
怎麼進行MongoDB效能優化?
 資料庫效能對軟體整體效能的影響是不言而喻的,那麼,當我們使用MongoDB時改如何提高資料庫效能呢?
資料庫效能對軟體整體效能的影響是不言而喻的,那麼,當我們使用MongoDB時改如何提高資料庫效能呢?
1.正規化化與反正規化化
在專案設計階段,明確集合的用途是對效能調優非常重要的一步。
從效能優化的角度來看,集合的設計我們需要考慮的是集合中資料的常用操作,例如我們需要設計一個日誌(log)集合,日誌的檢視頻率不高,但寫入頻率卻很高,那麼我們就可以得到這個集合中常用的操作是更新(增刪改)。如果我們要儲存的是城市列表呢?顯而易見,這個集合是一個檢視頻率很高,但寫入頻率很低的集合,那麼常用的操作就是查詢。
對於頻繁更新和頻繁查詢的集合,我們最需要關注的重點是他們的正規化化程度,在上篇正規化化與反正規化化的介紹中我們瞭解到,正規化化與反正規化化的合理運用對於效能的提高至關重要。然而這種設計的使用非常靈活,假設現在我們需要儲存一篇圖書及其作者,在MongoDB中的關聯就可以體現為以下幾種形式:
1.完全分離(正規化化設計)
示例1:
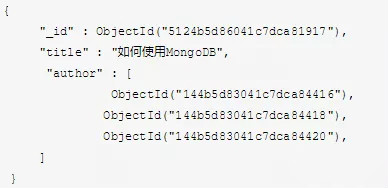
我們將作者(comment) 的id陣列作為一個欄位新增到了圖書中去。這樣的設計方式是在非關係型資料庫中常用的,也就是我們所說的正規化化設計。在MongoDB中我們將與主鍵沒有直接關係的圖書單獨提取到另一個集合,用儲存主鍵的方式進行關聯查詢。當我們要查詢文章和評論時需要先查詢到所需的文章,再從文章中獲取評論id,最後用獲得的完整的文章及其評論。在這種情況下查詢效能顯然是不理想的。但當某位作者的資訊需要修改時,正規化化的維護優勢就凸顯出來了,我們無需考慮此作者關聯的圖書,直接進行修改此作者的欄位即可。
2.完全內嵌(反正規化化設計)
示例2:

在這個示例中我們將作者的欄位完全嵌入到了圖書中去,在查詢的時候直接查詢圖書即可獲得所對應作者的全部資訊,但因一個作者可能有多本著作,當修改某位作者的資訊時時,我們需要遍歷所有圖書以找到該作者,將其修改。
3.部分內嵌(折中方案)
示例3:

這次我們將作者欄位中的最常用的一部分提取出來。當我們只需要獲得圖書和作者名時,無需再次進入作者集合進行查詢,僅在圖書集合查詢即可獲得。
這種方式是一種相對摺中的方式,既保證了查詢效率,也保證的更新效率。但這樣的方式顯然要比前兩種較難以掌握,難點在於需要與實際業務進行結合來尋找合適的提取欄位。如同示例3所述,名字顯然不是一個經常修改的欄位,這樣的欄位如果提取出來是沒問題的,但如果提取出來的欄位是一個經常修改的欄位(比如age)的話,我們依舊在更新這個欄位時需要大範圍的尋找並依此進行更新。
在上面三個示例中,第一個示例的更新效率是最高的,但查詢效率是最低的,而第二個示例的查詢效率最高,但更新效率最低。所以在實際的工作中我們需要根據自己實際的需要來設計表中的欄位,以獲得最高的效率。
2.理解填充因子:何為填充因子?
填充因子(padding factor)是MongoDB為文件的擴充套件而預留的增長空間,因為MongoDB的文件是以順序表的方式儲存的,每個文件之間會非常緊湊,如圖所示。
(注:圖片出處:《MongoDB The Definitive Guide》)

