
YYCahe原始碼分析---總結(一)
花了幾天的時間看完了,ibireme大佬寫的YYCahe、以及其他大佬對YYCahe原始碼分析,在此記錄一下,自己看完的收穫。
網上有很多大佬分析了YYCahe 的原始碼,如何使用,每個類、函式之間的關係等,每個人的理解不太一樣,就看自己如何理解了,不再做過多的說明。
以下幾點,在很多原始碼分析中,只是簡單的指出了一下,或者是未有說明,自己覺得需要去理解,掌握的東西,寫給自己看的 : )
-
YYMemoryCache,中使用了LRU快取演算法,什麼是LRU?那麼LFU又是什麼?他們的區別是什麼?如何簡單的使用?什麼是快取檔案置換機制?
-
YYMemoryCache,中使用了雙鏈表處理記憶體中的,刪除、插入等操作,什麼是雙鏈表?為何不用單鏈表?
-
在移動端使用快取,包括了記憶體快取、硬碟快取、它們之間的區別是什麼、各有什麼優缺點?
-
YYMemoryCache中,使用互斥鎖來處理、查詢、刪除等操作,什麼是互斥鎖?有什麼作用?dispatch_semaphore、pthread_mutex_lock等區別在哪裡?
-
其他的一些以前沒有接觸到的知識點,什麼是行內函數? CFDictionary 和 nsdictionary 區別? CFDictionary 比 nsdictionary 效率更高.
-
一些巨集定義. #if __has_include(<sqlite3.h>) #import <sqlite3.h> #else #import “sqlite3.h” #endif
結構圖:

一、YYMemoryCache,中使用了LRU快取演算法,什麼是LRU?那麼LFU又是什麼?他們的區別是什麼?如何簡單的使用?什麼是快取檔案置換機制 YYMemoryCache中,使用快取淘汰演算法(LRU)、快取清理策略(分別是count(快取數量),cost(開銷),age(距上一次的訪問時間))。
1.LRU 全稱是Least Recently Used,即最近最久未使用的意思. 如果一個數據在最近一段時間沒有被訪問到,那麼在將來它被訪問的可能性也很小。也就是說,當限定的空間已存滿資料時,應當把最久沒有被訪問到的資料淘汰. 如果使用陣列來儲存資料,給每個資料項標記一個時間戳,每次插入、刪除時,需要把陣列中存在的資料項的時間戳自增、或自減;插入新資料則需要把時間戳設定為0. 當空間已滿,則將時間戳最大的資料項淘汰掉;缺點,需要不停的維護資料項的訪問時間戳。
更好的的辦法就是,利用連結串列移動訪問時間的資料順序和hashmap查詢是否是新資料項。
1.1 演算法流程 新資料插入到連結串列頭部; 每當快取命中(即快取資料被訪問),則將資料移到連結串列頭部; 當連結串列滿的時候,將連結串列尾部的資料丟棄。 例如: 比如有資料 1,2,1,3,2 此時快取中已有(1,2) 當3加入的時候,得把後面的2淘汰,變成(3,1)
2.LFU LFU(Least Frequently Used)最近最少使用演算法。它是基於“如果一個數據在最近一段時間內使用次數很少,那麼在將來一段時間內被使用的可能性也很小”的思路。
2.1 新加入資料插入到佇列尾部(因為引用計數為1); 佇列中的資料被訪問後,引用計數增加,佇列重新排序; 當需要淘汰資料時,將已經排序的列表最後的資料塊刪除。 例如 比如有資料 1,1,1,2,2,3 快取中有(1(3次),2(2次)) 當3加入的時候,得把後面的2淘汰,變成(1(3次),3(1次)) 區別:LRU 是得把 1 淘汰。
3.LRU與LFU 對比: 名詞解釋: 快取汙染指作業系統將不常用的資料,從記憶體移到快取,降低了快取效率的現象
注意LFU和LRU演算法的不同之處,LRU的淘汰規則是基於訪問時間,而LFU是基於訪問次數的
