
lr_policy: "inv"
gamma: 0.0001
power: 0.75
#lr_policy: "step"
#gamma: 0.1
#stepsize: 50000
display: 200
max_iter: 100000
snapshot: 10000
snapshot_prefix: "model/2_LE1/"
test_compute_loss: true
solver_mode: CPU
#!/usr/bin/env python2.7
# coding: utf-8
"""
This file train Caffe CNN models
"""
import os, sys
import multiprocessing
pool_on = False
models = [
['F', 'EN', 'NM'],
['LE1', 'LE2', 'RE1', 'RE2', 'N1', 'N2', 'LM1', 'LM2', 'RM1', 'RM2'],
['LE1', 'LE2', 'RE1', 'RE2', 'N1', 'N2', 'LM1', 'LM2', 'RM1', 'RM2'],]
def w(c):
if c != 0:
print '\n'
print ':-('
print '\n'
sys.exit()
def runCommand(cmd):
w(os.system(cmd))
def train(level=1):
"""
train caffe model
"""
cmds = []
for t in models[level-1]:
cmd = 'mkdir model/{0}_{1}'.format(level, t)
#此命令列錯誤,無法建立資料夾!
os.system(cmd)
cmd = 'caffe train --solver prototxt/{0}_{1}_solver.prototxt'.format(level, t)
# w(os.system(cmd))
cmds.append('caffe train --solver prototxt/{0}_{1}_solver.prototxt'.format(level, t))
# we train level-2 and level-3 with mutilprocess (we may train two level in parallel)
if level > 1 and pool_on:
pool_size = 3
pool = multiprocessing.Pool(processes=pool_size, maxtasksperchild=2)
pool.map(runCommand, cmds) #map函式,將runcommand函式應用到每個cmds上
pool.close()
pool.join()
else:
for cmd in cmds:
runCommand(cmd)
if __name__ == '__main__':
argc = len(sys.argv) #獲得命令列字串的個數
assert(2 <= argc <= 3)
if argc == 3: #如nohup python train/level.py 1 pool_on 只算python的後面三個
pool_on = True
level = int(sys.argv[1]) #python後面的第二個
if 1 <= level <= 3:
train(level)
else:
for level in range(1, 4):
train(level)