1.元素之間沒有多餘的可增長空間。

2.當我們對順序表中某個元素的大小進行增長的時候,就會導致原來分配的空間不足,只能要求其向後移動。

3.當修改元素移動後,後續插入的文件都會提供一定的填充因子,以便於文件頻繁的修改,如果沒有不再有文件因增大而移動的話,後續插入的文件的填充因子會依此減小。
填充因子的理解之所以重要,是因為文件的移動非常消耗效能,頻繁的移動會大大增加系統的負擔,在實際開發中最有可能會讓文件體積變大的因素是陣列,所以如果我們的文件會頻繁修改並增大空間的話,則一定要充分考慮填充因子。
那麼如果我們的文件是個常常會擴充套件的話,應該如何提高效能?
兩種方案
1.增加初始分配空間。在集合的屬性中包含一個 usePowerOf2Sizes 屬性,當這個選項為true時,系統會將後續插入的文件,初始空間都分配為2的N次方。
這種分配機制適用於一個數據會頻繁變更的集合使用,他會給每個文件留有更大的空間,但因此空間的分配不會像原來那樣高效,如果你的集合在更新時不會頻繁的出現移動現象,這種分配方式會導致寫入速度相對變慢。
2.我們可以利用資料強行將初始分配空間擴大。
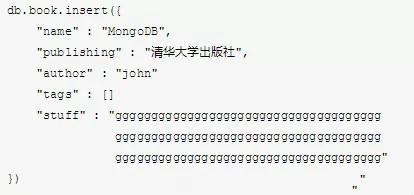
是的,這樣看起來可能不太優雅…但有時卻很有效!當我們對這個文件進行增長式修改時,只要將stuff欄位刪掉即可。當然,這個stuff欄位隨便你怎麼起名,包括裡邊的填充字元當然也是可以隨意新增的。
3.準確利用索引
索引對於一個數據庫的影響相信大家一定了解,如果一個查詢命令進入到資料庫中後,查詢優化器沒有找到合適的索引,那麼資料庫會進行全集合掃描(在RDBMS中也叫全表掃描),全集合查詢對於效能的影響是災難性的。沒有索引的查詢就如同在詞典那毫無規律的海量詞彙中獲得某個你想要的詞彙,但這個詞典是沒有目錄的,只能通過逐頁來查詢。這樣的查詢可能會讓你耗費幾個小時的時間,但如果要求你查詢詞彙的頻率如同使用者訪問的頻率一樣的話。。。嘿嘿,我相信你一定會大喊“老子不幹了!”。顯然計算機不會這樣喊,它一直是一個勤勤懇懇的員工,不論多麼苛刻的請求他都會完成。所以請通過索引善待你的計算機:D。
在MongoDB中索引的型別與RDBMS中大體一致,我們不做過多重複,我們來看一下在MongoDB中如何才能更高效的利用索引。
1.索引越少越好
索引可以極大地提高查詢效能,那麼索引是不是越多越好?答案是否定的,並且索引並非越多越好,而是越少越好。每當你建立一個索引時,系統會為你新增一個索引表,用於索引指定的列,然而當你對已建立索引的列進行插入或修改時,資料庫則需要對原來的索引表進行重新排序,重新排序的過程非常消耗效能,但應對少量的索引壓力並不是很大,但如果索引的數量較多的話對於效能的影響可想而知。所以在建立索引時需要謹慎建立索引,要把每個索引的功能都要發揮到極致,也就是說在可以滿足索引需求的情況下,索引的數量越少越好。
一. 隱式索引
//建立複合索引 db.test.ensureIndex( {“age”: 1,“no”: 1,“name”: 1 }) 我們在查詢時可以迅速的將age,no欄位進行排序,隱式索引指的是如果我們想要排序的欄位包含在已建立的複合索引中則無需重複建立索引。
db.test.find().sort(“age”: 1,“no”: 1) db.test.find().sort(“age”: 1) 如以上兩個排序查詢,均可使用上面的複合索引,而不需要重新建立索引。
二. 翻轉索引
//建立複合索引 db.test.ensureIndex({“age”: 1}) 翻轉索引很好理解,就是我們在排序查詢時無需考慮索引列的方向,例如這個例子中我們在查詢時可以將排序條件寫為"{‘age’: 0}",依舊不會影響效能。
2.索引列顆粒越小越好
什麼叫顆粒越小越好?在索引列中每個資料的重複數量稱為顆粒,也叫作索引的基數。如果資料的顆粒過大,索引就無法發揮該有的效能。例如,我們擁有一個"age"列索引,如果在"age"列中,20歲佔了50%,如果現在要查詢一個20歲,名叫"Tom"的人,我們則需要在表的50%的資料中查詢,索引的作用大大降低。所以,我們在建立索引時要儘量將資料顆粒小的列放在索引左側,以保證索引發揮最大的作用。
加Java架構師進階交流群獲取Java工程化、高效能及分散式、高效能、深入淺出。高架構。效能調優、Spring,MyBatis,Netty原始碼分析和大資料等多個知識點高階進階乾貨的直播免費學習許可權 都是大牛帶飛 讓你少走很多的彎路的 群號是:883922439 對了 小白勿進 最好是有開發經驗 注:加群要求
1、具有工作經驗的,面對目前流行的技術不知從何下手,需要突破技術瓶頸的可以加。
2、在公司待久了,過得很安逸,但跳槽時面試碰壁。需要在短時間內進修、跳槽拿高薪的可以加。
3、如果沒有工作經驗,但基礎非常紮實,對java工作機制,常用設計思想,常用java開發框架掌握熟練的,可以加。
4、覺得自己很牛B,一般需求都能搞定。但是所學的知識點沒有系統化,很難在技術領域繼續突破的可以加。
5.阿里Java高階大牛直播講解知識點,分享知識,多年工作經驗的梳理和總結,帶著大家全面、科學地建立自己的技術體系和技術認知!