命中率: LFU: 一般情況下,LFU效率要優於LRU,且能夠避免週期性或者偶發性的操作導致快取命中率下降的問題。但LFU需要記錄資料的歷史訪問記錄,一旦資料訪問模式改變,LFU需要更長時間來適用新的訪問模式,即:LFU存在歷史資料影響將來資料的“快取汙染”效用 LRU: 當存在熱點資料時,LRU的效率很好,但偶發性的、週期性的批量操作會導致LRU命中率急劇下降,快取汙染情況比較嚴重
複雜度: LFU: 需要維護一個佇列記錄所有資料的訪問記錄,每個資料都需要維護引用計數 LRU:實現簡單
代價: LFU: 需要記錄所有資料的訪問記錄,記憶體消耗較高;需要基於引用計數排序,效能消耗較高 LRU:命中時需要遍歷連結串列,找到命中的資料塊索引,然後需要將資料移到頭部
4.什麼是快取檔案置換機制? 是計算機處理快取儲存器的一種機制。 計算機儲存器空間的大小固定,無法容納伺服器上所有的檔案,所以當有新的檔案要被置換入快取時,必須根據一定的原則來取代掉適當的檔案。此原則即所謂快取檔案置換機制
快取檔案置換方法有: 先進先出演算法(FIFO): 最先進入的內容作為替換物件 最近最少使用演算法(LFU): 最近最少使用的內容作為替換物件 最久未使用演算法(LRU): 最久沒有訪問的內容作為替換物件 非最近使用演算法(NMRU):在最近沒有使用的內容中隨機選擇一個作為替換物件
二、什麼是雙鏈表、單鏈表?
雙向連結串列也叫雙鏈表,是連結串列的一種,它的每個資料結點中都有兩個指標,分別指向直接後繼和直接前驅。所以,從雙向連結串列中的任意一個結點開始,都可以很方便地訪問它的前驅結點和後繼結點
刪除:
單向連結串列(單鏈表)是連結串列的一種,其特點是連結串列的連結方向是單向的,對連結串列的訪問要通過順序讀取從頭部開始;連結串列是使用指標進行構造的列表;又稱為結點列表,因為連結串列是由一個個結點組裝起來的;其中每個結點都有指標成員變數指向列表中的下一個結點
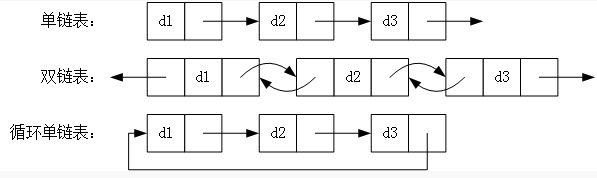
列表是由結點構成,head指標指向第一個成為表頭結點,而終止於最後一個指向nuLL的指標
-
雙向連結串列與單向連結串列相比有以下優勢: 插入刪除不需要移動元素外,可以原地插入刪除 可以雙向遍歷 儲存效率 儲存結構來看,每個雙鏈表的節點要比單鏈表的節點多一個指標,而長度為n就需要 n*length(這個指標的length在32位系統中是4位元組,在64位系統中是8個位元組) 的空間,這在一些追求時間效率不高應用下並不適應,因為它佔用空間大於單鏈表所佔用的空間;這時設計者就會採用以時間換空間的做法,這時一種工程總體上的衡量
-
連結串列跟陣列的區別? 陣列靜態分配記憶體,連結串列動態分配記憶體; 陣列在記憶體中連續,連結串列不連續; 陣列利用下標定位,時間複雜度為O(1),連結串列定位元素時間複雜度O(n); 陣列插入或刪除元素的時間複雜度O(n),連結串列的時間複雜度O(1)
優點: 陣列: 隨機訪問性強(通過下標進行快速定位) 查詢速度快
連結串列: 插入刪除速度快(因為有next指標指向其下一個節點,通過改變指標的指向可以方便的增加刪除元素) 記憶體利用率高,不會浪費記憶體(可以使用記憶體中細小的不連續空間(大於node節點的大小),並且在需要空間的時候才建立空間) 大小沒有固定,拓展很靈活
缺點: 陣列 插入和刪除效率低(插入和刪除需要移動資料) 可能浪費記憶體(因為是連續的,所以每次申請陣列之前必須規定陣列的大小,如果大小不合理,則可能會浪費記憶體) 記憶體空間要求高,必須有足夠的連續記憶體空間。 陣列大小固定,不能動態拓展
連結串列 不能隨機查詢,必須從第一個開始遍歷,查詢效率