
十四.Spark SQL總結之spark日誌檔案資料形式的轉換
阿新 • • 發佈:2018-12-19
第一步.資料來源
找到spark的日誌資料來源,在/root/spark/spark-2.0.2-bin-hadoop2.7/logs目錄下:
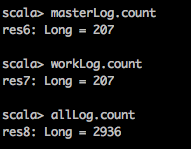
 通過對檔案的讀取,統計其中資料的條數:
通過對檔案的讀取,統計其中資料的條數:
val masterLog = sc.textFile("file:///root/spark/spark-2.0.2-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop000.out") val workLog = sc.textFile("file:///root/spark/spark-2.0.2-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop000.out") val allLog = sc.textFile("file:///root/spark/spark-2.0.2-bin-hadoop2.7/logs/*out*")
結果顯示:
第二步.將讀取的資料來源轉換成DataFrame
方式一(通過schema然後再轉DataFrame)
import org.apache.spark.sql.Row val masterRDD = masterLog.map(x => Row(x)) import org.apache.spark.sql.types._ val schemaString = "line" val fields = schemaString.split(" ").map(fieldName => StructField(fieldName,StringType,nullable = true)) val schema = StructType(fields) val masterDF = spark.createDataFrame(masterRDD,schema) masterDF.show
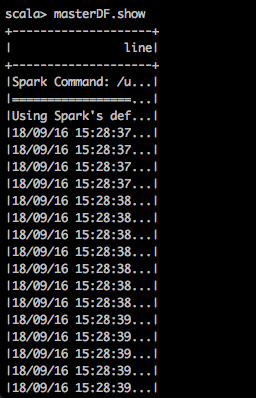
因為顯示的資料部分隱藏了,如果不想隱藏需要使用下面的命令進行顯示:
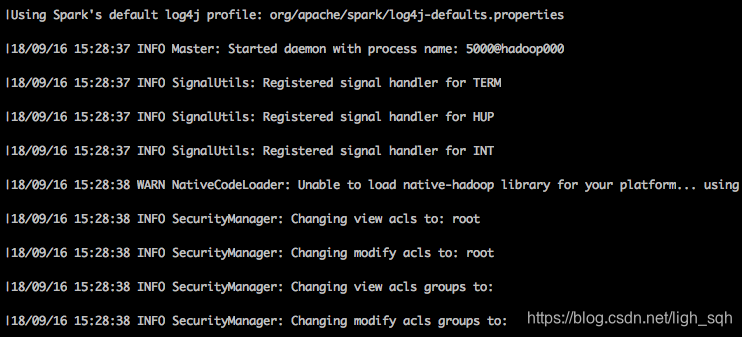
masterDF.show(false)
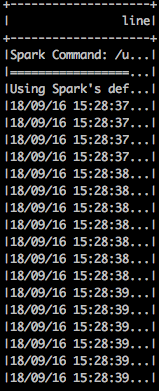
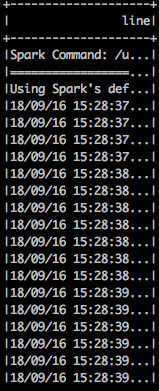
顯示的結果:
方式二(通過sql的方式獲取資料)
scala> masterDF.createOrReplaceTempView("master_logs")
scala> spark.sql("select * from master_logs limit 10").show(false)
顯示結果:
第三步.parquet格式的檔案轉換成DataFrame型別的資料
方式一.以讀取檔案的形式
val userDF = spark.read.format("parquet").load("file:///root/spark/spark-2.0.2-bin-hadoop2.7/examples/src/main/resources/users.parquet") userDF.show
方式二.以sql的形式讀取parquet型別的檔案
val userDF = spark.sql("select * from parquet.`file:///root/spark/spark-2.0.2-bin-hadoop2.7/examples/src/main/resources/users.parquet`")
userDF.show
第四步.拓展
- 讀取HDFS中的資料:
val hdfsDF = sc.textFile("hdfs://path/file路徑")
2)讀取正常的檔案:
val dataDF = spark.read.format("txt").load("檔案路徑")
以上就是關於讀取外部資料來源的各種形式…
每天的疲勞換來的是美好的未來,笑著面對每一天。